SQL Server 2012:SQL Server体系结构——一个查询的生命周期(第2部分)
计划缓存(Plan Cache)
如果SQL Server已经找到一个好的方式去执行一段代码时,应该把它作为随后的请求重用,因为生成执行计划是耗费时间且资源密集的,这样做是有有意义的。
如果没找到被缓存的计划,然后命令分析器(Command Parser)在T-SQL基础上生成一个查询树(query tree)。查询树(query tree)的内部结构是通过树上的每个结点代表查询中需要的执行操作。这个树然后被传给查询优化器(Query Optimizer)去处理。我们的简单查询没有一个存在的计划,因此一个查询树(query tree)会被创建,然后传给查询优化器(Query Optimizer)。
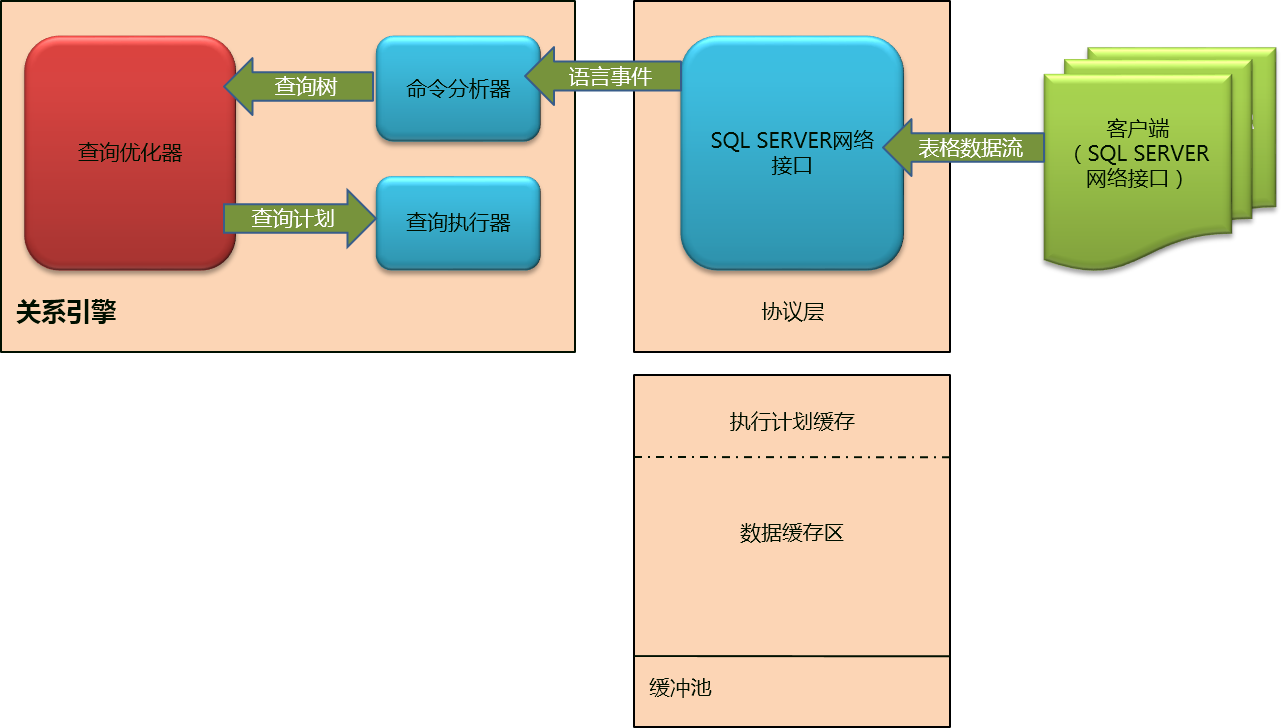
上图展示了命令分析器(Command Parser)是用来检查现存执行计划的计划缓存(plan cache),因为在缓存里没找到我们查询的任何信息,还有从命令分析器(Command Parser)输出传给优化器的查询树(query tree)。
查询优化器(Query Optimizer)是被SQL Server团队视为最有价值的财产,也是产品中最复杂、机密的部分之一。幸运的是,只有底层的算法和源代码被很好保护(即使在微软内部),优化器如何工作才能被研究和监视。
这个所谓的基于成本(cost-based)的优化器,意味要去评估执行查询的各种方式,然后选择被认为拥有最小成本的方式去执行。执行方式以查询计划(query plan)实现并从查询优化器(Query Optimizer)输出。
基于刚才的介绍,你认为优化器的工作是找到最好的查询计划会被原谅的,因为那看起来是很明显的设想。然而它的实际工作是在一段时间内找到好的计划,而不是最佳计划。优化器的目标通常被描述为找最有效率的计划。
如果优化器每次都尝试去找最好的计划,比起执行一个慢的计划,找个最好的计划花费的时间更长(一些内建的试探法实际上在保证优化器从不花更长的时间找到好计划,而是就找一个计划并执行它)。
优化器同样在成本的基础执行多级优化,在每一阶段增加更多可用选择项来找更好的计划。当一个好计划被找到时,优化器就停在那一阶段了。
第1阶段被称之为预优化,当语句是足够简单而只有一个最佳计划时,在第一阶段就退出剩下的步骤,移除额外成本需要。没有join的基本查询被认为简单,计划成本产出为0,然后被提及为普通计划(trivial plans)。
优化实际上开始的下一阶段包含三个查找时期:
- 第0时期——这个时期优化器会找内循环连接(nested loop joins)且不考虑并行运算符(parallel operators)。
如果已经找到的计划成本小于0.2,优化器会停在这里。在这个阶段生成的计划称为事务处理(transaction processing)或简称TP计划。
- 第1时期——第1时期使用可用优化规则的子集来找常用格式(common patterns)的已有计划。
如果已经知道的计划成本小于1.0,优化器会停在这里。这个阶段生成的计划被称为快速计划(quick plans)。
- 第2时期——在这个最后时期优化器全力以赴(pulls out all the stops)使用它所有的优化规则。它同样也会找下并行(parallelism)和索引视图(indexed views)(如果你运行的是企业版(Enterprise Edition))。
第2时期的完成是找到计划的成本对优化需要的时间之间的平衡。在这个时期生成的计划有完全级别(level of "Full")的优化。
它的花费需要多少?
这里提及的花费不能用多少秒或其他有意义的表达来衡量;它只是标记代表计划资源消耗值的一个任意数。然而,在早期的微软SQL Server世界里,它的起源是在桌面电脑上的基准检查程序(benchmark)(跑分)。
在计划里,每个运算符都有一个底线成本,然后用它来乘以行的大小和预计行数来获得那个运算符的成本,计划成本就是这些所有运算符的成本。
因为成本来自于底线值且与你的硬件速度无关,在每个SQL Server装置(同比版本 like-for-like version。博主注:与版本无关。)里生成每个计划的成本是一样的。
因为我们的SELECT查询非常简单,它退出在预优化时期的操作,因为这个计划对优化器非常明显(一个普通计划)。现在已经有查询计划了,它向查询执行器(Query Executor)去执行。
查询执行器(Query Executor)
查询执行器的工作是不释自明的,它执行查询。更准确的说,它通过干完包含与存储引擎相互作用的检索或修改数据的每一步来执行查询。
(此处有信息需要完善…………)
这个SELECT查询需要检索数据,因此请求传给存储引擎(Storage Engine)通过OLE DB接口传给存取方法(Access Methods)。
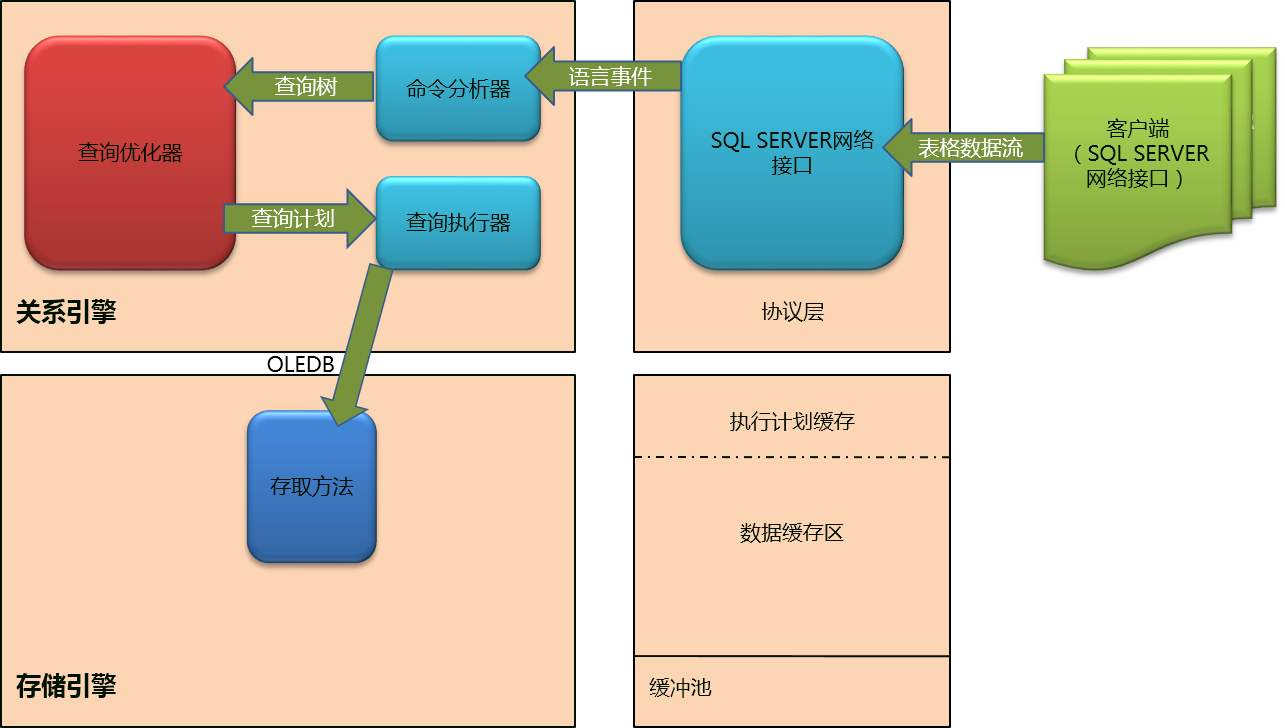
上图展示了作为优化器的输出的执行计划(query plan)正传给查询执行器(Query Executor),同时引入了存储引擎(Storage Engine),它被查询执行器(Query Executor)通过OLE作为接口给存取方法(Access Methods)。
存取方法(Access Methods)
存取方法是为你数据和索引提供存储结构,还有通过数据检索或数据修改接口的一批代码。它包含检索数据的所有代码单本身不执行操作,它向缓存区管理器(Buffer Manager)传递请求。
假设我们的SELECT语句需要读取一些记录行的数据刚好在一页。存取方法(Access Methods)的代码会让缓存区管理器(Buffer Manager)检索页,因此它可以准备一个OLE DB的记录集传回给关系引擎(Relational Engine)。
缓存区管理器(Buffer Manager)
缓存区管理器(Buffer Manager),如名所示,管理缓冲池(buffer pool),它代表着SQL Server的主要内存使用。如果你需要从页读一些记录行(当我们谈论UPDATE查询时会提及修改数据),缓存区管理器(Buffer Manager)在缓冲池(buffer pool)检查数据缓存看看在内存里是否有被缓存的这页。如果这页已被缓存了,结果就会传回给存取方法(Access Methods)。
如果这页没被缓存,然后缓存区管理器(Buffer Manager)从磁盘里拿这页,把它放入数据缓存(Data Cache),然后把结果传回给存取方法(Access Methods)。
你这里要记住的要点是你永远只和内存中的数据打交道。在作为记录集返回前,你请求的每个新的数据读取,首先从磁盘读取,然后写回内存(数据缓存(the data cache))。
这就是为什么SQL Server需要在内存里保持最小级别的可用页面;如果第一时间在缓存里没有空间来放数据,你就不能读取任何新数据。
存取方法(Access Methods)代码决定SELECT查询需要一个新页,因此它向缓存区管理器(Buffer Manager)拿。缓存区管理器(Buffer Manager)检查它是否已在数据缓存(data cache),如果没找到的话就从磁盘加载到缓存。
数据缓存(Data Cache)
数据缓存一直是缓冲池(buffer pool)最大一部分;因此也是在SQL Server最大内存用户。这里每个从磁盘读取的数据页在被用之前都会被写回。
这个sys.dm_os_buffer_descriptors动态管理视图(DMV)每一行代表当前内存持有的每个数据页,你可以用这个脚本看看在数据缓存区(Data Cache)每个数据库占用多少空间:
SELECT count(*)*8/1024 AS 'Cached Size (MB)'
,CASE database_id
WHEN 32767 THEN 'ResourceDb'
ELSE db_name(database_id)
END AS 'Database'
FROM sys.dm_os_buffer_descriptors
GROUP BY db_name(database_id),database_id
ORDER BY 'Cached Size (MB)' DESC
输出结果看起来会类似如下:
Cached Size (MB) Database
3287 People
34 tempdb
12 ResourceDb
4 msdb
这个例子里,People数据库在数据缓存(Data Cache)里有3287 MB数据页。
页在缓存里停留时间量由最近最少使用(least recently used:LRU)策略决定。
(此处有信息待完善………………)
一个简单SELECT语句(查询)生命周期总结

SELECT查询的整个生命周期在这里被介绍:
- 在客户端的SQL Server网络接口(SNI)与在SQL Server使用例如TCP/IP的网络协议的网络接口(SNI)建立连接。然后在TCP/IP连接上建立与TDS终结点的联系并发送SELECT语句作为TDS消息发送给SQL Server。
- 在SQL Server上的SNI把TDS消息拆包,读取SELECT语句,传送一个“SQL命令”给命令分析器。
- 命令分析器在缓冲池检查计划缓存是否存在,与语句匹配的可用查询计划被命令分析器接收。如果没有找到它,基于SELECT语句创建查询树传给优化器来生成查询计划。
- 优化器在预编译生成零成本计划或普通计划,因为这个语句太简单了。生成的查询计划然后传给查询执行器去执行。
- 在执行时,查询执行器决定读取需要的数据来完整这个查询计划,因此通过OLE DB接口把请求传给在存储引擎里的存取方法。
- 存取方法需要从数据库里读一个页来完成来自查询执行器的请求,它让缓存区管理器来提供这个页。
- 缓存区管理器检查数据缓存看看它在缓存里是否已有。它不在缓存,因此从磁盘里拿这个页,放入缓存,传回给存取方法。
- 最后,存取方法把结果集送回给关系引擎发回给客户端。
参考文章:
SQL Server 2012:SQL Server体系结构——一个查询的生命周期(第2部分)的更多相关文章
- SQL Server 2012:SQL Server体系结构——一个查询的生命周期(第3部分)(完结)
一个简单的更新查询 现在应该知道只读取数据的查询生命周期,下一步来认定当你需要更新数据时会发生什么.这个部分通过看一个简单的UPDATE查询,修改刚才例子里读取的数据,来回答. 庆幸的是,直到存取方法 ...
- SQL Server 2012:SQL Server体系结构——一个查询的生命周期(第1部分)
为了缩小读取操作所涉及范围,本文首先着眼于简单的SELECT查询,然后引入执行更新操作有关的附加过程.最后你会读到,优化性能时SQLServer使用还原工具的相关术语和流程. 关系和存储引擎 如图所示 ...
- SQLSERVER 免费对比数据库结构和数据的工具支持:SQL Server 2012, SQL Server 2008 and SQL Server 2005
New xSQL Schema Compare - version 5 Compare the schemas of two SQL Server databases, review differen ...
- [oldboy-django][2深入django]django一个请求的生命周期 + WSGI + 中间件
1 WSGI # WSGI(是一套协议,很多东西比如wsgiref, uwsgiref遵循这一套协议) - django系统本质 别人的socket(wsgiref或者uwsgiref) + djan ...
- (四)一个bug的生命周期
Bug的属性 Bug重现环境 这个应该是我们重现BUG的一个前提,如果没有这个前提,我们可能会无法重现问题,或者根本就无从下手. • 操作系统 这个是一般软件运行的一大前提,基本上所有的软件都依赖于操 ...
- SQL Server 2012 - SQL查询
执行计划显示SQL执行的开销 工具→ SQL Server Profiler : SQL Server 分析器,监视系统调用的SQL Server查询 Top查询 -- Top Percent 选择百 ...
- windows server 2012 + sql server 2008 r2安装
windows server 2012 r2 里面安装 sql server 2008 r2 问题总结 前提是 windows server 2012 r2 已经安装完成 ,(仅仅是安装完成 啥服 ...
- JVM学习笔记:JVM的体系结构与JVM的生命周期
1 JVM在java平台中的位置 1.1 Java平台组成 Java平台主要由Java虚拟机和Java API这两部分组成.参考Oracle官网. 1.2 java平台结构图 JDK1.2开始,迫于J ...
- JAVA虚拟机体系结构JAVA虚拟机的生命周期
一个运行时的Java虚拟机实例的天职是:负责运行一个java程序.当启动一个Java程序时,一个虚拟机实例也就诞生了.当该程序关闭退出,这个虚拟机实例也就随之消亡.如果同一台计算机上同时运行三个Jav ...
随机推荐
- Linear or non-linear shadow maps?
Quote: Original post by RobMaddisonI understand that, for aliasing mitigation, it might be beneficia ...
- kindle 贴膜
我自己贴膜也贴得很好.顺便和大家分享一下我的贴膜经验.需要的道具,一.抹布,二.一张银行卡,三.一卷小筒的透明胶.贴膜关键点,一.环境和贴面必须干净,二.用力要轻,三.顺序是从上往下.具体步骤:1.先 ...
- Oracle 11g 的官方支持周期和时限
Oracle公司对于自身产品的支持策略大多数人很难搞清楚,对于Oracle Database 11g的支持周期,有很多朋友产生了异议,参考下文提到的一些文件,希望可以帮助大家理解Oracle的产品支持 ...
- Unity3D Shader入门指南(二)
关于本系列 这是Unity3D Shader入门指南系列的第二篇,本系列面向的对象是新接触Shader开发的Unity3D使用者,因为我本身自己也是Shader初学者,因此可能会存在错误或者疏漏,如果 ...
- AngularJS datepicker 和 datatimepicker
本文内容 项目结构 AngularJS datepicker AngularJS+jQueryUI datetimepicker 本文介绍 AngualrJS datetimepicker 控件.说明 ...
- Navi.Soft30.产品.代码生成器.操作手册
1系统简介 1.1功能简述 在Net软件开发过程中,大部分时间都是在编写代码,并且都是重复和冗杂的代码.比如:要实现在数据库中10个表的增删改查功能,大部分代码都是相同的,只需修改10%的代码量.此时 ...
- Step by step Process of creating APD
Step by step Process of creating APD: Business Scenario: Here we are going to create an APD on top o ...
- 基于Bootstrap的后台通用模板
人总是比较刁的,世界的时尚趋势不断变化,对系统UI的审美也在不断疲劳中前进,之前觉得好好的UI,过了半年觉得平平无奇,不想再碰,需要寻求新的兴奋点. 下面这套UI就是半年前的(今日:2015-12), ...
- css 单位转换
如今 css 的单位越来越多了,px, em, rem, 微信的小程序又出来个 rpx 可以用 less 自动生成需要的单位 但当你只是想把一个已有的页面转换成小程序时,可能更需要一个 px -> ...
- sql读取xml
DECLARE @ItemMessage XML SET @ItemMessage=cast(N'<?xml version="1.0" encoding="utf ...