Memcache笔记04-Memcached机制深入了解
Memcached机制深入了解
①基于c/s架构 ,协议简单
- c/s架构,此时memcached为服务器端,我们可以使用如PHP,c/c++等程序连接memcached服务器。
- memcached的服务器客户端通信并不使用XML等格式,而使用简单的基于文本行的协议。因此,通过telnet也能在memcached上保存数据、取得数据
②基于libevent的事件处理
- libevent是一套跨平台的事件处理接口的封装,能够兼容包括这些操作系统:Windows/Linux/BSD/Solaris 等操作系统的的事件处理。
- memcached事件处理并发是基于libevent机制(memcached使用libevent来进行网络并发连接的处理,能够保持在最大并发连接下,仍旧能够保持快速的响应能力)。
③内置内存存储方式
- 为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重启memcached、重启操作系统会导致全部数据消失。另外,内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。memcached本身是为缓存而设计的服务器,因此并没有过多考虑数据的永久性问题。
④基于客户端的分布式
- memcached虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能。各个memcached不会互相通信以共享信息。memcached的分布式,则是完全由客户端程序库实现的。这种分布式是memcached的最大特点。
Memcached分布式原理:
下面假设memcached服务器有node1~node3三台,应用程序要保存键名为“tokyo”、“kanagawa”、“chiba”、“saitama”、“gunma”的数据。

图4.1:分布式简介:准备
首先向memcached中添加“tokyo”。将“tokyo”传给客户端程序库后,客户端实现的算法就会根据“键”来决定保存数据的memcached服务器。服务器选定后,即命令它保存“tokyo”及其值。
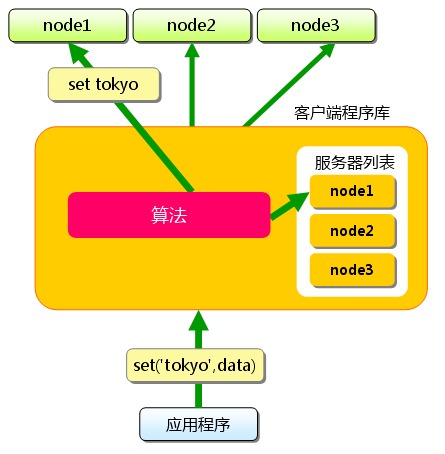
图4.2:分布式简介:添加时
同样,“kanagawa”、“chiba”、“saitama”、“gunma”都是先选择服务器再保存。接下来获取保存的数据。获取时也要将要获取的键“tokyo”传递给函数库。函数库通过与数据保存
时相同的算法,根据“键”选择服务器。使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令。只要数据没有因为某些原因被删除,就能获得保存的值。
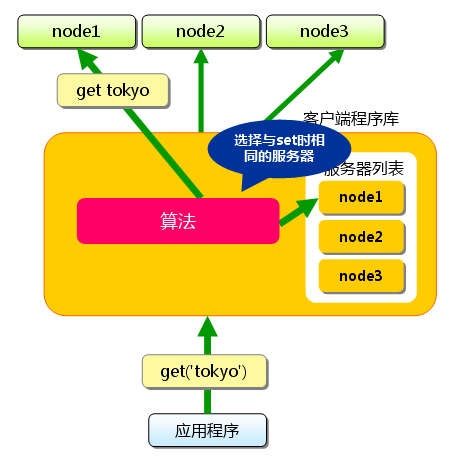
图4.3:分布式简介:获取时
这样,将不同的键保存到不同的服务器上,就实现了memcached的分布式。memcached服务器增多后,键就会分散,即使一台memcached服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行。
Memcached分布式实现方法:
(1)根据余数计算分散
这里以Perl客户端函数库Cache::Memcached实现的分布式方法来说明。
Cache::Memcached的分布式方法简单来说,就是“根据服务器台数的余数进行分散”。求得键的整数哈希值,再除以服务器台数,根据其余数来选择服务器。
下面将Cache::Memcached简化成以下的Perl脚本来进行说明。
use strict;
use warnings;
use String::CRC32;
my @nodes = ('node1','node2','node3');
my @keys = ('tokyo', 'kanagawa', 'chiba', 'saitama', 'gunma');
foreach my $key (@keys) {
my $crc = crc32($key); # CRC値
my $mod = $crc % ( $#nodes + 1 );
my $server = $nodes[ $mod ]; # 根据余数选择服务器
printf "%s => %s\n", $key, $server;
}
Cache::Memcached在求哈希值时使用了CRC。首先求得字符串的CRC值,根据该值除以服务器节点数目得到的余数决定服务器。上面的代码执行后输入以下结果:
tokyo => node2
kanagawa => node3
chiba => node2
saitama => node1
gunma => node1
根据该结果,“tokyo”分散到node2,“kanagawa”分散到node3等。多说一句,当选择的服务器无法连接时,Cache::Memcached会将连接次数添加到键之后,再次计算哈希值并尝试连接。这个动作称为rehash。不希望rehash时可以在生成Cache::Memcached对象时指定“rehash => 0”选项。
根据余数计算分散的缺点
余数计算的方法简单,数据的分散性也相当优秀,但也有其缺点。那就是当添加或移除服务器时,缓存重组的代价相当巨大。添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器,从而影响缓存的命中率。
用Perl写段代码来验证其代价。
use strict;
use warnings;
use String::CRC32;
my @nodes = @ARGV;
my @keys = ('a'..'z');
my %nodes;
foreach my $key ( @keys ) {
my $hash = crc32($key);
my $mod = $hash % ( $#nodes + 1 );
my $server = $nodes[ $mod ];
push @{ $nodes{ $server } }, $key;
}
foreach my $node ( sort keys %nodes ) {
printf "%s: %s\n", $node, join ",", @{ $nodes{$node} };
}
这段Perl脚本演示了将“a”到“z”的键保存到memcached并访问的情况。将其保存为mod.pl并执行。
首先,当服务器只有三台时:
$ mod.pl node1 node2 nod3
node1: a,c,d,e,h,j,n,u,w,x
node2: g,i,k,l,p,r,s,y
node3: b,f,m,o,q,t,v,z
结果如上,node1保存a、c、d、e……,node2保存g、i、k……,每台服务器都保存了8个到10个
数据。
接下来增加一台memcached服务器。
$ mod.pl node1 node2 node3 node4
node1: d,f,m,o,t,v
node2: b,i,k,p,r,y
node3: e,g,l,n,u,w
node4: a,c,h,j,q,s,x,z
添加了node4。可见,只有d、i、k、p、r、y命中了。像这样,添加节点后键分散到的服务器会发生巨大变化。26个键中只有六个在访问原来的服务器,其他的全都移到了其他服务器。命中率降低到23%。在Web应用程序中使用memcached时,在添加memcached服务器的瞬间缓存效率会大幅度下降,负载会集中到数据库服务器上,有可能会发生无法提供正常服务的情况。
(2)一致性hash算法(Consistent Hashing):
为了解决上面的问题,有人提出了新的分布式算法,从而可以轻而易举地添加memcached服务器了。
Consistent Hashing如下所示:首先求出memcached服务器(节点)的哈希值,并将其配置到0~232的圆(continuum)上。然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。
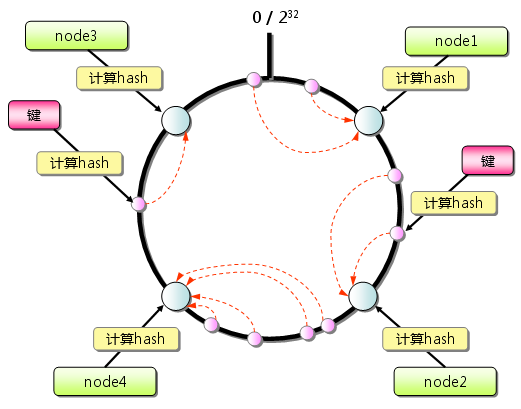
图4.4:Consistent Hashing:基本原理
从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Hashing中,只有在continuum上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响。
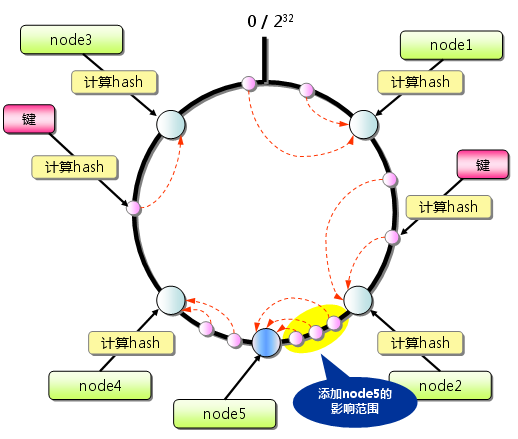
图4.5:Consistent Hashing:添加服务器
因此,Consistent Hashing最大限度地抑制了键的重新分布。而且,有的Consistent Hashing的实现方法还采用了虚拟节点的思想。使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。因此,使用虚拟节点的思想,为每个物理节点(服务器)在continuum上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
通过下文中介绍的使用Consistent Hashing算法的memcached客户端函数库进行测试的结果是,由服务器台数(n)和增加的服务器台数(m)计算增加服务器后的命中率计算公式如下:(1-n/(n+m)) * 100。
总结:
本次介绍了memcached的分布式算法,主要有memcached的分布式是由客户端函数库实现,以及高效率地分散数据的Consistent Hashing算法。
Memcache笔记04-Memcached机制深入了解的更多相关文章
- Memcache 笔记(2)
一.Memcache概述出现的原因:随着数据量的增大,访问的集中,使得数据库服务器的负担加重,数据库响应恶化,网站显示延迟等 memcache:是高性能的分布式内存缓存服务器.通过缓存数据库的查询结果 ...
- Mongodb源代码阅读笔记:Journal机制
Mongodb源代码阅读笔记:Journal机制 Mongodb源代码阅读笔记:Journal机制 涉及的文件 一些说明 PREPLOGBUFFER WRITETOJOURNAL WRITETODAT ...
- java学习笔记09--反射机制
java学习笔记09--反射机制 什么是反射: 反射是java语言的一个特性,它允许程序在运行时来进行自我检查并且对内部的成员进行操作.例如它允许一个java的类获取他所有的成员变量和方法并且显示出来 ...
- Storm学习笔记 - 消息容错机制
Storm学习笔记 - 消息容错机制 文章来自「随笔」 http://jsynk.cn/blog/articles/153.html 1. Storm消息容错机制概念 一个提供了可靠的处理机制的spo ...
- JS自学笔记04
JS自学笔记04 arguments[索引] 实参的值 1.对象 1)创建对象 ①调用系统的构造函数创建对象 var obj=new Object(); //添加属性.对象.名字=值; obj.nam ...
- JAVA自学笔记04
JAVA自学笔记04 1.switch语句 1)格式:switch(表达式){ case 值1: 语句体1; break; case 值2: 语句体2; break; - default: 语句体n+ ...
- 机器学习实战(Machine Learning in Action)学习笔记————04.朴素贝叶斯分类(bayes)
机器学习实战(Machine Learning in Action)学习笔记————04.朴素贝叶斯分类(bayes) 关键字:朴素贝叶斯.python.源码解析作者:米仓山下时间:2018-10-2 ...
- CS229 笔记04
CS229 笔记04 Logistic Regression Newton's Method 根据之前的讨论,在Logistic Regression中的一些符号有: \[ \begin{eqnarr ...
- php中memcache扩展及memcached扩展的区别
1.目前大多数php环境里使用的都是不带d的memcache版本,这个版本出的比较早,是一个原生版本,完全在php框架内开发的.与之对应的带d的memcached是建立在libmemcached的基础 ...
随机推荐
- Java 常用字符串操作总结
1. String转ASCII码 public static String stringToAscii(String value) { StringBuffer sbu = new StringBuf ...
- mysqldump命令的常用组合
只导表结构完整语句: mysqldump -h192.168.1.174 --port=3306 -uroot -p --routines --events --no-data --no-cre ...
- 一个关于explain出来为all的说明及优化
explain sql语句一个语句,得到如下结果,为什么已经创建了t_bill_invests.bid_id的索引,但却没有显示using index,而是显示all扫描方式呢,原来这还与select ...
- 三分 --- CSU 1548: Design road
Design road Problem's Link: http://acm.csu.edu.cn/OnlineJudge/problem.php?id=1548 Mean: 目的:从(0,0)到 ...
- 译:在ASP.NET MVC5中如何使用Apache log4net 类库来记录日志
译文出处:http://www.codeproject.com/Articles/823247/How-to-use-Apache-log-net-library-with-ASP-NET-MVC 在 ...
- 在GridView列表中使用图片显示记录是否包含附件
在我的前面很多文章中,都介绍过通用附件模块的管理,本篇随笔主要介绍在一些应用模块中的列表展示中,包含附件的记录,在GridView列表界面中使用图标来快速显示是否有附件的情况. 1.通用附件模块的应用 ...
- private、 protected、 public、 internal 修饰符
private : 私有成员, 在类的内部才可以访问. protected : 保护成员,该类内部和继承类中可以访问. public : 公共成员,完全公开,没有访问限制. internal: 在同一 ...
- 重新想象 Windows 8 Store Apps (62) - 通信: Socket TCP, Socket UDP
[源码下载] 重新想象 Windows 8 Store Apps (62) - 通信: Socket TCP, Socket UDP 作者:webabcd 介绍重新想象 Windows 8 Store ...
- 序列中找子序列的dp
题目网址: http://codeforces.com/problemset/problem/414/B Description Mashmokh's boss, Bimokh, didn't lik ...
- ArrayList集合
//在使用ArrayList时别忘了引用命名空间 using System.Collections;//首先得导入命名空间 //01.添加方法 add方法 //告诉内存,我要存储内容 ArrayLis ...