一个简单的python爬虫,以豆瓣妹子“http://www.dbmeizi.com/category/2?p= ”为例
本想抓取网易摄影上的图,但发现查看html源代码时找不到图片的url,但firebug却能定位得到。(不知道为什么???)
目标是抓取前50页的爆乳图,代码如下:
import urllib2,urllib,re,os
'''
http://www.dbmeizi.com/category/2?p=%
'''
def get_url_from_douban():
url_list=[]
p=re.compile(r'''<img.*?src="(.+?\.jpg)''') #找出发布人的标题和url
for i in range(1,50):
target = r"http://www.dbmeizi.com/category/2?p=%d"%i
# print target
req=urllib2.urlopen(target)
result=req.read()
matchs=p.findall(result)
url_list.extend(matchs)
# print matchs
# print "-----"*40
return url_list
def download_pic(url_list):
# print url_lists
count=0
if not os.path.exists('/tmp/pic'):
os.mkdir('/tmp/pic/')
for url in url_list:
urllib.urlretrieve(url,'/tmp/pic/'+str(count)+'.jpg')
count+=1 if __name__=='__main__':
# start_time=time.time()
print "start getting url..."
url_lists=get_url_from_douban()
print "url getted! downloading..."
download_pic(url_lists)
print "download finish!!!"
# cost_time=time.time() - start_time()
# print cost_time
# download_pic(url_lists) ------------------------------------------------------------------------------
/System/Library/Frameworks/Python.framework/Versions/2.7/bin/python /Users/lsf/PycharmProjects/some_subject/get_doubanmeizi_pic.py
start getting url...
url getted! downloading...
download finish!!!
Process finished with exit code 0
运行结果如图:
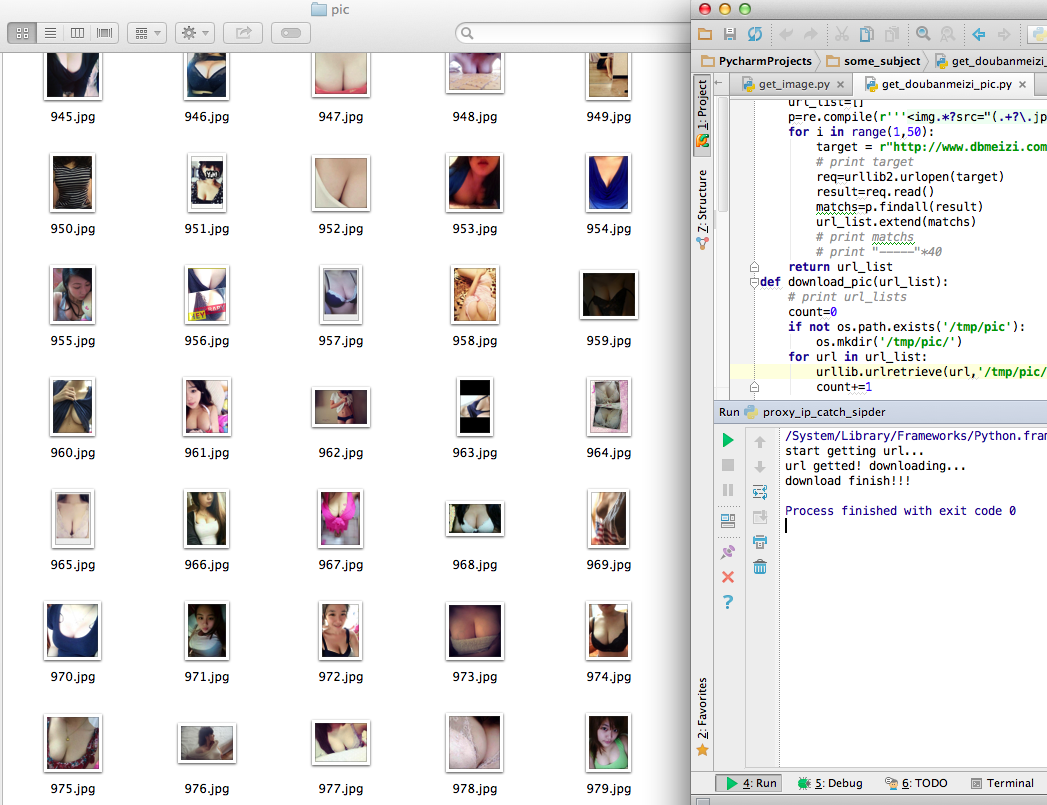
只是一个简单的实现方式,没有考虑性能,速度挺慢的。
ps:贴图会不会被查水表!!??
一个简单的python爬虫,以豆瓣妹子“http://www.dbmeizi.com/category/2?p= ”为例的更多相关文章
- 一个简单的python爬虫程序
python|网络爬虫 概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- 【Python学习笔记三】一个简单的python爬虫
这里写爬虫用的requests插件 1.一般那3.x版本的python安装后都带有相应的安装文件,目录在python安装目录的Scripts中,如下: 2.将scripts的目录配置到环境变量pa ...
- 一个简单的python爬虫(转)
# -*- coding: utf-8 -*- #--------------------------------------- # 程序:百度贴吧爬虫 # 版本:0.1 # 作者:why # 日期: ...
- 一个简单的Python爬虫
写了一个抓taobao图片的爬虫,全是用if,for,while写的,比较简陋,入门作品. 从网页http://mm.taobao.com/json/request_top_list.htm?type ...
- python实现的一个简单的网页爬虫
学习了下python,看了一个简单的网页爬虫:http://www.cnblogs.com/fnng/p/3576154.html 自己实现了一个简单的网页爬虫,获取豆瓣的最新电影信息. 爬虫主要是获 ...
- Python爬虫(四)——豆瓣数据模型训练与检测
前文参考: Python爬虫(一)——豆瓣下图书信息 Python爬虫(二)——豆瓣图书决策树构建 Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析 数据的构建 在这张表中我们可以发现 ...
- 做一个简单的scrapy爬虫
前言: 做一个简单的scrapy爬虫,带大家认识一下创建scrapy的大致流程.我们就抓取扇贝上的单词书,python的高频词汇. 步骤: 一,新建一个工程scrapy_shanbay 二,在工程中中 ...
- 作业1开发一个简单的python计算器
开发一个简单的python计算器 实现加减乘除及拓号优先级解析 用户输入 1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568 ...
随机推荐
- 设置ArcGIS的外观改回到出厂
在一般的软件中,都可以在工具-选项中打开相关设置将应用程序的外观改回到出厂.但ArcGIS好像没有,但查帮助文档原来是这样: 配置的更改保存在模板文档中(例如,ArcMap 将其更改保存在 Norma ...
- CRM ribbon按钮上引用JS库
在CRM ribbion 按钮上引用 javascript库文件实验,怎么要引用javascript库文件.实验 加载完ribbbion 按钮后立即执行 引用的库文件 (function(){ ale ...
- android 浏览器开发实例
android app需要通过手机显示网页信息还是比较常用的,比如我最近业余开发的 抢商铺游戏,需要对游戏规则做说明,规则会比较多,而且要经常变动,就想到用网页来展示,更新起来方便,不像应用,一旦发布 ...
- CoreAnimation(CA)
开发者真会玩,原来我看到CA都懵了.啥是CA?原来就是Core Animation.哎,读书少啊,被虐成
- 明明已经执行Log.i,偏偏打不出日志
Android内打日志用的当然是Log.i(tag,string),调试时的日志输出可以很快的反映一些问题,方便我们跟进. 但是如果连日志都打不出来了怎么办呢,我今天就遇到了比较坑的问题.项目里别的日 ...
- Android开发者的Git&Github(一)
安装Git: Linux(以Ubuntu为例): sudo apt-get install git-core Windows: 访问网址http://msysgit.github.io/下载安装包 下 ...
- C++语言-01-简介
简介 C++语言是C语言的超集,它扩充和完善了C语言:C++语言是一种静态类型的.编译时的.跨平台的.不规则的中级编程语言,综合了高级语言和低级语言的特点 C++支持的编程类型 面向对象编程 过程化编 ...
- 关于在Xcode的OC工程中相对路径失败的原因
Xcode的工程生成的可执行文件不是默认在源文件同一个目录下面的,所以当可执行文件执行的时候,相对路径就不对了. 这一点用终端直接编译执行文件证明了这一点: clang -fobjc-arc -fra ...
- paas架构之docker——镜像管理
1. 镜像管理 1.1. 列出镜像 Sudo docker images 1.2. 查看镜像 Sudo docker images xxxx 1.3. 拉取镜像 Sudo docker pull ub ...
- maven 的 pom.xml 文件报错:ArtifactTransferException: Failure to transfer
因为maven下载依赖jar包时,特别慢,所以取消了下载过程,再次打开eclipse时,maven的pom.xml文件报错如下: ArtifactTransferException: Failure ...