一个简单的python爬虫,以豆瓣妹子“http://www.dbmeizi.com/category/2?p= ”为例
本想抓取网易摄影上的图,但发现查看html源代码时找不到图片的url,但firebug却能定位得到。(不知道为什么???)
目标是抓取前50页的爆乳图,代码如下:
import urllib2,urllib,re,os
'''
http://www.dbmeizi.com/category/2?p=%
'''
def get_url_from_douban():
url_list=[]
p=re.compile(r'''<img.*?src="(.+?\.jpg)''') #找出发布人的标题和url
for i in range(1,50):
target = r"http://www.dbmeizi.com/category/2?p=%d"%i
# print target
req=urllib2.urlopen(target)
result=req.read()
matchs=p.findall(result)
url_list.extend(matchs)
# print matchs
# print "-----"*40
return url_list
def download_pic(url_list):
# print url_lists
count=0
if not os.path.exists('/tmp/pic'):
os.mkdir('/tmp/pic/')
for url in url_list:
urllib.urlretrieve(url,'/tmp/pic/'+str(count)+'.jpg')
count+=1 if __name__=='__main__':
# start_time=time.time()
print "start getting url..."
url_lists=get_url_from_douban()
print "url getted! downloading..."
download_pic(url_lists)
print "download finish!!!"
# cost_time=time.time() - start_time()
# print cost_time
# download_pic(url_lists) ------------------------------------------------------------------------------
/System/Library/Frameworks/Python.framework/Versions/2.7/bin/python /Users/lsf/PycharmProjects/some_subject/get_doubanmeizi_pic.py
start getting url...
url getted! downloading...
download finish!!!
Process finished with exit code 0
运行结果如图:
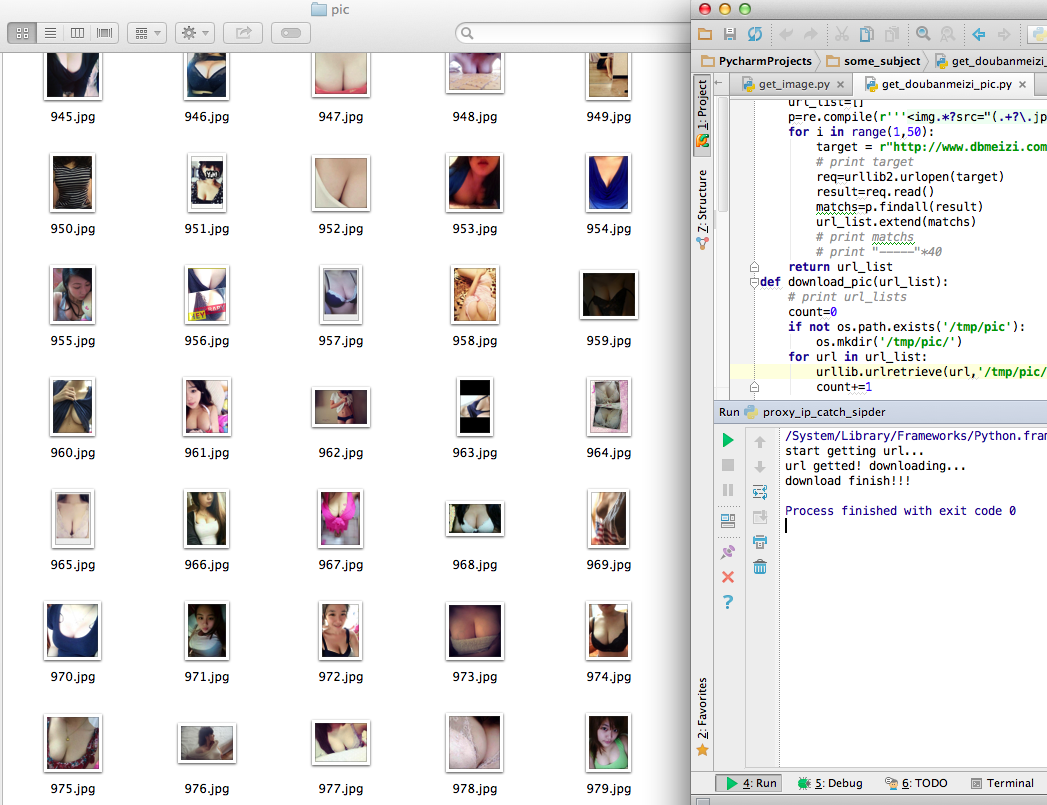
只是一个简单的实现方式,没有考虑性能,速度挺慢的。
ps:贴图会不会被查水表!!??
一个简单的python爬虫,以豆瓣妹子“http://www.dbmeizi.com/category/2?p= ”为例的更多相关文章
- 一个简单的python爬虫程序
python|网络爬虫 概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- 【Python学习笔记三】一个简单的python爬虫
这里写爬虫用的requests插件 1.一般那3.x版本的python安装后都带有相应的安装文件,目录在python安装目录的Scripts中,如下: 2.将scripts的目录配置到环境变量pa ...
- 一个简单的python爬虫(转)
# -*- coding: utf-8 -*- #--------------------------------------- # 程序:百度贴吧爬虫 # 版本:0.1 # 作者:why # 日期: ...
- 一个简单的Python爬虫
写了一个抓taobao图片的爬虫,全是用if,for,while写的,比较简陋,入门作品. 从网页http://mm.taobao.com/json/request_top_list.htm?type ...
- python实现的一个简单的网页爬虫
学习了下python,看了一个简单的网页爬虫:http://www.cnblogs.com/fnng/p/3576154.html 自己实现了一个简单的网页爬虫,获取豆瓣的最新电影信息. 爬虫主要是获 ...
- Python爬虫(四)——豆瓣数据模型训练与检测
前文参考: Python爬虫(一)——豆瓣下图书信息 Python爬虫(二)——豆瓣图书决策树构建 Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析 数据的构建 在这张表中我们可以发现 ...
- 做一个简单的scrapy爬虫
前言: 做一个简单的scrapy爬虫,带大家认识一下创建scrapy的大致流程.我们就抓取扇贝上的单词书,python的高频词汇. 步骤: 一,新建一个工程scrapy_shanbay 二,在工程中中 ...
- 作业1开发一个简单的python计算器
开发一个简单的python计算器 实现加减乘除及拓号优先级解析 用户输入 1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568 ...
随机推荐
- Bootstrap 我的学习记录2 栅格系统初识
以下理论内容copy自bootstrap中文网(一个不错的bootstrap学习网站). 栅格系统 Bootstrap 提供了一套响应式.移动设备优先的流式栅格系统,随着屏幕或视口(viewport) ...
- vundle按照YouComplete
https://github.com/VundleVim/Vundle.vim http://www.jianshu.com/p/d908ce81017a?nomobile=yes http://ww ...
- SharePoint 2013 列表多表联合查询
在SharePoint的企业应用中,遇到复杂的逻辑的时候,我们会需要多表查询:SharePoint和Sql数据表一样,也支持多表联合查询,但是不像Sql语句那样简单,需要使用SPQuery的Joins ...
- Setting up your App domain for SharePoint 2013
from:http://sharepointchick.com/archive/2012/07/29/setting-up-your-app-domain-for-sharepoint-2013.as ...
- SharePoint固定的Footer
原文地址:http://www.eliostruyf.com/sticky-footer-solution-for-sharepoint-2013/ 照搬全文: OFFICE 365 & SH ...
- iOS 获取系统音量
//设置一个全局变量 UISilder * volumeViewSlider; #pragma mark - 获取系统音量 - (void)configureVolume { volumeView = ...
- iOS-RegexKitLite导入错误
RegexKitLite是什么? RegexKitLite是一个非常方便的处理正则表达式的第三方类库. 本身只有一个RegexKitLite.h和RegexKitLite.m 导入RegexKitLi ...
- WPF Caliburn.Micro ListView 批量删除 新方法.高效的
上一片我做的批量删除,是更具ListView的选项改变事件,然后放到一个全局变量里面,缺点已经说了.这次又找到一个好的方法.和大家分享一下.这次我将删除按钮的click事件里面的参数绑定为ListVi ...
- androidannotation study(1)---Activity, Fragment,Custom Class & Custom View
androidannotation 是github上的一个开源项目. 主要是注解机制,可以改善android写代码的效率. Activity 使用 1.@EActivity 注解 可想而知,servi ...
- Nginx为什么比Apache Httpd高效:原理篇
一.进程.线程? 进程是具有一定独立功能的,在计算机中已经运行的程序的实体.在早期系统中(如linux 2.4以前),进程是基本运作单位,在支持线程的系统中(如windows,linux2.6)中,线 ...