mysql:on duplicate key update与replace into
在往表里面插入数据的时候,经常需要:a.先判断数据是否存在于库里面;b.不存在则插入;c.存在则更新
一、replace into
前提:数据库里面必须有主键或唯一索引,不然replace into 会直接插入新数据,导致数据表里面有重复数据
执行时先尝试插入数据:
a.当数据表里面存在(通过主键或唯一索引来判断)该数据,则先将表里的数据删除,再插入新的数据
b.如果数据表里面不存在该数据,则直接插入数据
replace into是insert into的增强版,语法跟insert iton差不多
replace into table_name(columns)values(values1,values2);
replace into table_name(columns) select columns from table_name2
测试数据(该表建立了一个复合的唯一索引user_add):
CREATE TABLE `relace_on` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(11) unsigned NOT NULL,
`interal` tinyint(3) unsigned NOT NULL,
`add_time` date NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `user_add` (`user_id`,`add_time`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1;
插入测试数据:
INSERT INTO relace_on (user_id, interal, add_time)
VALUES
(1,20,'2016-05-06'),
(2,20,'2016-05-06'),
(3,20,'2016-05-06'),
(1,20,'2016-05-07'),
(2,20,'2016-05-07'),
(3,20,'2016-05-07')
现在数据库数据:
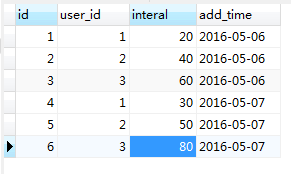
接下来执行一下replace into语句(存在):replace INTO relace_on(user_id, interal, add_time)values(1,40,'2016-05-06'),(2,60,'2016-05-06'),(3,80,'2016-05-06')
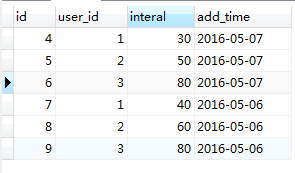 此时sql执行成功,受影响行数为6行(删除三条,插入三条)
此时sql执行成功,受影响行数为6行(删除三条,插入三条)
对比一下你会发现user_id(1,2,3)的账户在2016-05-06这一天原先都是有数据的,并且id为(1,2,3);现在执行了replace into后,id变成了(7,8,9),并且interal字段的值为执行语句的值,此时replace into语句根据数据表中的user_add这个复合的唯一索引发现在数据表中user_id为(1,2,3)的用户在2016-05-06这天各存在一条记录,这时就把原先的三条数据删除了,重新插入了三条,所以id从1,2,3变成了7,8,9;并且interal的值也变了
接下来执行一下replace into语句(不存在):replace INTO relace_on(user_id, interal, add_time)values(4,40,'2016-05-06'),(5,60,'2016-05-06'),(6,80,'2016-05-06')
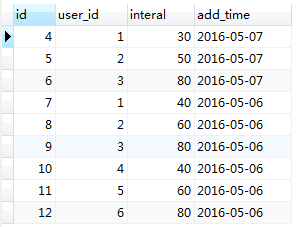 此时sql执行成功,受影响行数为3行(插入三条)
此时sql执行成功,受影响行数为3行(插入三条)
对比上图,你会发现原先的数据没变,只是新增了三条数据,同样是2016-05-06这天的,但是user_id是(4,5,6)根据user_add这个复合的唯一索引,这三条数据不存在数据表中,所以直接插入即可
二、on duplicate key update
它也是可以用于更新数据的,跟replace into有点相似,但是on duplicate key update是数据表里面存在该数据就更新,不存在则插入,;而replace into则是存在就删除,再插入,不存在则插入
依旧使用上面现有的数据来测试:
先添加一个字段,用于等下更新多个字段之用:ALTER TABLE `relace_on` ADD COLUMN `copy_interal` tinyint(3) UNSIGNED NOT NULL AFTER `interal`;
语法:
更新单个字段:insert into table_name(columns)values(values1,values2) on duplicate key update column=values(column)或者column=value(1,'zgw')
更新多个字段:insert into table_name(columns)values(values1,values2) on duplicate key update column1=values(column1),column2=values(column2)
执行一条语句(存在):insert into relace_on(user_id, interal,copy_interal, add_time)values(6,100,200,'2016-05-06') on duplicate KEY update interal=values(interal),copy_interal=values(copy_interal)
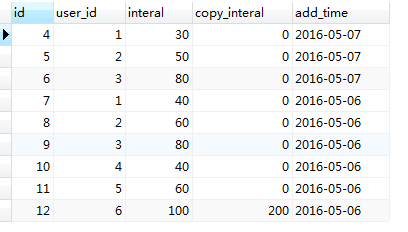
如图,user_id=6,add_time='2016-05-06'这条数据存在,则更新interal和copy_interal两个字段的值(interal原先为80,copy_interal新增字段默认为0)
再次执行一条语句(不存在):insert into relace_on(user_id, interal,copy_interal, add_time)values(7,100,200,'2016-05-06') on duplicate KEY update interal=values(interal),copy_interal=values(copy_interal)
mysql:on duplicate key update与replace into的更多相关文章
- mysql ON DUPLICATE KEY UPDATE 与 REPLACE INTO 的区别
#mysql ON DUPLICATE KEY UPDATE 如果在INSERT语句末尾指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY ...
- mysql ON DUPLICATE KEY UPDATE、REPLACE INTO
INSERT INTO ON DUPLICATE KEY UPDATE 与 REPLACE INTO,两个命令可以处理重复键值问题,在实际上它之间有什么区别呢?前提条件是这个表必须有一个唯一索引或主键 ...
- mysql ON DUPLICATE KEY UPDATE ; 以及 同replace to 的区别.
需求: 1)如果admin表中没有数据, 插入一条 2)如果admin表中有数据, 不插入. 一般做法: if($result = mysql_query("select * from ad ...
- mysql 添加数据如果数据存在就更新ON DUPLICATE KEY UPDATE和REPLACE INTO
#下面建立game表,设置name值为唯一索引. CREATE TABLE `game` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar( ...
- 深入mysql “ON DUPLICATE KEY UPDATE” 语法的分析
本篇文章是对mysql “ON DUPLICATE KEY UPDATE”语法进行了详细的分析介绍,需要的朋友参考下. mysql “ON DUPLICATE KEY UPDATE” 语法 如果在IN ...
- mysql插入数据时 insert IGNORE、ON DUPLICATE KEY UPDATE、replace into
转: mysql insert时几个操作DELAYED .IGNORE.ON DUPLICATE KEY UPDATE的区别 博客分类: mysql基础应用 mysql insert时几个操作DE ...
- mysql 插入更新判断 ON DUPLICATE KEY UPDATE 和 REPLACE INTO
平时我们在设计数据库表的时候总会设计 unique 或者 给表加上 primary key 的限制条件.此时 插入数据的时候 ,经常会有这样的情况:我们想向数据库插入一条记录: 若数据表中存在以相同主 ...
- insert into ... on duplicate key update 与 replace 区别
on duplicate key update:针对主健与唯一健,当插入值中的主健值与表中的主健值,若相同的主健值,就更新on duplicate key update 后面的指定的字段值,若没有相同 ...
- mysql ON DUPLICATE KEY UPDATE重复插入时更新
mysql当插入重复时更新的方法: 第一种方法: 示例一:插入多条记录 假设有一个主键为 client_id 的 clients 表,可以使用下面的语句: INSERT INTO clients (c ...
随机推荐
- 将Asset中的数据库文件拷贝出来使用
设置保存路径 private final static String DATABASE_PATH = "/data"+ Environment.getDataDirectory() ...
- 【CEDEC 2015】【夏日课堂】制作事宜技术篇,新手职员挑战VR Demo开发的真相
日文原文地址 http://www.4gamer.net/games/277/G027751/20150829002/ PS:CEDEC 2015的PPT有些要到10月才有下载,目前的都是记者照片修图 ...
- "专家来了",后天周五提测,跟组长沟通
Nsstring *str = yes ? @"hhh" : @"yyy"; 一开始图片文件夹层次结构不对, 当你把图片拖进去,就对了, 一开始没有内容,所 ...
- 【php学习】字符串操作
关于字符串的处理,基本上就是那几种操作:字符串长度.查找子字符串的位置.替换字符串.截取字符串.拆分合并字符串 ... 字符串的定义:直接 $str = "abcd"; 或者 $s ...
- APP 上架苹果应用商城
http://www.360doc.com/content/15/0203/15/19663521_445974056.shtml http://jingyan.baidu.com/article/4 ...
- Win7+VS2005编译Qt4.7.3+phonon(需要安装新版本Windows SDK)
Qt官网上下载的源代码在编译时并没有将phonon继承进去,只提供了源代码,而在Win7+VS2005中编译phonon时遇到不少的问题,因为phonon只是一个前端程序,要使用其实现多媒体的播放还需 ...
- 【Android测试】【第十节】MonkeyRunner—— 录制回放
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/4861693.html 前言 在实际项目进行过程中,频繁的需 ...
- JQuery源码之“对象的结构解析”
吃完午饭,觉得有点发困,想起了以后我们的产品可能要做到各种浏览器的兼容于是乎不得不清醒起来!我们的web项目多数是依赖于Jquery的.据了解,在Jquery的2.0版本以后对IE的低端版本浏览器不再 ...
- Nmap 網路診斷工具基本使用技巧與教學
Nmap 是一個開放原始碼的網路掃描與探測工具,可以讓網路管理者掃描整個子網域或主機的連接埠等,功能非常強大. Nmap(Network Mapper)是一個開放原始碼的網路檢測工具,它的功能非常強大 ...
- 关于带透明度的灰度层的show、hide
原理图如下:[需要注意的是,灰度View与中间的小View是并列的关系,否则,带透明度的灰度图就会影响小View的透明度] - (void)show{ UIWindow *win = [[UIAppl ...