mysql:on duplicate key update与replace into
在往表里面插入数据的时候,经常需要:a.先判断数据是否存在于库里面;b.不存在则插入;c.存在则更新
一、replace into
前提:数据库里面必须有主键或唯一索引,不然replace into 会直接插入新数据,导致数据表里面有重复数据
执行时先尝试插入数据:
a.当数据表里面存在(通过主键或唯一索引来判断)该数据,则先将表里的数据删除,再插入新的数据
b.如果数据表里面不存在该数据,则直接插入数据
replace into是insert into的增强版,语法跟insert iton差不多
replace into table_name(columns)values(values1,values2);
replace into table_name(columns) select columns from table_name2
测试数据(该表建立了一个复合的唯一索引user_add):
CREATE TABLE `relace_on` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(11) unsigned NOT NULL,
`interal` tinyint(3) unsigned NOT NULL,
`add_time` date NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `user_add` (`user_id`,`add_time`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1;
插入测试数据:
INSERT INTO relace_on (user_id, interal, add_time)
VALUES
(1,20,'2016-05-06'),
(2,20,'2016-05-06'),
(3,20,'2016-05-06'),
(1,20,'2016-05-07'),
(2,20,'2016-05-07'),
(3,20,'2016-05-07')
现在数据库数据:
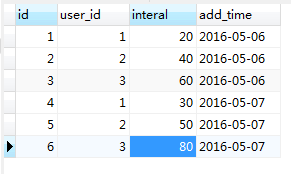
接下来执行一下replace into语句(存在):replace INTO relace_on(user_id, interal, add_time)values(1,40,'2016-05-06'),(2,60,'2016-05-06'),(3,80,'2016-05-06')
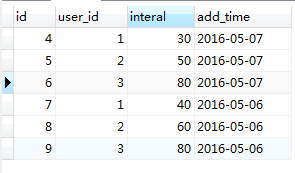 此时sql执行成功,受影响行数为6行(删除三条,插入三条)
此时sql执行成功,受影响行数为6行(删除三条,插入三条)
对比一下你会发现user_id(1,2,3)的账户在2016-05-06这一天原先都是有数据的,并且id为(1,2,3);现在执行了replace into后,id变成了(7,8,9),并且interal字段的值为执行语句的值,此时replace into语句根据数据表中的user_add这个复合的唯一索引发现在数据表中user_id为(1,2,3)的用户在2016-05-06这天各存在一条记录,这时就把原先的三条数据删除了,重新插入了三条,所以id从1,2,3变成了7,8,9;并且interal的值也变了
接下来执行一下replace into语句(不存在):replace INTO relace_on(user_id, interal, add_time)values(4,40,'2016-05-06'),(5,60,'2016-05-06'),(6,80,'2016-05-06')
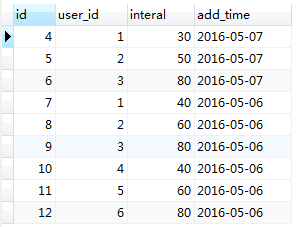 此时sql执行成功,受影响行数为3行(插入三条)
此时sql执行成功,受影响行数为3行(插入三条)
对比上图,你会发现原先的数据没变,只是新增了三条数据,同样是2016-05-06这天的,但是user_id是(4,5,6)根据user_add这个复合的唯一索引,这三条数据不存在数据表中,所以直接插入即可
二、on duplicate key update
它也是可以用于更新数据的,跟replace into有点相似,但是on duplicate key update是数据表里面存在该数据就更新,不存在则插入,;而replace into则是存在就删除,再插入,不存在则插入
依旧使用上面现有的数据来测试:
先添加一个字段,用于等下更新多个字段之用:ALTER TABLE `relace_on` ADD COLUMN `copy_interal` tinyint(3) UNSIGNED NOT NULL AFTER `interal`;
语法:
更新单个字段:insert into table_name(columns)values(values1,values2) on duplicate key update column=values(column)或者column=value(1,'zgw')
更新多个字段:insert into table_name(columns)values(values1,values2) on duplicate key update column1=values(column1),column2=values(column2)
执行一条语句(存在):insert into relace_on(user_id, interal,copy_interal, add_time)values(6,100,200,'2016-05-06') on duplicate KEY update interal=values(interal),copy_interal=values(copy_interal)
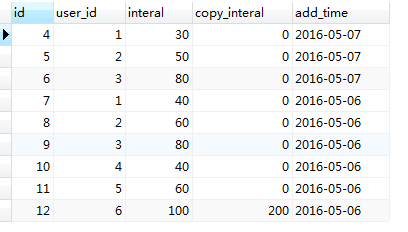
如图,user_id=6,add_time='2016-05-06'这条数据存在,则更新interal和copy_interal两个字段的值(interal原先为80,copy_interal新增字段默认为0)
再次执行一条语句(不存在):insert into relace_on(user_id, interal,copy_interal, add_time)values(7,100,200,'2016-05-06') on duplicate KEY update interal=values(interal),copy_interal=values(copy_interal)
mysql:on duplicate key update与replace into的更多相关文章
- mysql ON DUPLICATE KEY UPDATE 与 REPLACE INTO 的区别
#mysql ON DUPLICATE KEY UPDATE 如果在INSERT语句末尾指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY ...
- mysql ON DUPLICATE KEY UPDATE、REPLACE INTO
INSERT INTO ON DUPLICATE KEY UPDATE 与 REPLACE INTO,两个命令可以处理重复键值问题,在实际上它之间有什么区别呢?前提条件是这个表必须有一个唯一索引或主键 ...
- mysql ON DUPLICATE KEY UPDATE ; 以及 同replace to 的区别.
需求: 1)如果admin表中没有数据, 插入一条 2)如果admin表中有数据, 不插入. 一般做法: if($result = mysql_query("select * from ad ...
- mysql 添加数据如果数据存在就更新ON DUPLICATE KEY UPDATE和REPLACE INTO
#下面建立game表,设置name值为唯一索引. CREATE TABLE `game` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar( ...
- 深入mysql “ON DUPLICATE KEY UPDATE” 语法的分析
本篇文章是对mysql “ON DUPLICATE KEY UPDATE”语法进行了详细的分析介绍,需要的朋友参考下. mysql “ON DUPLICATE KEY UPDATE” 语法 如果在IN ...
- mysql插入数据时 insert IGNORE、ON DUPLICATE KEY UPDATE、replace into
转: mysql insert时几个操作DELAYED .IGNORE.ON DUPLICATE KEY UPDATE的区别 博客分类: mysql基础应用 mysql insert时几个操作DE ...
- mysql 插入更新判断 ON DUPLICATE KEY UPDATE 和 REPLACE INTO
平时我们在设计数据库表的时候总会设计 unique 或者 给表加上 primary key 的限制条件.此时 插入数据的时候 ,经常会有这样的情况:我们想向数据库插入一条记录: 若数据表中存在以相同主 ...
- insert into ... on duplicate key update 与 replace 区别
on duplicate key update:针对主健与唯一健,当插入值中的主健值与表中的主健值,若相同的主健值,就更新on duplicate key update 后面的指定的字段值,若没有相同 ...
- mysql ON DUPLICATE KEY UPDATE重复插入时更新
mysql当插入重复时更新的方法: 第一种方法: 示例一:插入多条记录 假设有一个主键为 client_id 的 clients 表,可以使用下面的语句: INSERT INTO clients (c ...
随机推荐
- PHP生成随机密码的4种方法及性能对比
PHP生成随机密码的4种方法及性能对比 http://www.php100.com/html/it/biancheng/2015/0422/8926.html 来源:露兜博客 时间:2015-04 ...
- LR网页细分图中的时间详解
Web Page Diagnostics: 1)DNS Resolution:浏览器访问一个网站的时候,一般用的是域名,需要dns服务器把这个域名解析为IP,这个过程就是域名解析时间,如果我们在局域网 ...
- shell执行mysql操作
http://ully.iteye.com/blog/1226494 http://www.jb51.net/article/55207.htm shell执行mysql操作 mysql -hhos ...
- SQL_NO_CACHE
http://dev.mysql.com/doc/refman/5.7/en/query-cache-in-select.html MySQL 5.7 Reference Manual / ... ...
- SVM神经网络的术语理解
SVM(Support Vector Machine)翻译成中文是支持向量机, 这里的“机(machine,机器)”实际上是一个算法.而支持向量则是指那些在间隔区边缘的训练样本点[1]. 当初看到这个 ...
- (转)投票系统,更改ip刷票
前言 相信大家平时肯定会收到朋友发来的链接,打开一看,哦,需要投票.投完票后弹出一个页面(恭喜您,您已经投票成功),再次点击的时候发现,啊哈,您的IP(***.***.***.***)已经投过票了,不 ...
- 蓝牙 BLE GATT 剖析(二)-- GATT UUID and 举例
generic attribute profile (GATT)The Generic Attributes (GATT) define a hierarchical data structure t ...
- TOMCAT源码分析(启动框架)
建议: 毕竟TOMCAT的框架还是比较复杂的, 单是从文字上理解, 是不那么容易掌握TOMCAT的框架的. 所以得实践.实践.再实践. 建议下载一份TOMCAT的源码, 调试通过, 然后单步跟踪其启动 ...
- linux下时间的修改
1.关于时间的修改,在linux还是很重要的,在这里只是介绍一个简单的常用的命令,并且时间不会写入到系统. 2.命令 3.如果想把时间写进系统 修改完成之后,输入clock -w 时间将会被写进CMO ...
- QProgressBar的使用例子
今天下午动手实践了一下QProgressBar,遇到的问题比较多,浪费了不少时间,但收获同样颇多... 程序界面如下: 1 // progressbar.h 2 3 #ifndef PROGR ...