Hadoop - Kylin On OLAP
1.概述
Apache Kylin是一个开源的分布式分析引擎,提供SQL接口并且用于OLAP业务于Hadoop的大数据集上,该项目由eBay贡献于Apache。
2.What is Kylin
在使用一种模型,我们得知道她是干什么的,那么首先来看看Kylin的特性,其内容如下所示:
- 可扩展超快的OLAP引擎:Kylin是为减少在Hadoop上百亿级别数据查询延迟而设计的。
- Hadoop ANSI SQL接口:Kylin为Hadoop提供标准的SQL,其支持大部分查询功能。
- 出色的交互式查询能力:通过Kylin,使用者可以于Hadoop数据进行亚秒级交互,在同样的数据集上提供比Hive更好的性能。
- 多维度Cube:用户能够在Kylin里为百亿以上的数据集定义数据模型并构建Cube。
- 和BI工具无缝整合:Kylin提供与BI工具,如商业化的Tableau。另外,根据官方提供的信息也在后续逐步提供对其他工具的支持。
- 其他特性:
- 对Job的管理和监控
- 压缩和编码的支持
- 增量更新Cube
- 利用HBase Coprocessor去查询
- 基于HyperLogLog的Distinct Count近似算法
- 友好的Web界面用于管理、监控和使用Cube
- 项目及Cube级别的访问控制安全
- 支持LDAP
3.ECOSYSTEM
Kylin有其自己的生态圈,如下图所示:
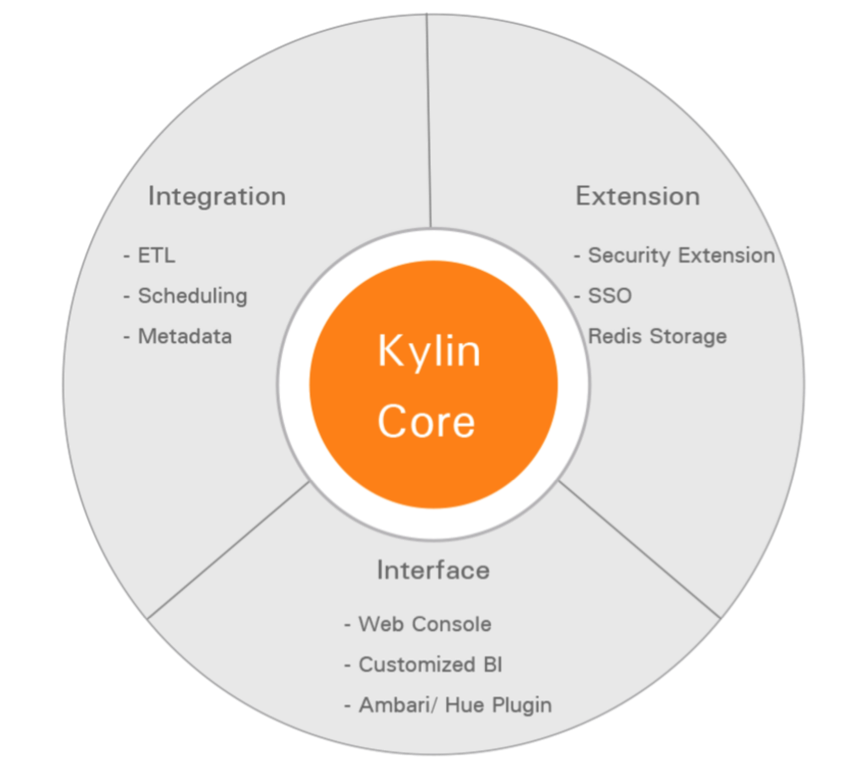
从上图中,我们可以看到,Kylin的核心包含:Kylin OLAP引擎基础框架,Metadata引擎,查询引擎,Job引擎以及存储引擎等等,同时还包括REST服务器以响应客户端请求。另外,还扩展支持额外功能和特性的插件,同时整合与调度系统、ETL、监控等生命周期管理系统。在Kylin核心之上扩展的第三方用户界面,ODBC和JDBC驱动用以支持不同的工具和产品,如:Tableau。
4.Architecture
Kylin的架构概述图如下所示:
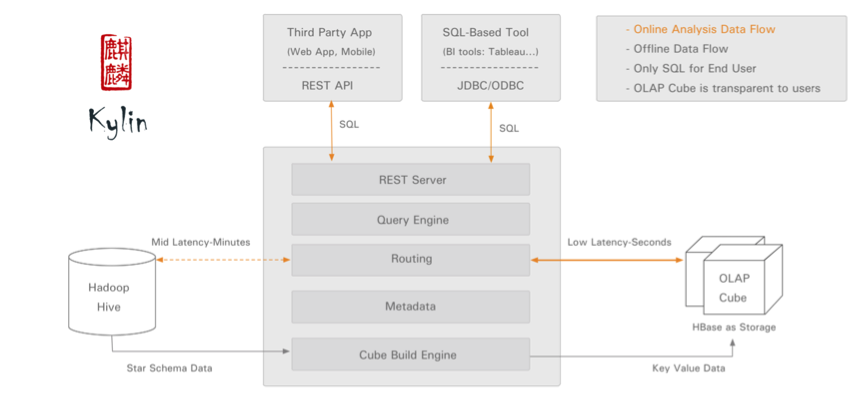
图中的执行流程很清楚,客户端(REST API或JDBC/ODBC)发送SQL请求,将其交给Kylin的执行引擎去处理,Kylin去拉去对应的数据来做处理,并返回处理结果,这里Kylin需要依赖HBase。复杂的事情,Kylin的引擎都给我们处理了,我们只需要负责去编写我们的业务SQL。
5.How TO Works
在Kylin中,我们可以处理三维的业务查询,如下图所示:
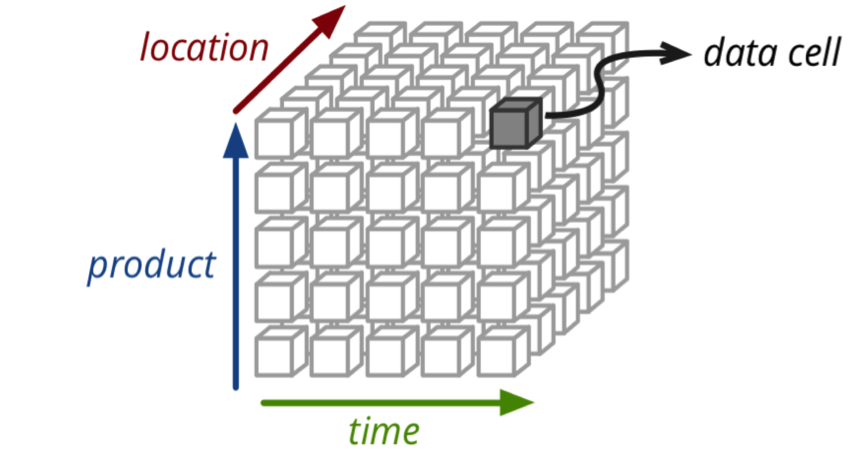
在明白了业务处理方向,其生态群和架构。我们要如何去集成该系统到Hadoop集群?关于Kylin的集成过程是比较方便的,Kylin需要Hadoop、Hive、HBase、JDK,另外,对版本也是有要求的。本版要求如下:
- Hadoop:2.4 - 2.7
- Hive:0.13 - 0.14
- HBase:0.98(这里若是选择Kylin-1.2,需要用到HBase-1.1+以上)
- JDK1.7+
另外,安装Kylin步骤也是比较简单的,步骤如下所示:
- 下载最新的安装包,地址如下:[Kylin.tar.gz]
- 设置KYLIN_HOME环境变量
- 确保用户有权限去访问Hadoop、Hive和HBase,如果不确定的话,我们可以在安装包的bin目录下运行check-env.sh脚本,如果我们有问题的话,她会打印详细的信息。
- 最后,我们可以通过kylin.sh start去启动Kylin,或者使用kylin.sh stop去停止Kylin
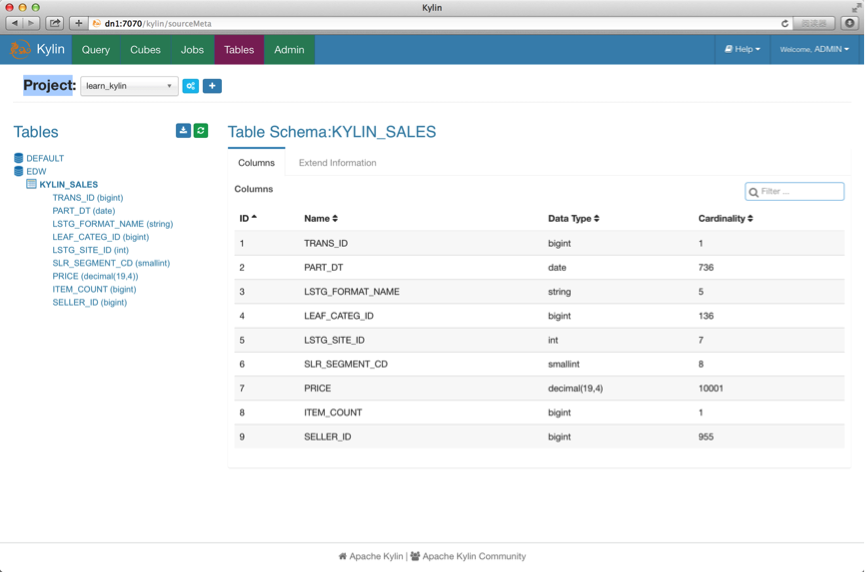
在Kylin启动之后,我们可以通过输入http://node_hostname:7070/kylin去访问Kylin,登录默认用户名和密码为:ADMIN/KYLIN
预览截图如下所示:
另外,我们可以通过JDBC去操作,代码片段如下所示:
Driver driver = (Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance();
Properties info = new Properties();
info.put("user", "ADMIN");
info.put("password", "KYLIN");
Connection conn = driver.connect("jdbc:kylin://dn1:7070/kylin_project_name", info);
Statement state = conn.createStatement();
ResultSet resultSet = state.executeQuery("select * from test_table");
while (resultSet.next()) {
assertEquals("foo", resultSet.getString(1));
assertEquals("bar", resultSet.getString(2));
assertEquals("tool", resultSet.getString(3));
}
6.总结
在使用Kylin时,我们有必要去首先熟悉其架构,这能让我们更加熟悉其应用场景和业务场景。在集成和使用的过程当中会遇到一些问题,我们可以分析其异常日志,然后利用搜索引擎得到解决。关于Kylin的详细使用,大家可以参考官方撰写的文档。
7.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
Hadoop - Kylin On OLAP的更多相关文章
- Hadoop在线分析处理(OLAP)
数据处理与联机分析处理 ( OLAP ) 联机分析处理是那些为了支持商业智能,报表和数据挖掘与探索等业务而开展的工作.这类工作的样例有零售商按地区和季度两个维度计算门店销售额,银行按语言和月份两个维度 ...
- 【转】Kylin系列-使用Saiku+Kylin构建多维分析OLAP平台
关于Kylin的介绍和使用请参考之前的文章 <分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例> Kylin对外提供的是SQL查询接口,基于Kylin构建OL ...
- Hadoop + Hive + HBase + Kylin伪分布式安装
问题导读 1. Centos7如何安装配置? 2. linux网络配置如何进行? 3. linux环境下java 如何安装? 4. linux环境下SSH免密码登录如何配置? 5. linux环境下H ...
- kylin(一): 原理架构
由eBay开源的一个大数据OLAP框架,2014年11月加入了Apache,项目名字也改成了"Apache Kylin",Apache Kylin是唯一来自中国的Apache顶级开 ...
- [kylin] 部署kylin服务
一.工具准备 zookeeper3.4.6 (hadoop.hbase 管理工具) Hadoop. Hbase1.1.4 Kylin1.5.0-HBase1.1.3 Jdk1.7.80 Hive 二. ...
- Hadoop 生态系统
1.概述 最近收到一些同学和朋友的邮件,说能不能整理一下 Hadoop 生态圈的相关内容,然后分享一些,我觉得这是一个不错的提议,于是,花了一些业余时间整理了 Hadoop 的生态系统,并将其进行了归 ...
- 【转】Apache Kylin 2.0为大数据带来交互式的BI
本文转载自:[技术帖]Apache Kylin 2.0为大数据带来交互式的BI 编者注:Kyligence的联合创始人兼CEO Luke Han在上做题为“”的演讲. 基于Hadoop的SQL一直在被 ...
- Kylin web界面 知识点介绍
Big Data Era: 1.More and more data becoming available on Hadoop2.Limitations in existing Business ...
- Python + Apache Kylin 让数据分析更加简单!
现如今,大数据.数据科学和机器学习不仅是技术圈的热门话题,也是当今社会的重要组成.数据就在每个人身边,同时每天正以惊人的速度快速增长,据福布斯报道:到 2025 年,每年将产生大约 175 个 Zet ...
随机推荐
- NoSQL精粹(NoSQL Distilled)——序言
之前说到博客长草的问题,想了想除了很忙特别忙非常忙各种瞎忙忙你妹啊外,主要还是不知道写什么好--到这家公司的两年中从JS到领域驱动到缓存服务器从前端到后端各种折腾,有些东西虽然有所心得,不过既然前人已 ...
- OWIN的理解和实践(二) – Host和Server的开发
对于开发人员来说,代码就是最好的文档,如上一篇博文所说,下面我们就会基于Kanata项目的一些具体调用代码,来进一步深入理解OWIN的实现和作用. 今天我们先针对Host和Server来实现一个简单的 ...
- HttpClient读取ASP.NET Web API错误信息的简单方法
在C#中,用HttpClient调用Web API并且通过Content.ReadAsStringAsync()读取响应内容时,如果出现500错误(InternalServerError),会得到一个 ...
- Lambda表达式的前世今生
Lambda 表达式 早在 C# 1.0 时,C#中就引入了委托(delegate)类型的概念.通过使用这个类型,我们可以将函数作为参数进行传递.在某种意义上,委托可理解为一种托管的强类型的函数指针. ...
- 2014-3-5 星期三 [New Change && New Start]
昨日进度: [计算方法]:起晚啦,迟到一点,有点困,可能因为睡得太晚吧! [无课]:制作IEEE标准在JAVA中的应用. [组成]:-- [多媒体]:-- [人工智能]:-- [寝室]:学习API. ...
- crontab定时任务配置记录
一.前言 今天简单记录下crontab的配置 二.crontab目录 /etc/crontab 文件 这是系统运行的调度任务 /var/spool/cron 目录 用户自定义的crontab任务放在此 ...
- 深入浅出OOP(一): 多态和继承(早期绑定/编译时多态)
在本系列中,我们以CodeProject上比较火的OOP系列博客为主,进行OOP深入浅出展现. 无论作为软件设计的高手.或者菜鸟,对于架构设计而言,均需要多次重构.取舍,以有利于整个软件项目的健康构建 ...
- https封装类,支持get/post请求
所需jar:commons-logging-1.1.3.jar.httpclient-4.3.1.jar.httpcore-4.3.jar package com.onlyou.microfinanc ...
- Spring AOP(注解方式)
配置文件: xmlns:aop="http://www.springframework.org/schema/aop" http://www.springframework.org ...
- 深入理解JavaScript 事件
本文总结自<JavaScript高级程序设计>以及自己平时的经验,针对较新浏览器以及 DOM3 级事件标准(2016年8月),对少部分内容作了更正,增加了各种例子及解析. 如无特殊说明,本 ...