决策树构建算法之—C4.5
这个网站值得收藏一下,原文链接:http://shiyanjun.cn/archives/428.html
决策树算法的优越性在于:离散学习算法进行组合总可以表达任意复杂的布尔函数,并不受数据集的限制即学习没有饱和性,只是现实应用受限于时间和计算能力,一般不能满足不饱和性。
C4.5是机器学习算法中的另一个分类决策树算法,它是基于ID3算法进行改进后的一种重要算法,相比于ID3算法,改进有如下几个要点:
- 用信息增益率来选择属性。ID3选择属性用的是子树的信息增益,这里可以用很多方法来定义信息,ID3使用的是熵(entropy, 熵是一种不纯度度量准则),也就是熵的变化值,而C4.5用的是信息增益率。
- 在决策树构造过程中进行剪枝,因为某些具有很少元素的结点可能会使构造的决策树过适应(Overfitting),如果不考虑这些结点可能会更好。
- 对非离散数据也能处理。
- 能够对不完整数据进行处理。
首先,说明一下如何计算信息增益率。
熟悉了ID3算法后,已经知道如何计算信息增益,计算公式如下所示(来自Wikipedia):
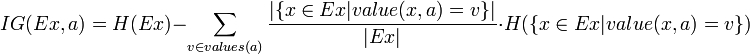
或者,用另一个更加直观容易理解的公式计算:
- 按照类标签对训练数据集D的属性集A进行划分,得到信息熵:
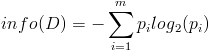
- 按照属性集A中每个属性进行划分,得到一组信息熵:
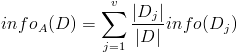
- 计算信息增益
然后计算信息增益,即前者对后者做差,得到属性集合A一组信息增益:
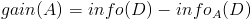
这样,信息增益就计算出来了。
- 计算信息增益率
下面看,计算信息增益率的公式,如下所示(来自Wikipedia):
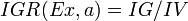
其中,IG表示信息增益,按照前面我们描述的过程来计算。而IV是我们现在需要计算的,它是一个用来考虑分裂信息的度量,分裂信息用来衡量属性分 裂数据的广度和均匀程序,计算公式如下所示(来自Wikipedia):
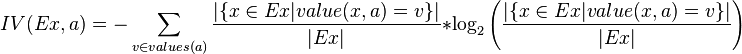
简化一下,看下面这个公式更加直观:
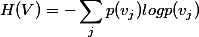 这个是一般的计算公式............
这个是一般的计算公式............
其中,V表示属性集合A中的一个属性的全部取值。
我们以一个很典型被引用过多次的训练数据集D为例,来说明C4.5算法如何计算信息增益并选择决策结点。
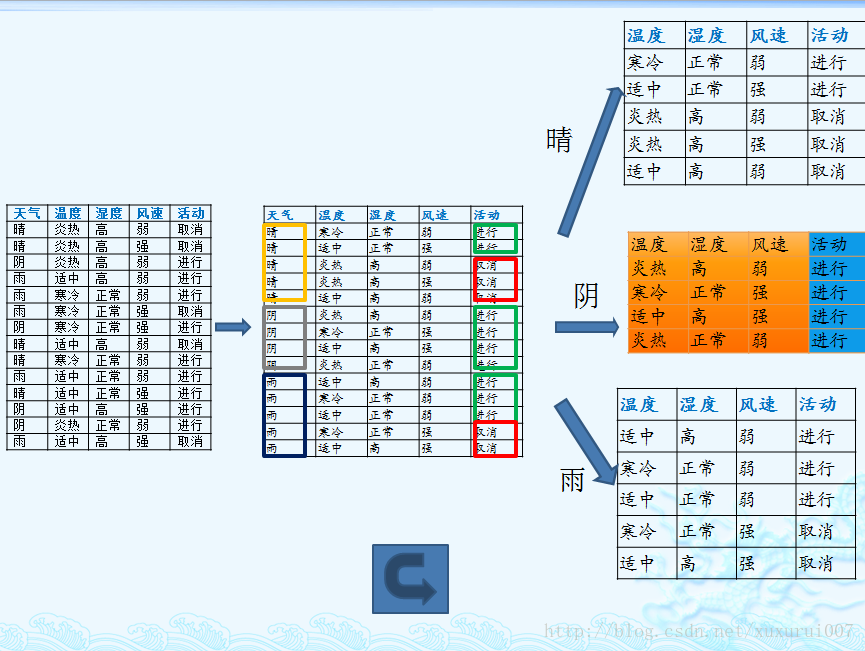
上面的训练集有4个属性,即属性集合A={OUTLOOK, TEMPERATURE, HUMIDITY, WINDY};而类标签有2个,即类标签集合C={Yes, No},分别表示适合户外运动和不适合户外运动,其实是一个二分类问题。
我们已经计算过信息增益,这里直接列出来,如下所示:
数据集D包含14个训练样本,其中属于类别“Yes”的有9个,属于类别“No”的有5个,则计算其信息熵:
1 |
Info(D) |
下面对属性集中每个属性分别计算信息熵,如下所示:
1 |
Info(OUTLOOK) |
2 |
Info(TEMPERATURE) |
3 |
Info(HUMIDITY) |
4 |
Info(WINDY) |
根据上面的数据,我们可以计算选择第一个根结点所依赖的信息增益值,计算如下所示:
1 |
Gain(OUTLOOK) |
2 |
Gain(TEMPERATURE) |
3 |
Gain(HUMIDITY) |
4 |
Gain(WINDY) |
接下来,我们计算分裂信息度量H(V):
- OUTLOOK属性
属性OUTLOOK有3个取值,其中Sunny有5个样本、Rainy有5个样本、Overcast有4个样本,则
1 |
H(OUTLOOK) |
- TEMPERATURE属性
属性TEMPERATURE有3个取值,其中Hot有4个样本、Mild有6个样本、Cool有4个样本,则
1 |
H(TEMPERATURE) |
- HUMIDITY属性
属性HUMIDITY有2个取值,其中Normal有7个样本、High有7个样本,则
1 |
H(HUMIDITY) |
- WINDY属性
属性WINDY有2个取值,其中True有6个样本、False有8个样本,则
1 |
H(WINDY) |
根据上面计算结果,我们可以计算信息增益率,如下所示:
1 |
IGR(OUTLOOK) |
2 |
IGR(TEMPERATURE) |
3 |
IGR(HUMIDITY) |
4 |
IGR(WINDY) |
根据计算得到的信息增益率进行选择属性集中的属性作为决策树结点,对该结点进行分裂。
C4.5算法的优点是:产生的分类规则易于理解,准确率较高。
C4.5算法的缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
决策树构建算法之—C4.5的更多相关文章
- 决策树归纳算法之C4.5
前面学习了ID3,知道了有关“熵”以及“信息增益”的概念之后. 今天,来学习一下C4.5.都说C4.5是ID3的改进版,那么,ID3到底哪些地方做的不好?C4.5又是如何改进的呢? 在此,引用一下前人 ...
- 决策树之ID3、C4.5、C5.0等五大算法
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- C5.0决策树之ID3.C4.5.C5.0算法 ...
- 《机器学习实战》学习笔记第三章 —— 决策树之ID3、C4.5算法
主要内容: 一.决策树模型 二.信息与熵 三.信息增益与ID3算法 四.信息增益比与C4.5算法 五.决策树的剪枝 一.决策树模型 1.所谓决策树,就是根据实例的特征对实例进行划分的树形结构.其中有两 ...
- 03机器学习实战之决策树CART算法
CART生成 CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支.这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有 ...
- 决策树之ID3,C4.5及CART
决策树的基本认识 决策树学习是应用最广的归纳推理算法之一,是一种逼近离散值函数的方法,年,香农引入了信息熵,将其定义为离散随机事件出现的概率,一个系统越是有序,信息熵就越低,反之一个系统越是混乱,它 ...
- 决策树ID3算法--python实现
参考: 统计学习方法>第五章决策树] http://pan.baidu.com/s/1hrTscza 决策树的python实现 有完整程序 决策树(ID3.C4.5.CART ...
- 用Python开始机器学习(2:决策树分类算法)
http://blog.csdn.net/lsldd/article/details/41223147 从这一章开始进入正式的算法学习. 首先我们学习经典而有效的分类算法:决策树分类算法. 1.决策树 ...
- python 之 决策树分类算法
发现帮助新手入门机器学习的一篇好文,首先感谢博主!:用Python开始机器学习(2:决策树分类算法) J. Ross Quinlan在1975提出将信息熵的概念引入决策树的构建,这就是鼎鼎大名的ID3 ...
- 决策树---ID3算法(介绍及Python实现)
决策树---ID3算法 决策树: 以天气数据库的训练数据为例. Outlook Temperature Humidity Windy PlayGolf? sunny 85 85 FALSE no ...
随机推荐
- 基于分布式框架 Jepsen 的 X-Cluster 正确性测试
转自:https://mp.weixin.qq.com/s/iOe1VjG1CrHalr_I1PKdKw 原创 2017-08-27 严祥光(祥光) 阿里巴巴数据库技术 1 概述 AliSQL X-C ...
- 以豌豆荚为例,用 Scrapy 爬取分类多级页面
本文转载自以下网站:以豌豆荚为例,用 Scrapy 爬取分类多级页面 https://www.makcyun.top/web_scraping_withpython17.html 需要学习的地方: 1 ...
- 【ABCD组】Scrum meeting 5
前言 第5次会议在6月17日由组长在教9 405召开. 主要对下一步的工作进行说明安排,时长90min. 主要内容 分配下阶段任务,争取在这阶段完成软件的设计阶段 任务分配 姓名 当前阶段任务 贡献时 ...
- 洛谷 P2813 母舰
题目描述 在小A的星际大战游戏中,一艘强力的母舰往往决定了一场战争的胜负.一艘母舰的攻击力是普通的MA(Mobile Armor)无法比较的. 对于一艘母舰而言,它是由若干个攻击系统和若干个防御系统组 ...
- Redis Hash 的 HSET、HGET、HMSET、HMGET 性能测试
[压测环境] 操作系统: Ubuntu 14.04 LTS Linux版本: 3.13.0-24-generic x86_64 GNU/Linux 处理器: 4核的 AMD Athlon(tm) II ...
- redhat超级用户密码破解
1. 开机在出现grub画面,按e键 2. 用上下键选中第二项(类似于kernel /boot/vmlinuz-2.4.18-14 ro root=LABEL=/) 然后按e键编辑 3. 空格sing ...
- HDU 4617
题目多读几次就明白了.主要是求异面直线的距离,然后用距离和两圆半径之和作比较. 空间直线的距离d=|AB*n| / |n| (AB表示异面直线任意2点的连线,n表示法向量,法向量为两条异面直线方向向量 ...
- POJ 1106
先判断是否在圆内,然后用叉积判断是否在180度内.枚举判断就可以了... 感觉是数据弱了.. #include <iostream> #include <cstdio> #in ...
- print puts p 用法
print puts p 用法 print "a\n" puts "a" p "a\n" 输出为 a a "a\n" p ...
- sass基础教程
1. 使用变量; $highlight-color: #F90; .selected { border: 1px solid $highlight-color; } //编译后 .selected { ...