Working with Python subprocess - Shells, Processes, Streams, Pipes, Redirects
| Posted: | 2009-04-28 15:20 |
|---|---|
| Tags: | Python |
Note
Much of the "What Happens When you Execute a Command?" is based on information in http://en.wikipedia.org/wiki/Redirection_(computing) so go there for the latest version. This post is released under the GFDL.
Contents
- What Happens When you Execute a Command?
- Working with the Shell
- Introducing subprocess
- Using the Shell
- Strings or Argument Lists
- Without the Shell
- Reading from Standard Output and Standard Error
- Writing to Standard Input
- Accessing Return Values, poll() and wait()
- Convenience Functions
- Understanding sys.argv
- Further Reading
In my last post I wrote about how to build a command line interface with sub-commands in Python. In this post I'm going to look at how you can interact with other command line programs using Python's subprocess module.
What I want to be able to do is:
- Find out exactly what happens when you run commands on a command line
- Find out if a command exists and where it actually is
- Execute a command a command from Python either directly or via a shell
- Read from STDOUT and write to STDIN of a running process
- Check the exit status of a process
- Understand the role of Bash in interpreting patterns and sending them to command line programs
What Happens When you Execute a Command?
When you click on the Terminal icon on your Desktop you are loading a program which in turn loads a shell. The commands you write are not executed directly by the kernel but are first interpreted by the shell.
Command (eg. `ls -l')
↓
Terminal Program (eg. `gnome-terminal')
↓
Shell (eg Bash)
↓
Kernel (eg. Linux 2.6.24)
More information about shells:
More information about how processes are actually started:
When you execute a program from Python you can choose to execute it directly with the kernel or via a shell. If you are executing it directly you won't be able to write your commands in quite the same way as you would when using a shell like bash.
Let's look at the different functionality you will be used to using on the shell before looking at how to achive similar results with subprocess.
Streams
In UNIX and Linux, there are three I/O channels known as streams which connect a computer program with its environment such as a text terminal (eg gnome-terminal' running Bash) or another computer program (eg a Python program using the ``subprocess` module). These I/O channels are called the standard input, standard output and standard error respectively and can also be refered to by their corresponding file descriptors which are the numbers 0, 1 and 2 respectively.
| Handle | Name | Description |
|---|---|---|
| 0 | stdin | Standard input |
| 1 | stdout | Standard output |
| 2 | stderr | Standard error |
Here you can see that standarf input is often called stdin, standard output called stdout and standard error called stderr.
The streams work as follows: input from the terminal is sent via the standard input stream to the program, normal output is returned from the program via the standard output and error messages are returned to the environment standard error. The diagram from wikipedia below illustrates this:
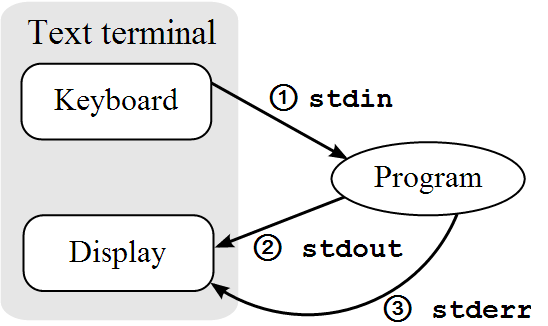
Occasionally you might want to redirect a stream from a program to another location. Let's look at that next.
Working with the Shell
Redirecting Standard input and Standard Output to Files
You can redirect the standard output from a program to a file using the shell operator > in Bash (other shells may have slightly different syntax). Here's an example:
$ program1 > file1
This results in program1 being executed and its standard output stream being written to file1, replacing any existing data in file1. If you'd wanted to append data to the end of the file instead you could use the shell operator >> in Bash:
$ program1 >> file1
The shell operator < can be used to read data from a file and send it to the standard input stream of a program:
$ program1 < file1
Again, program1 is executed but this time file1 is the source of the data for standard input instead of the keybaord.
You can actually combine shell operators to achieve more sophisticated results. In the example below program1 is executed and data from file1 is sent to its standard input. The standard output from running program1 with the input from file1 is then written to file2:
$ program1 < file1 > file2
There may be times when you want the output from one program to be read as the input to another program. You can achieve this using temporary files like this:
$ program1 > tempfile1
$ program2 < tempfile1
$ rm tempfile1
This is a bit cumbersome though so shells provide a facility called piping.
Piping
Piping allows the standard output from one program to be fed directly into the standard input of another without the need for a temporary file:
$ program1 | program2
The | character is known as the pipe character and so this process is known as piping.
Here's another picture from wikipedia illustrating this:

Here's an example of piping the output from find . (which recursively prints the paths of the files and directores in the current directory) into the grep program to find just a particular file:
find . | grep "The file I'm after.txt"
Data from the first program is piped into the second program line by line so the first program doesn't have to finsih before the second program can start using it.
Redirecting Standard Input and Standard Output to and from the Standard File Handles
As well as redirecting the stadard output, you can also redirect other streams, for example to send the standard error data to standard output. In Bash the >, < and >> operators we've already discussed can also be prefixed by the file descriptor (remeber the numbers 0, 1 and 2 in the table earlier) to redirect that stream. If the number is omitted it is assumed to be 1 for the standard output which is why the commands we've used so far work.
This command executes program1 and send's any data it writes to standard error to file1.
program1 2> file1
executes program1, directing the standard error stream to file1.
Here's an example program you can use to test it. Save it as redirect1.py:
import sys
while 1:
try:
input = sys.stdin.readline()
if input:
sys.stdout.write('Echo to stdout: %s'%input)
sys.stderr.write('Echo to stderr: %s'%input)
except KeyboardError:
sys.exit()
This program constantly polls stdin and echos any message it recieves to both stdout and stdout.
In shells derived from csh (the C shell), the syntax instead appends the & character to the redirect characters, thus achieving a similar result.
Another useful capability is to redirect one standard file handle to another. The most popular variation is to merge standard error into standard output so error messages can be processed together with (or alternately to) the usual output. Example:
find / -name .profile > results 2>&1
will try to find all files named .profile. You need the & character even in Bash this time. Executed without redirection, it will output hits to stdout and errors (e.g. for lack of privilege to traverse protected directories) to stderr. If standard output is directed to file results, error messages appear on the console. To see both hits and error messages in file results, merge stderr (handle 2) into stdout (handle 1) using 2>&1 .
It's possible use 2>&1 before ">" but it doesn't work. In fact, when the interpreter reads 2>&1, it doesn't know yet where standard output is redirected and then standard error isn't merged.
If the merged output is to be piped into another program, the file merge sequence 2>&1 must precede the pipe symbol, thus:
find / -name .profile 2>&1 | less
In Bash a simplified form of the command:
command > file 2>&1
is:
command &>file
or:
command >&file
but don't use these shortcuts or you might get confused. Better to be more verbose and explicit.
The &> operator redirects standard output (stdout) and standard error (stderr) at the same time. This is simpler to type than the Bourne shell equivalent command > file 2>&1.
Chained pipelines
The redirection and piping tokens can be chained together to create complex commands. For example:
ls | grep '\.sh' | sort > shlist
lists the contents of the current directory, where this output is filtered to only contain lines which contain .sh, sort this resultant output lexicographically, and place the final output in shlist. This type of construction is used very commonly in shell scripts and batch files.
Redirect to multiple outputs
The standard command tee can redirect output from a command to several destinations.
ls -lrt | tee xyz
This directs the file list output to both standard output as well as to the file xyz.
Here Documents
Most shells, including Bash support here documents which enable you to embed text as part of a command using the << operator and some text to use as a delimiter.
In the following example, text is passed to the tr command using a here document and END_TEXT as the delimiting identifier which specifies the start and end of the here document.
$ tr a-z A-Z <<END_TEXT
> one two three
> uno dos tres
> END_TEXT
ONE TWO THREE
UNO DOS TRES
The output lines produced from tr after execution are ONE TWO THREE and UNO DOS TRES.
A common use of here documents is to add text to a file. By default variables and also commands in backticks are evaluated:
$ cat << EOF
> Working dir $PWD
> EOF
Working dir /home/user
This can be disabled by setting the label in the command line in single or double quotes:
$ cat << "EOF"
> Working dir $PWD
> EOF
Working dir $PWD
Introducing subprocess
Now that we've discussed the sort of functionality offered on the command line, let's experiment with the subprocess module. Here's a simple command you can run on the command line:
$ echo "Hello world!"
Hello world!
Let's try to run this from Python.
In the past, process management in Python was dealt with by a large range of different Python functions from all over the standard library. Since Python 2.4 all this functionality has been carefully and neatly packaged up into the subprocess module which provides one class called Popen which is all you need to use.
Note
If you are interested in how the new Popen class replaces the old functionality the subprocess documentation has a section explaining how things used to be done and how they are done now.
The Popen class takes the following options which are all described in detail at http://docs.python.org/library/subprocess.html#using-the-subprocess-module:
subprocess.Popen(args, bufsize=0, executable=None, stdin=None,
stdout=None, stderr=None, preexec_fn=None, close_fds=False,
shell=False, cwd=None, env=None, universal_newlines=False,
startupinfo=None, creationflags=0
)
Luckily most of the time you will just need to use args and shell.
Using the Shell
Let's start with a simple example and run the Hello World! example in the same way as before, passing the command though the shell:
>>> import subprocess
>>> subprocess.Popen('echo "Hello world!"', shell=True)
Hello world!
<subprocess.Popen object at 0x...>
As you can see, this prints Hello world! to the standard output as before but the interactive console also displays that we have created an instance of the subprocess.Popen class.
If you save this as process_test.py and execute it on the command line you get the same result:
$ python process_test.py
Hello world!
So far so good.
You might we wondering which shell is being used. On Unix, the default shell is /bin/sh. On Windows, the default shell is specified by the COMSPEC environment variable. When you specifyshell=True you can customise the shell to use with the executable argument.
>>> subprocess.Popen('echo "Hello world!"', shell=True, executable="/bin/bash")
Hello world!
<subprocess.Popen object at 0x...>
This example works the same as before but if you were using some shell-specific features you would notice the differences.
Let's explore some other features of using the shell:
Variable expansion:
>>> subprocess.Popen('echo $PWD', shell=True)
/home/james/Desktop
<subprocess.Popen object at 0x...>
Pipes and redirects:
subprocess.Popen('echo "Hello world!" | tr a-z A-Z 2> errors.txt', shell=True)
<subprocess.Popen object at 0x...>
>>> HELLO WORLD!
The errors.txt file will be empty because there weren't any errors. Interstingly on my computer, the Popen instance is displayed before the HELLO WORLD! message is printed to the standard output this time. Pipes and redirects clearly work anyway.
Here documents:
>>> subprocess.Popen("""
... cat << EOF > new.txt
... Hello World!
... EOF
... """, shell=True)
<subprocess.Popen object at 0xb7dbbe2c>
The new.txt file now exists with the content Hello World!.
Unsurprisingly the features that work with a command passed to the shell via the command line also work when passed to the shell from Python, including shell commands.
Strings or Argument Lists
While it is handy to be able to execute commands pretty much as you would on the command line, you often need to pass variables from Python to the commands you are using. Let's say we wanted to re-write this function to use echo:
def print_string(string):
print string
You might do this:
def print_string(string):
subprocess.Popen('echo "%s"'%string, shell=True)
This will work fine for the string Hello World!:
>>> print_string('Hello world!')
Hello world!
But not for this:
>>> print_string('nasty " example')
/bin/sh: Syntax error: Unterminated quoted string
The command being executed is echo "nasty " example" and as you can see, there is a problem with the escaping.
One approach is to deal with the escaping in your code but this can be cumbersome because you have to deal with all the possible escape characters, spaces etc.
Python can handle it for you but you have to avoid using the shell. Let's look at this next.
Without the Shell
Now let's try the same thing without the shell:
def print_string(string):
subprocess.Popen(['echo', string], shell=False)
>>> print_string('Hello world!')
Hello world!
>>> print_string('nasty " example')
nasty " example
As you can see it works correctly with the correct escaping.
Note
You can actually specify a single string as the argument when shell=False but it must be the program itself and is no different from just specifying a list with one element for args. If you try to execute the same sort of command you would when shell=False you get an error:
>>> subprocess.Popen('echo "Hello world!"', shell=False)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python2.5/subprocess.py", line 594, in __init__
errread, errwrite)
File "/usr/lib/python2.5/subprocess.py", line 1147, in _execute_child
raise child_exception
OSError: [Errno 2] No such file or directory
Since we are still passing it as a string, Python assumes the entire string is the name of the program to execute and there isn't a program called echo "Hello world!" so it fails. Instead you have to pass each argument separately.
Checking a Program is on the PATH
Here's a function to find the actual location of a program:
import os
def whereis(program):
for path in os.environ.get('PATH', '').split(':'):
if os.path.exists(os.path.join(path, program)) and \
not os.path.isdir(os.path.join(path, program)):
return os.path.join(path, program)
return None
Let's use this to find out where the echo program really is:
>>> location = whereis('echo')
>>> if location is not None:
... print location
/bin/echo
This function is also very useful for checking whether a user has a program your Python program requires installed on their PATH.
Of course you can also find out the location of programs with the whereis command on the command line:
$ whereis echo
echo: /bin/echo /usr/share/man/man1/echo.1.gz
Note
Notice that whether shell is True or False we haven't had to specify the full path to an executable. As long as the executable is on the PATH environmant variable, you can execute it from Python. Of course, there is no harm in specifying the full path if you prefer.
If you want to be slightly perverse you can specify the executable argument rather than having the executable as the first argument in the args list. This doesn't seem well documented but this is what it does on my computer:
>>> subprocess.Popen(['1', '2', '3'], shell=False, executable='echo')
2 3
<subprocess.Popen object at 0xb776f56c>
The drawback of executing programs without the shell is that you can't so redirection, piping, use here documents, shell expansion or many other techniques you are used to in quite the same way as you would on the command line. Instead you have to handle these features programatically we'll look at this later.
Reading from Standard Output and Standard Error
When you run programs with Popen, output is just sent to stdout as usual which is why you've been able to see the output from all the examples to far.
If you want to be able to read the standard output from a program you have to set the stdout argument in the initial call to Popen to specify that a pipe should be opened to the process. The special value you set is subprocess.PIPE:
- subprocess.PIPE
- Special value that can be used as the stdin, stdout or stderr argument to Popen and indicates that a pipe to the standard stream should be opened.
Here's an example:
>>> process = subprocess.Popen(['echo', 'Hello World!'], shell=False, stdout=subprocess.PIPE)
To read the output from the pipe you use the communicate() method:
>>> print process.communicate()
('Hello World!\n', None)
The value returned from a call to communicate() is a tuple with two values, the first is the data from stdout and the second is the data from stderr.
Here's a program we can use to test the stdout and stderr behaviour. Save it as test1.py:
import sys
sys.stdout.write('Message to stdout\n')
sys.stderr.write('Message to stderr\n')
Let's execute this:
>>> process = subprocess.Popen(['python', 'test1.py'], shell=False, stdout=subprocess.PIPE)
Message to stderr
>>> print process.communicate()
('Message to stdout\n', None)
Notice that the message to stderr gets displayed as it is generated but the message to stdout is read via the pipe. This is because we only set up a pipe to stdout. Let's set up one to stderr too.
>>> process = subprocess.Popen(['python', 'test1.py'], shell=False, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
>>> print process.communicate()
('Message to stdout\n', 'Message to stderr\n')
This time both stdout and stderr can be accessed from Python.
Now that all the messages have been printed, if we call communicate() again we get an error:
>>> print process.communicate()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python2.5/subprocess.py", line 668, in communicate
return self._communicate(input)
File "/usr/lib/python2.5/subprocess.py", line 1207, in _communicate
rlist, wlist, xlist = select.select(read_set, write_set, [])
ValueError: I/O operation on closed file
The communicate() method only reads data from stdout and stderr, until end-of-file is reached.
Redirecting stderr to stdout
If you want messages to stderr to be piped to stdout, you can set a special value for the stderr argument: stderr=subprocess.STDOUT.
Writing to Standard Input
Writing to a process is very similar. In order to write to the process you have to open a pipe to stdin. Once again this can be done by specifying stdin=subprocess.PIPE as an argument to Popen.
To test it let's write another program which simply prints Received: and then repeats the message you send it. It will repeat 3 messages before exiting. Call this test2.py:
import sys
input = sys.stdin.read()
sys.stdout.write('Received: %s'%input)
To send a message to stdin, you pass the string you want to send as the input argument to communicate(). Let's try the program:
>>> process = subprocess.Popen(['python', 'test2.py'], shell=False, stdin=subprocess.PIPE)
>>> print process.communicate('How are you?')
Received: How are you?(None, None)
Notice that the message generated in the test2.py process was printed to stdout and then the return value (None, None) was printed because no pipes were set up to stdout or stderr.
You can also specify stdout=subprocess.PIPE and stderr=subprocess.PIPE just as before to set up the pipes.
The File-like Attributes
The Popen instance also has attributes stdout and stderr which you can write to as if they were file-like objects and a stdin attribute which you can read from like a file. You can use these instead of getting and sending data via communicate() if you prefer. We'll see them next.
Reading and Writing to the Same Process
Here's another program, save it as test3.py:
import sys while True:
input = sys.stdin.readline()
sys.stdout.write('Received: %s'%input)
sys.stdout.flush()
This program simply echos the value it recieves. Let's test it like this:
>>> import time
>>> process = subprocess.Popen(['python', 'test3.py'], shell=False, stdin=subprocess.PIPE, stdout=subprocess.PIPE)
>>> for i in range(5):
... process.stdin.write('%d\n' % i)
... output = process.stdout.readline()
... print output
... time.sleep(1)
...
Received: 0 Received: 1 Received: 2 Received: 3 Received: 4 >>>
Each line of output appears after a second.
You should now have enough knowledge to be able to reproduce in Python all the functionality you might have relied on the shell for in the past.
Accessing Return Values, poll() and wait()
When a program exits it can return an integer value to indicate the exit status. Zero is considered “successful termination” and any nonzero value is considered “abnormal termination” by shells and the like. Most systems require it to be in the range 0-127, and produce undefined results otherwise. Some systems have a convention for assigning specific meanings to specific exit codes, but these are generally underdeveloped; Unix programs generally use 2 for command line syntax errors and 1 for all other kind of errors.
You can access the return code from an exited child process via the .returncode attribute of a Popen instance. Here's an example:
>>> process = subprocess.Popen(['echo', 'Hello world!'], shell=False)
>>> process.poll()
>>> print process.returncode
None
>>> process.poll()
0
>>> print process.returncode
0
The returncode value is not ever set by the child process, it starts off with a default value of None, and remains None until you call a method in the subprocess such as poll() or wait(). Those methods set and then return returncode. As a result, if you want to know what the status of the child process is, you have to call either poll() or wait().
The poll() and wait() methods are subtley different:
- Popen.poll()
- Check if child process has terminated. Set and return .returncode attribute.
- Popen.wait()
- Wait for child process to terminate. Set and return .returncode attribute.
Convenience Functions
The subprocess module has some convenience functions to make executing a command in the simple case more straightforward. I don't use them though.
Understanding sys.argv
If you are writing a Python program to accept command line arguments, the arguments passed on the command line are accessed as sys.argv. Here's a simple example, save it as command.py:
#!/usr/bin/env python if __name__ == '__main__':
import sys
print "Executable: %s"%sys.argv[0]
for arg in sys.argv[1:]:
print "Arg: %s"%arg
The if __name__ == '__main__': line ensures the code beneath it only gets run if the file is executed, not if it is imported. Make this file executable:
$ chmod 755 command.py
Here are some examples of this being run:
$ python command.py
Executable: command.py
$ python command.py arg1
Executable: command.py
Arg: arg1
$ python command.py arg1 arg2
Executable: command.py
Arg: arg1
Arg: arg2
Notice that sys.argv[0] always contains the name of the script which was executed, regardless of how Python was invoked. sys.argv[1] and onward are the command line arguments. You can also invoke the program using Python's -m switch to run it as a module import:
$ python -m command
Executable: /home/james/Desktop/command.py
$ python -m command arg1
Executable: /home/james/Desktop/command.py
Arg: arg1
$ python -m command arg1 arg2
Executable: /home/james/Desktop/command.py
Arg: arg1
Arg: arg2
Once again, Python works out that python -m command are all part of the invoking command so sys.argv[0] only contains the path of the Python script. Let's try executing it directly:
$ ./command.py
Executable: ./command.py
$ ./command.py arg1
Executable: ./command.py
Arg: arg1
$ ./command.py arg1 arg2
Executable: ./command.py
Arg: arg1
Arg: arg2
As you can see, sys.argv[0] still contains the Python script and sys.argv[1] and onwards represent each argument.
Shell Expansion
One small complication when running programs from within a shell is that the shell will sometimes substitute a pattern for a set of arguments. For example, consider this run in the Bash shell:
$ ./command.py *.txt
You might expect the following output:
Executable: ./command.py
Arg: *.txt
but this isn't what you get. Instead the output depends on the number of .txt files in the current working directory. When I run it I get this:
Executable: ./command.py
Arg: errors.txt
Arg: new.txt
Arg: output.txt
The Bash shell substitutes the *.txt command for the filenames of all the .txt files in the current directory so your program recieves more arguments than you might have expected.
You can disable shell expansion by quoting the argument, but actually most of the time it is a very useful feature once you are aware of it.
$ ./command.py "*.txt"
Executable: ./command.py
Arg: *.txt
To learn more about Bash shell expansions, see this: http://www.gnu.org/software/bash/manual/bashref.html#Filename-Expansion
Further Reading
See also:
- http://www.doughellmann.com/PyMOTW/subprocess/ (and its O'Reilly copy here)
- http://docs.python.org/library/subprocess.html
- http://webpython.codepoint.net/cgi_shell_command
- http://www.artima.com/weblogs/viewpost.jsp?thread=4829 (About writing main() functions)
Topics for a future post:
- Send and receive signals between running processes
- Run a program in the background or the foreground
Working with Python subprocess - Shells, Processes, Streams, Pipes, Redirects的更多相关文章
- 【python库模块】Python subprocess模块功能与常见用法实例详解
前言 这篇文章主要介绍了Python subprocess模块功能与常见用法,结合实例形式详细分析了subprocess模块功能.常用函数相关使用技巧. 参考 1. Python subprocess ...
- python subprocess popen 静默模式(不弹出console控制台)
python subprocess popen 静默模式(不弹出console控制台) import subprocess,sys IS_WIN32 = 'win32' in str(sys.plat ...
- python subprocess相关操作
python subprocess常用操作 1.subprocess模块的常用函数 函数 描述 subprocess.run() Python 3.5中新增的函数.执行指定的命令,等待命令执行完成后返 ...
- 通过阅读python subprocess源码尝试实现非阻塞读取stdout以及非阻塞wait
http://blog.chinaunix.net/uid-23504396-id-4661783.html 执行subprocess的时候,执行不是问题最麻烦的是获取进程执行后的回显来确认是否正确执 ...
- python subprocess 自动运行实验室程序
import threading, os, subprocess, time exec_path = "/home/xhz/gems/ruby/amd...../bin/tester.exe ...
- Python subprocess.Popen communicate() 和wait()使用上的区别
之所以会纠结到这个问题上是因为发现在调用Popen的wait方法之后程序一直没有返回.google发现wait是有可能产生死锁的.为了把这个问题彻底弄清楚,搜索一些资料过来看看: 原文链接:http: ...
- python subprocess阻塞
import select import os import subprocess import time import fcntl args = ['python','./fetch_file2.p ...
- Python subprocess模块学习总结
从Python 2.4开始,Python引入subprocess模块来管理子进程,以取代一些旧模块的方法:如 os.system.os.spawn*.os.popen*.popen2.*.comman ...
- python subprocess重定向标准输出
subprocess.call("ping -c 1 %s" % ip,shell = True,stdout = open('/dev/null','w'),stderr = s ...
随机推荐
- 关系型数据库和NOSQL数据库对比
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt328 关系型数据库,是建立在关系模型基础上的数据库,其借助于集合代数等数学概 ...
- 【★】IT界8大恐怖预言
IT界的8大恐怖预言 本文字数:3276 建议阅读时间:你开心就好 第三次科技革命已经进入白热化阶段---信息技术革命作为其中最主要的一环已经奠定了其基本格局和趋势.OK大势已定,根据目前的形势,小编 ...
- 自制ACL+DHCP实验(初版)
(实验用gns模拟器) ACL 实验拓扑: 实验要求: 1.1.1.1→3.3.3.3 不通 11.11.11.11→3.3.3.3 通 2.2.2.2→3.3.3.3 通 实验步骤: 步骤一:基本配 ...
- 201521123025《java程序设计》第8周学习总结
1. 本周学习总结 2.书面作业 Q1.List中指定元素的删除(题目4-1) public static List<String> convertStringToList(String ...
- 《Java程序设计》第5周学习总结
1. 本章学习总结 1.1 尝试使用思维导图总结有关多态与接口的知识点. 1.2 可选:使用常规方法总结其他上课内容. 2. 书面作业 1. 代码阅读:Child压缩包内源代码 1.1 com.par ...
- 201521123014 《Java程序设计》第3周学习总结
1. 本周学习总结 2. 书面作业 Q1. 代码阅读 public class Test1 { private int i = 1;//这行不能修改 private static int j = 2; ...
- java第十周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常与多线程相关内容. 2. 书面作业 1.finally 题目4-2 1.1 截图你的提交结果(出现学号) 1.2 4-2中fin ...
- hdu3037 Saving Beans
Saving Beans Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Pro ...
- SpringSecurity 登录 - 以及Md5加密
我们现在开放一个链接给其他系统,来访问我们的系统 http://localhost:8080/hulk-teller-web/haihui!init.jspa?loginId=teller01& ...
- JPA常用注解(转载)
转自:http://blog.csdn.net/wanghuan203/article/details/8698102 JPA全称Java Persistence API.JPA通过JDK 5.0注解 ...