Linux下Hadoop2.7.1集群环境的搭建(超详细版)


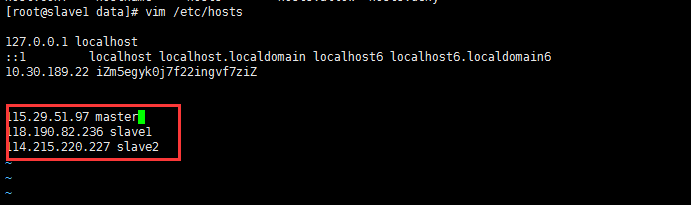
二、Host配置
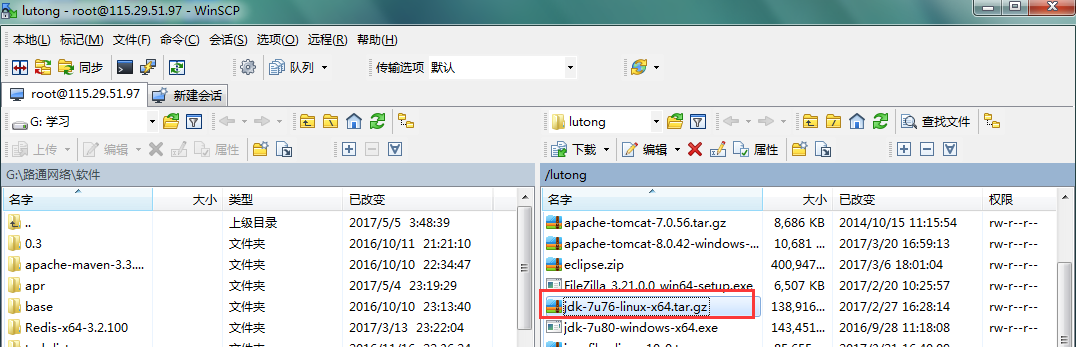
3.2 下载
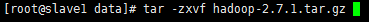
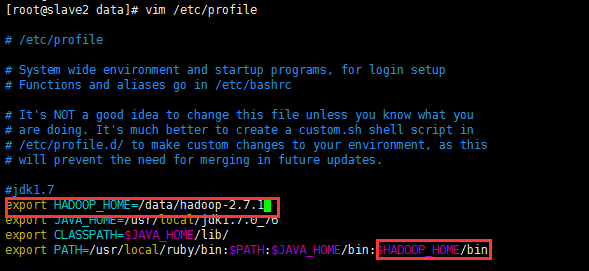





5.1 格式化NameNode
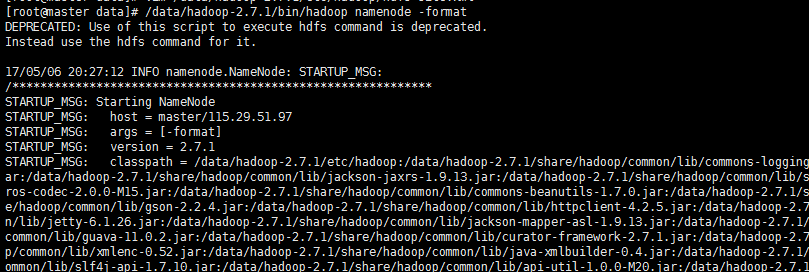
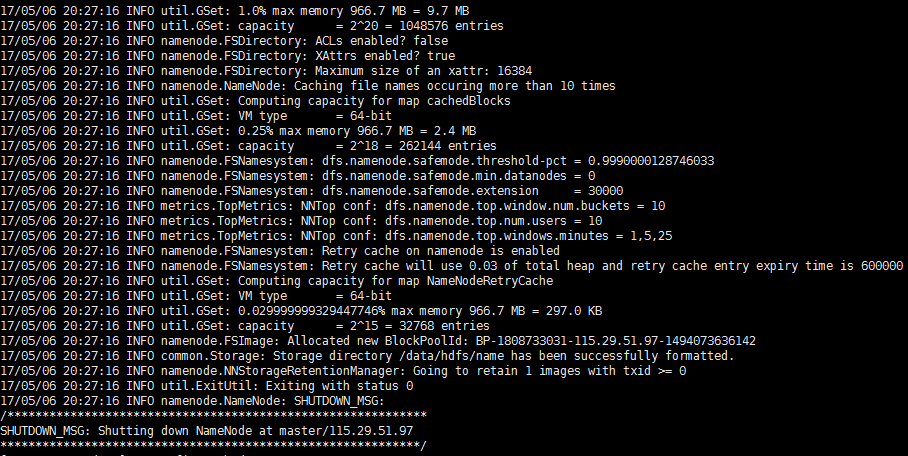
最后的执行结果如下图:
5.2 启动NameNode


在Master上执行jps命令,得到如下结果:


master

slave1

slave2

说明ResourceManager运行正常。

6.1 测试HDFS
最后测试下亲手搭建的Hadoop集群是否执行正常,测试的命令如下图所示:

6.2 测试YARN
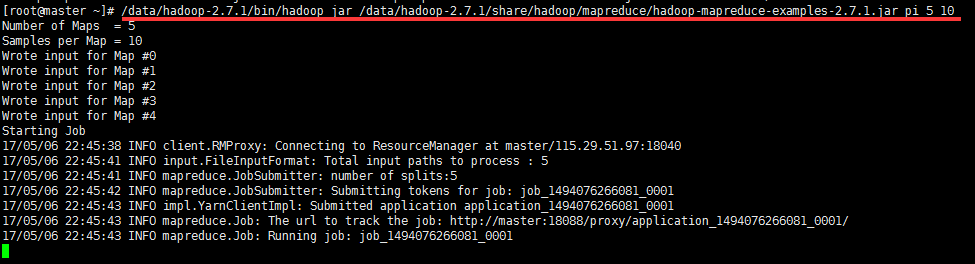
6.3 测试mapreduce
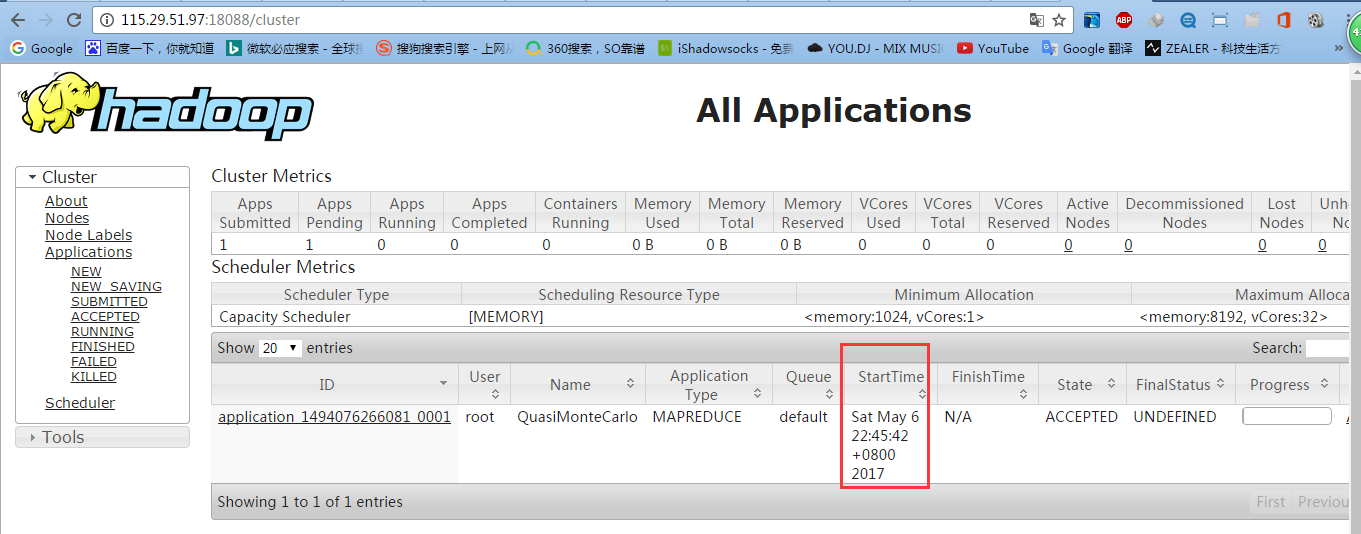
七、配置运行Hadoop中遇见的问题

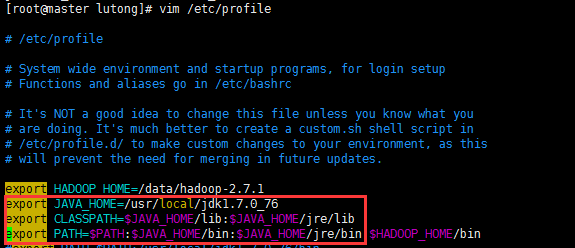
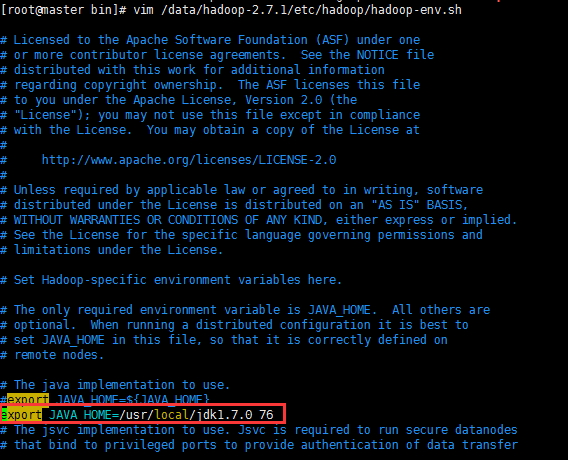
则需要/data/hadoop-2.7.1/etc/hadoop/hadoop-env.sh,添加JAVA_HOME路径
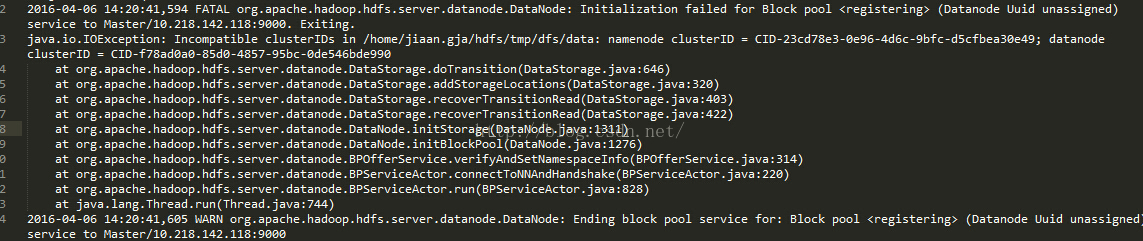
7.2 ncompatible clusterIDs
由于配置Hadoop集群不是一蹴而就的,所以往往伴随着配置——>运行——>。。。——>配置——>运行的过程,所以DataNode启动不了时,往往会在查看日志后,发现以下问题:
7.3 NativeCodeLoader的警告
在测试Hadoop时,细心的人可能看到截图中的警告信息:

Linux下Hadoop2.7.1集群环境的搭建(超详细版)的更多相关文章
- Linux下Hadoop2.7.3集群环境的搭建
Linux下Hadoop2.7.3集群环境的搭建 本文旨在提供最基本的,可以用于在生产环境进行Hadoop.HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用. 基础环境 JDK的安 ...
- Linux下Hadoop2.6.0集群环境的搭建
本文旨在提供最基本的,可以用于在生产环境进行Hadoop.HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用. 基础环境 JDK的安装与配置 现在直接到Oracle官网(http:/ ...
- 基于原生态Hadoop2.6 HA集群环境的搭建
hadoop2.6 HA平台搭建 一.条件准备 软件条件: Ubuntu14.04 64位操作系统, jdk1.7 64位,Hadoop 2.6.0, zookeeper 3.4.6 硬件条件 ...
- (2)虚拟机下hadoop1.1.2集群环境搭建
hadoop集群环境的搭建和单机版的搭建差点儿相同,就是多了一些文件的配置操作. 一.3台主机的hostname改动和IP地址绑定 注意:以下的操作我都是使用root权限进行! (1)3太主机的基本网 ...
- centos6.5环境下zookeeper-3.4.6集群环境部署及单机部署详解
centos6.5环境下Zookeeper-3.4.6集群环境部署 [系统]Centos 6.5 集群部署 [软件]准备好jdk环境,此次我们的环境是open_jdk1.8.0_101 zookeep ...
- Linux下MySQL/MariaDB Galera集群搭建过程【转】
MariaDB介绍 MariaDB是开源社区维护的一个MySQL分支,由MySQL的创始人Michael Widenius主导开发,采用GPL授权许可证. MariaDB的目的是完全兼容MySQL,包 ...
- hadoop集群环境的搭建
hadoop集群环境的搭建 今天终于把hadoop集群环境给搭建起来了,能够运行单词统计的示例程序了. 集群信息如下: 主机名 Hadoop角色 Hadoop jps命令结果 Hadoop用户 Had ...
- Nacos集群环境的搭建与配置
Nacos集群环境的搭建与配置 集群搭建 一.环境: 服务器环境:CENTOS-7.4-64位 三台服务器IP:192.168.102.57:8848,192.168.102.59:8848,192. ...
- redis集群环境的搭建和错误分析
redis集群环境的搭建和错误分析 redis集群时,出现的几个异常问题 09 redis集群的搭建 以及遇到的问题
随机推荐
- 关于struts2中的default-action-ref
struts2中的default-action-ref一般用于,在请求无效或错误时将请求指引到错误页面.我这次的用法是在请求首页之前先发送请求到后台,进行数据获取后再转至首页显示,但是出了一个问题,d ...
- 首个写博客的Android任务
任务1 单击按钮图片选择器 使用TextView,RadioGroup,RadioButton完成. 设置单击按钮选择显示花朵. 首先设置了页面布局 <LinearLayout xmlns:an ...
- @RequestParam--SpringMVC 注解系列文章(一)
概述 RequestParam 注解是使用 SpringMVC 开发过程中,比较常用的一个注解,用于映射请求参数. 代码 package rex.springmvc.handlers; import ...
- RAC OCR盘故障导致的集群重启恢复
一.事故说明 最近出现了一次OCR盘的故障导致Oracle集群件宕机的事故,后以独占模式启动集群,并使用ocr备份恢复了OCR文件以及重新设置了vote disk,然后关闭集群,重启成功. 因此在此处 ...
- (解决方法)Android studio 运行时报错Do you want to uninstall the existing application?的解决方法
在Android studio中,有时运行会报错: WARNING: Uninstalling will remove the application data!Do you want to unin ...
- Unix环境编程基础下
Unix出错处理 当UNIX系统的函数出错时,通常会返回一个负值.我们判断函数的返回值小于0表示出错了,注意我们并不知道为什么出错.例如我们open一个文件,返回值-1表示打开失败,但是为什么打开失败 ...
- js实现哈希表(HashTable)
在算法中,尤其是有关数组的算法中,哈希表的使用可以很好的解决问题,所以这篇文章会记录一些有关js实现哈希表并给出解决实际问题的例子. 第一部分:相关知识点 属性的枚举: var person = { ...
- Struts2的类型转换(上)
传统的类型转换.(略) Struts2中提供了内置的基本的类型转换器,可以实现基本类型的自动转换,包括: Integer, Float, Double, Decimal Date and Dateti ...
- 常用PHP函数整理
is_upload_file() 判断文件是不是通过HTTP POST 方式上传来的in_array() 判断变量在不在数组范围内move_uploaded_file() 将上传的临时名移到指定文件夹 ...
- Maven项目搭建(三):Maven直接部署项目
上一章给大家讲解了如何使用Maven搭建SSM框架项目. 这次给大家介绍一下怎么使用Maven直接部署项目. Maven直接部署项目 1.新建系统变量CATALINA_HOME,值为:Tom ...