Orleans的集群构建
Orleans的集群构建
这是Orleans系列文章中的一篇.首篇文章在此
听闻一周前,微软公布了.net core2.0,以及各种各样的其他core2.0.大家都很兴奋.微妈的诚意真是满满的.这次开源势头让我感觉到了微妈的技术实力之雄厚.我在这里祝福C#越来越好.细心的人似乎发现Orleans在github中是和net core分在一起的.Orleans的2.0何时发布呀…
现在我们面对的Orleans1.5(github上是1.6)已经是一个成熟的框架了.涉及到分布式的方方面面,我突然觉得我原来暂定的8篇文章都介绍不完全.我尽量介绍完整,至少让大家能入门,后边的修行就看大家自己的努力了.如果读者中有人能够和我分享,与我共同讨论我也是非常欢迎的.我的联系方式在第一篇文章中这里就不再复述了.
我现在利用<Orleans简单配置>文章中介绍的内容,配置一个可以分布式的silo,观察它们的行为.这里只介绍2种,其余的配置方式往读者自己研究.
我先说利用sql server数据库作为"服务自我发现"的服务
还是跟以前一样,我一步一步来.
基于SQL server的集群步骤
- 回顾之前的文章中在集群中客户端配置应该是这个模样:
<ClientConfiguration xmlns="urn:orleans">
<SystemStore SystemStoreType="SqlServer"
DeploymentId="target deployment ID"
DataConnectionString="SQL connection string"/>
</ClientConfiguration>
这里解释一下,还记得持久化中配置文件的主体是什么吗?对了是<StorageProviders>节.这个节的内容定义了Orleans在持久化时,要利用的存储中间件的各种参数.
而我们这里要利用的是<SystemStore>,它定义了与"系统"相关的变量应该存储在哪里.我只要定义好<SystemStore>后Orleans就会自动使用服务发现.
由于Orleans使用MembershipTable 来控制silo与silo的关系变化(谁加入了集群,谁离开了集群等等)如果配置好了<SystemStore>,这个MembershipTable就会存储在数据库中.所有的silo都要以数据库中的成员关系表为标准.这个表长成这个样子
其中有一个字段就是silo的地址.因此silo可以发现其他的silo,它们可以构成一个集群,而client可以发现集群内所有的silo.从而与集群互动.
- 按照以上讨论,我修改了一下配置文件.如下.
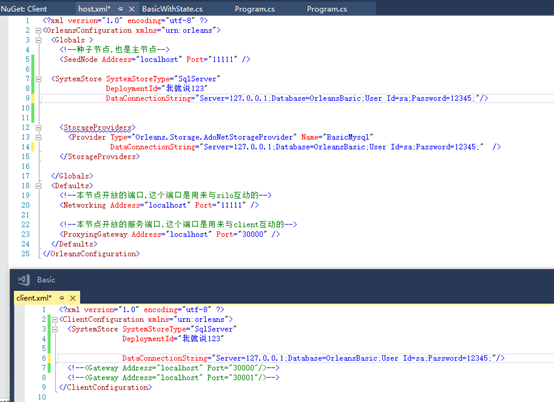
此处client也需要配置,因为client也需要读取成员关系表,以便知道所有silo的地址和状态.为了使client可以利用<SystemStore>必须在client里引用OrleansSQLUtils以及System.Data.SqlClient的包,
- 运行一下,就会有如下截图

- 再运行一个.找到host.exe,我们双击后再运行一个,会看到错误,这是因为silo配置文件中指明了一些端口,这些端口已经被第一个silo占用了,所以我修改一些host的配置文件,再次运行,会得到如下截图
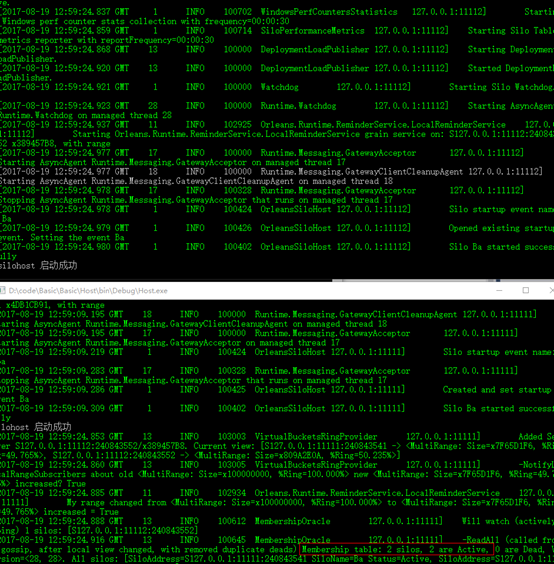
我们看到先启动的silo发现了新加入的silo.读者可以再次实验silo离开后的情况.
- 此时我让client运行,就会得到如下截图

可以看到client发送的消息均衡负载地再两个silo内执行.
至此一个基于sql server的简单silo集群就搭建完毕…这个集群虽然简单,但是满足所有高级的特性,扩展性和稳定性双优.是居家旅行的良好解决方案.只要有一个silo存活,这个集群就不会倒..
基于consul的集群
下文将介绍一下,另一个轻量级的集群实现.这个实现的步骤来自于官方教程.我再刚开始学习Orleans的时候,曾经使用这个步骤构建过集群.因为这个步骤是官方教程里一个最为详细的步骤,所以我就照做了.
1. 创建一个文件夹用来放置consul 比如 c:\consul.
2. 创建一个子文件夹放置数据 比如 c:\consul\data(consul不会自己创建.)
3. 下载并解压consul到c:\consul
4. 打开cmd,转至 c:\consul
5. 运行 Consul.exe agent -server -bootstrap -data-dir "C:\Consul\Data" -client=0.0.0.0
agent 指示consul新运行承载服务的代理进程,如果缺少这个参数 consul进程就尝试使用RPC来配置一个正在运行的代理进程
-server 指明这个代理进程是服务而不是client(一个consul client承载着所有的服务和数据,但是它没有权利投票,也没有可能成为consul集群领导)
-bootstrap consul集群中的第一个节点必须是有这个参数,它同时也是consul集群的领导.(单实例consule,,无所谓了)
-data-dir [path] 指明数据存储地址
-client=0.0.0.0 指明consule的服务地址
还有很多其他的consule参数.它们可以用json文件来配置,阅读consul文章来详细了解
确保consul已经运行了,请在浏览器里输入以下网址http://localhost:8500/v1/catalog/services 看看
6. 配置服务器
<OrleansConfiguration xmlns="urn:orleans">
<Globals>
<SystemStore SystemStoreType="None" DataConnectionString="http://localhost:8500" DeploymentId="MyOrleansDeployment" />
</Globals>
<Defaults>
<Networking Address="localhost" Port="22222" />
<ProxyingGateway Address="localhost" Port="30000" />
</Defaults>
</OrleansConfiguration>
并在host项目中的program.cs中,手动增加以下内容
silohost.Config.Globals.LivenessType = GlobalConfiguration.LivenessProviderType.Custom;
silohost.Config.Globals.MembershipTableAssembly = "OrleansConsulUtils";
silohost.Config.Globals.ReminderServiceType = GlobalConfiguration.ReminderServiceProviderType.Disabled;
silohost.InitializeOrleansSilo();
官方解释说: Consul的xml配置文件,Orleans在解析的时候有点小bug所以要在代码中控制一下.我在搭配的时候就采用了这个,但是我并没有验证此bug是否依然存在(官方教程是1.2的,我写的时候已经是1.5了).
好了这样一个基于consul的集群就构建好了.
经过以上的文章介绍,Orleans主要方面都或多或少的涉及到了,我写这系列文章的目的也快要达到了.除去一个方面,那就是eventSourcing.由于EventSourcinig是个复杂的事情,我需要组织语言,而且最近家里私事很多.也许下一篇文章放出的时候会很晚.因为接下来我没有太多时间.
Orleans的集群构建的更多相关文章
- 学习Hadoop+Spark大数据巨量分析与机器学习整合开发-windows利用虚拟机实现模拟多节点集群构建
记录学习<Hadoop+Spark大数据巨量分析与机器学习整合开发>这本书. 第五章 Hadoop Multi Node Cluster windows利用虚拟机实现模拟多节点集群构建 5 ...
- RabbitMQ从零到集群高可用(.NetCore5.0) -高可用集群构建落地
系列文章: RabbitMQ从零到集群高可用(.NetCore5.0) - RabbitMQ简介和六种工作模式详解 RabbitMQ从零到集群高可用(.NetCore5.0) - 死信队列,延时队列 ...
- [k8s]jenkins配合kubernetes插件实现k8s集群构建的持续集成
另一个结合harbor自动构建镜像的思路: 即code+baseimage一体的方案 - 程序员将代码提交到代码仓库gitlab - 钩子触发jenkins master启动一次构建 - jenkin ...
- spark集群构建
一.spark启动有standalong.yarn.cluster,具体的他们之间的区别这里不在赘述,请参考官网.本文采用的是standalong模式进行搭建及将接使用. 1.首先去官网下载需要的sp ...
- solr集群构建的基本流程介绍
先从第一台solr服务器说起:1. 它首先启动一个嵌入式的Zookeeper服务器,作为集群状态信息的管理者,2. 将自己这个节点注册到/node_states/目录下3. 同时将自己注册到/live ...
- RabbitMQ基础使用之集群构建
简介 RabbitMQ是基于Erlang开发的一种消息队列服务,本篇文章主要部署三台机器用来实现集群的普通模式与镜像模式!欢迎大家吐槽交流学习! 特点 集群节点包括内存节点和磁盘节点,有了磁盘节点就支 ...
- NATS_11:NATS集群构建与验证
NATS服务集群化 NATS支持每一个服务按照集群模式方式运行.你可以将这些服务组织在一起形成一个集群来提高服务器的容量的消息传递系统,并可以提升整个系统的弹性话和高可用性. 注意,NATS集群服务器 ...
- 分布式FastDfs+nginx缓存高可用集群构建
介绍: FastDFS:开源的高性能分布式文件系统:主要功能包括:文件存储,文件同步和文件访问,以及高容量和负载平衡 FastDFS:角色:跟踪服务器(Tracker Server).存储服务器(St ...
- activitmq+keepalived+nfs 非zk的高可用集群构建
nfs 192.168.10.32 maast 192.168.10.4 savel 192.168.10.31 应对这个需求既要高可用又要消息延迟,只能使用变态方式实现 nfs部署 #yum ins ...
随机推荐
- Linux - 请允许我静静地后台运行
h1,h2,h3,h4,h5,h6,p,blockquote { margin: 0; padding: 0 } body { font-family: "Helvetica Neue&qu ...
- s2-048远程代码执行漏洞
在Struts 2.3.x 系列的 Showcase 应用中演示Struts2整合Struts 1 的插件中存在一处任意代码执行漏洞.当你的应用使用了Struts2 Struts1的插件时,可能导致不 ...
- string can not be resolved
参考:http://jingyan.baidu.com/article/a17d5285339c828099c8f245.html
- Interlocked原子函数陷阱
一.问题 windows api函数中提供了InterlockedExchange.InterlockedDecrement, InterlockedIncrement, ExInterlockedA ...
- 在ASP.NET MVC中利用Aspose.cells 将查询出的数据导出为excel,并在浏览器中下载。
正题前的唠叨 本人是才出来工作不久的小白菜一颗,技术很一般,总是会有遇到一些很简单的问题却不知道怎么做,这些问题可能是之前解决过的.发现这个问题,想着提升一下自己的技术水平,将一些学的新的'好'东西记 ...
- JS操作字符串常用的方法
JS操作String对象的方法 charAt(index):返回指定索引处的字符串charCodeAt(index):返回指定索引处的字符的Unicode的值concat(str1,str2,...) ...
- 51nod_1253:Kundu and Tree(组合数学)
题目链接:https://www.51nod.com/onlineJudge/questionCode.html#!problemId=1253 全为红边的情况下,ans=C(n,3).假设被黑边相连 ...
- 图像处理与matlab实例之图像平滑(一)
一.何为图像噪声?噪声是妨碍人的感觉器官所接受信源信息理解的因素,是不可预测只能用概率统计方法认识的随机误差. 举个例子: 从这个图中,我们可以观察到噪声的特点:1>位置随机 2>大小不规 ...
- Spring AOP 和 动态代理技术
AOP 是什么东西 首先来说 AOP 并不是 Spring 框架的核心技术之一,AOP 全称 Aspect Orient Programming,即面向切面的编程.其要解决的问题就是在不改变源代码的情 ...
- web前端开发面试题(未完待续)
一.HTML与XHTML的不同:1)XHTML元素必须被正确地嵌套 2)元素必须被关闭 如:<h1>--</h1>关闭 3)标签名必须用小写字母 4)XHTML文档必须有根 ...