HDFS源码分析之NameNode(2)————Format
在Hadoop的HDFS部署好了之后并不能马上使用,而是先要对配置的文件系统进行格式化。在这里要注意两个概念,一个是文件系统,此时的文件系统在物理上还不存在,或许是网络磁盘来描述会更加合适;二就是格式化,此处的格式化并不是指传统意义上的本地磁盘格式化,而是一些清除与准备工作。本文接下来将主要讨论NameNode节点上的格式化。
我们都知道,NameNode主要被用来管理整个分布式文件系统的命名空间(实际上就是目录和文件)的元数据信息,同时为了保证数据的可靠性,还加入了操作日志,所以,NameNode会持久化这些数据(保存到本地的文件系统中)。对于第一次使用HDFS,在启动NameNode时,需要先执行-format命令,然后才能正常启动NameNode节点的服务。那么,NameNode的fromat命令到底做了什么事情呢?
hadoop namenode -format
在NameNode节点上,有两个最重要的路径,分别被用来存储元数据信息和操作日志,而这两个路径来自于配置文件,它们对应的属性分别是dfs.name.dir和dfs.name.edits.dir,同时,它们默认的路径均是/tmp/hadoop/dfs/name。格式化时,NameNode会清空两个目录下的所有文件,之后,会在目录dfs.name.dir下创建文件:
{dfs.name.dir}/current/fsimage
{dfs.name.dir}/current/fstime
{dfs.name.dir}/current/VERSION
{dfs.name.dir}/image/fsimage
会在目录dfs.name.edits.dir下创建文件:
{dfs.name.edits.dir}/current/edits
{dfs.name.edits.dir}/current/fstime
{dfs.name.edits.dir}/current/VERSION
{dfs.name.edits.dir}/image/fsimage
那么这些文件又是用来干什么的呢?
在介绍这文件的用途之前,我们可以将dfs.name.dir和dfs.name.edits.dir配置成相同的目录,这样的话,NameNode执行格式化之后,会产生如下的文件:{dfs.name.dir}/current/fsimage、{dfs.name.dir}/current/edits、{dfs.name.dir}/current/fstime、{dfs.name.dir}/current/VERSION、{dfs.name.dir}/image/fsimage,由此可以看出上面名字相同的文件实际是一样的,所以在这里,我建议把dfs.name.dir和dfs.name.edits.dir配置成相同的值,以来提高NameNode的效率。ok,现在就来重点的介绍一下这些文件的用途吧。
fsimage:存储命名空间(实际上就是目录和文件)的元数据信息,文件结构如下:

edits:用来存储对命名空间操作的日志信息,实现NameNode节点的恢复;
fstime:用来存储元数据上一次check point 的时间;
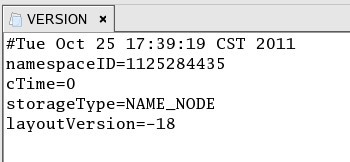
VERSION:用来存储NameNode版本信息,命名空间ID(版本号),内容如下:
/image/fsimage: 上一次提交前的/current/fsimage文件;
源码分析
执行源码位于NameNode类
case FORMAT: {
boolean aborted = format(conf, startOpt.getForceFormat(),
startOpt.getInteractiveFormat());
terminate(aborted ? 1 : 0);
return null; // avoid javac warning
}
.....
}
获取配置路径,执行初始化
具体的实现format的功能是在 org.apache.hadoop.hdfs.server.namenode.FSImage 这个类的format(StorageDirectory sd)方法中
FSImage fsImage = new FSImage(conf, nameDirsToFormat, editDirsToFormat);
try {
FSNamesystem fsn = new FSNamesystem(conf, fsImage);
fsImage.getEditLog().initJournalsForWrite(); if (!fsImage.confirmFormat(force, isInteractive)) {
return true; // aborted
} fsImage.format(fsn, clusterId);
} catch (IOException ioe) {
LOG.warn("Encountered exception during format: ", ioe);
fsImage.close();
throw ioe;
}
元数据的格式化
storage.format(ns);//执行下面的方法进行格式化
private void format(StorageDirectory sd) throws IOException {
sd.clearDirectory(); // create currrent dir
writeProperties(sd);
writeTransactionIdFile(sd, 0);
LOG.info("Storage directory " + sd.getRoot()
+ " has been successfully formatted.");
}
配置项
dfs.namenode.support.allow.format 是否允许进行Namenode format,默认是true
dfs.namenode.name.dir 元数据存储路径,这个参数用于确定将HDFS文件系统的元信息保存在什么目录下。
如果这个参数设置为多个目录,那么这些目录下都保存着元信息的多个备份,使用逗号分割,源码分隔符\\s*,\\s*。
dfs.namenode.edits.dir 操作日志存储路径
HDFS源码分析之NameNode(2)————Format的更多相关文章
- HDFS源码分析之NameNode(1)————启动过程
源码:2.8.0 入口类:org.apache.hadoop.hdfs.server.namenode.NameNode main方法会调用createNameNode 创建 NameNode 实例, ...
- HDFS源码分析:NameNode相关的数据结构
本文主要基于Hadoop1.1.2分析HDFS中的关键数据结构. 1 NameNode 首先从NameNode开始.NameNode的主要数据结构如下: NameNode管理着两张很重要的表: 1) ...
- HDFS源码分析之NameNode(3)————RpcServer
NameNodeRpcServer implements NamenodeProtocols NameNode支持核心即NameNodeRpcServer 实现ClientProtocol 支持客户 ...
- HDFS源码分析二-NameNode实现
2. NameNode 实现( 未完待续 )
- HDFS源码分析EditLog之读取操作符
在<HDFS源码分析EditLog之获取编辑日志输入流>一文中,我们详细了解了如何获取编辑日志输入流EditLogInputStream.在我们得到编辑日志输入流后,是不是就该从输入流中获 ...
- HDFS源码分析心跳汇报之数据块汇报
在<HDFS源码分析心跳汇报之数据块增量汇报>一文中,我们详细介绍了数据块增量汇报的内容,了解到它是时间间隔更长的正常数据块汇报周期内一个smaller的数据块汇报,它负责将DataNod ...
- HDFS源码分析之UnderReplicatedBlocks(一)
http://blog.csdn.net/lipeng_bigdata/article/details/51160359 UnderReplicatedBlocks是HDFS中关于块复制的一个重要数据 ...
- HDFS源码分析数据块校验之DataBlockScanner
DataBlockScanner是运行在数据节点DataNode上的一个后台线程.它为所有的块池管理块扫描.针对每个块池,一个BlockPoolSliceScanner对象将会被创建,其运行在一个单独 ...
- HDFS源码分析数据块复制监控线程ReplicationMonitor(一)
ReplicationMonitor是HDFS中关于数据块复制的监控线程,它的主要作用就是计算DataNode工作,并将复制请求超时的块重新加入到待调度队列.其定义及作为线程核心的run()方法如下: ...
随机推荐
- 23个适合Java开发者的大数据工具和框架
转自:https://www.yidianzixun.com/article/0Ff4gqZQ?s=9&appid=yidian&ver=3.8.4&utk=6n9c2z37 ...
- c++-STL:删除子串
void deletesub(string &str,const string &sub,int n) { int m,flag=0,num=0; //num是子串出现的次数 whil ...
- github如何添加ssh
1.运行git Bash 输入如下命令: $ cd ~/.ssh $ ls 输入这2个命令 ,我们可以看到 id_rsa.pub 或 id_dsa.pub 这2个文件已经存在了,id_rsa 是私钥, ...
- MyBatis框架——动态SQL、缓存机制、逆向工程
MyBatis框架--动态SQL.缓存机制.逆向工程 一.Dynamic SQL 为什么需要动态SQL?有时候需要根据实际传入的参数来动态的拼接SQL语句.最常用的就是:where和if标签 1.参考 ...
- 设置input的placeholder样式
自定义input默认placeholder样式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 inpu ...
- 九度OJ 1011 最长子串
#include <iostream> #include <string> #include <sstream> #include <math.h> u ...
- windows 下 Mutex和Critical Section 区别和使用
Mutex和Critical Section都是主要用于限制多线程(Multithread)对全局或共享的变量.对象或内存空间的访问.下面是其主要的异同点(不同的地方用黑色表示). Mutex Cri ...
- 201521123098 《Java程序设计》第1周学习总结
1. 本章学习总结 在本章的学习中,我和当初学习C语言一样由"Hello world"入手,初步了解了: 1. *NotePad++*的文件创建和编写*Hello world.ja ...
- 201521123066 《java程序设计》第一周学习总结
本周学习总结 (1)学习了Java的跨平台运行是因为有虚拟机,其特点是具有简单性,结构中立. (2)老师使用了新的作业模式,要学会发现其中的优势并好好学习使用. 书面作业 (1)为什么java程序可以 ...
- 201521123068 《java程序设计》第9周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常相关内容. 2. 书面作业 本次PTA作业题集异常 1.常用异常 题目5-1 1.1 截图你的提交结果(出现学号) 1.2 自己 ...