CHECKDB内部:什么是BlobEater?
DBCC CHECKDB注意到有关数据文件页面。一旦整个表的所有页(或一组表,如果配料已启用-看到同样的博客文章我上面提到的),所有的事实都聚集在一起,他们都应该相互抵消。当有额外的事实(在索引B树都指向同一个页面在一个较低的水平如两页),或丢失的事实(如LOB片段没有任何其他LOB片段或数据/索引记录指向它),则DBCC CHECKDB可以告诉有一个腐败。
由于DBCC CHECKDB正在生成数据库基本上是随机页面所有这些因素(它读取物理顺序表中的页面,而不是逻辑顺序),必须有前聚集可以发生的事实的一些排序。这是使用查询处理器的所有驱动。在每个线程DBCC CHECKDB读取页面,生成的事实,并让他们给查询处理器进行排序和汇总。一旦所有的阅读完毕之后,事实再返还给内部并行线程DBCC CHECKDB找出损坏是否存在。
表明这一机制的画面看起来如下:
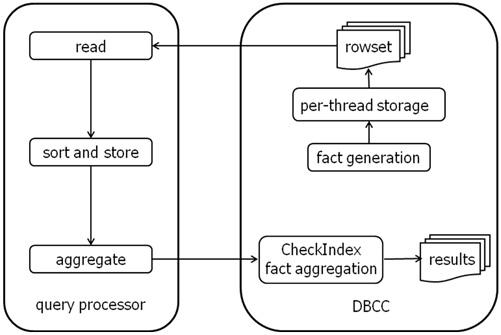
如果你正在做的任何跟踪或分析而DBCC CHECKDB正在运行时,你会看到下面的查询:
DECLARE @BlobEater VARBINARY(8000);
选择@BlobEater = CheckIndex(ROWSET_COLUMN_FACT_BLOB)
FROM <其实行集的内存地址>
GROUP BY ROWSET_COLUMN_FACT_KEY
>>带有ORDER BY
ROWSET_COLUMN_FACT_KEY,
ROWSET_COLUMN_SLOT_ID,
ROWSET_COLUMN_COMBINED_ID,
ROWSET_COLUMN_FACT_BLOB
OPTION(ORDER GROUP);
这个查询的部分的解释里面的SQL Server 2008中记录和即将里面的SQL Server 2012的书,我已经从我的DBCC内幕章下面引用它:
该查询带来的查询处理器和DBCC CHECKDB代码一起执行事实生成,事实排序,事实存储和事实聚集算法。是查询的部分如下:
- @BlobEater这是一个没有以外的其他使用来自任何输出目的的虚拟变量CheckIndex功能(永远不应该有任何,但语法要求的话)。
- CheckIndex(ROWSET_COLUMN_FACT_BLOB)这里面自定义聚合函数DBCC CHECKDB,查询处理器排序和分组的事实为整个事实聚集算法的一部分调用。
- <其实行集的内存地址>这是OLEDB行集的内存地址DBCC CHECKDB提供给查询处理器。查询处理器查询此行集行(包含生成的事实)作为整个事实生成算法的一部分。
- GROUP BY ROWSET_COLUMN_FACT_KEY这触发了查询处理器的聚集。
- >>带有ORDER BY <字段列表>这是仅供内部使用,提供了有序的聚合,凝聚工序语法。正如我先前所解释的,DBCC CHECKDB聚合代码是基于这样的假设,从查询处理器事实的凝集流的顺序被强制(即,它要求每个组内的键的排列顺序是顺序在查询中的四个键)。
- OPTION(订单组)这是一个查询优化器暗示的力量流聚集。它迫使查询优化器进行排序分组列,避免哈希聚集。
CHECKDB内部:什么是BlobEater?的更多相关文章
- sqlserver和Oracle内部的错误数据修复(DBCC、DBMS_REPAIR)
数据库长时间运行后,因断电.操作系统.物理存储等的原因可能会造成数据库内部的逻辑或物理错误,我们可以使用一般的方式尝试修复. 对于sqlserver 我们可以使用DBCC命令: -- sqlserve ...
- 如何在大型的并且有表分区的数据库中进行DBCC CHECKDB操作
如何在大型的并且有表分区的数据库中进行DBCC CHECKDB操作 其实这个问题已经在<SQLSERVER企业级平台管理实践>里徐老师已经讲过了,不过我想用自己的语言再讲详细一些 笔记链接 ...
- 通过ProGet搭建一个内部的Nuget服务器
.NET Core项目完全使用Nuget 管理组件之间的依赖关系,Nuget已经成为.NET 生态系统中不可或缺的一个组件,从项目角度,将项目中各种组件的引用统统交给NuGet,添加组件/删除组件/以 ...
- 微软Azure 经典模式下创建内部负载均衡(ILB)
微软Azure 经典模式下创建内部负载均衡(ILB) 使用之前一定要注意自己的Azure的模式,老版的为cloud service模式,新版为ARM模式(资源组模式) 本文适用于cloud servi ...
- 简单搭建 nuget 内部服务器
搭建 nuget 内部服务器,最好的方式是使用 ProGet,参考博文<用 ProGet 搭建内部的 NuGet 服务器>,好处非常多,但需要使用 SQL Server 数据库,如果不想使 ...
- 用ProGet搭建内部的NuGet服务器
最近团队内部用的一个很简陋的NuGet服务器出问题了,nuget push发包,客户端显示发布成功,服务器上就是没有.懶得再去排查这个问题,早就想换掉这个过于简陋的NuGet服务器,借此机会直接弃旧迎 ...
- topshelf和quartz内部分享
阅读目录: 介绍 基础用法 调试及安装 可选配置 多实例支持及相关资料 quartz.net 上月在公司内部的一次分享,现把PPT及部分交流内容整理成博客. 介绍 topshelf是创建windows ...
- Storm内部的消息传递机制
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 一个Storm拓扑,就是一个复杂的多阶段的流式计算.Storm中的组件 ...
- 如何开发一款堪比APP的微信小程序(腾讯内部团队分享)
一夜之间,微信小程序刷爆了行业网站和朋友圈,小程序真的能如张小龙所说让用户"即用即走"吗? 其功能能和动辄几十兆安装文件的APP相比吗? 开发小程序,是不是意味着移动应用开发的一次 ...
随机推荐
- 网页设计——5.table布局
今天做一个大的页面,主要是对table布局的理解: 代码: <table cellspacing=0 border=1 style="bordercolor:#C0C0C0;" ...
- 《RabbitMQ Tutorial》译文 第 3 章 发布和订阅
原文来自 RabbitMQ 英文官网的教程(3.Publish and Subscribe),其示例代码采用了 .NET C# 语言. In the previous tutorial we crea ...
- dom4j详解
Dom4j下载及使用Dom4j读写XML简介要使用dom4j读写XML文档,需要先下载dom4j包,dom4j官方网站在 http://www.dom4j.org/目前最新dom4j包下载地址:htt ...
- Tomcat 源码分析(一)——启动与生命周期组件
写在前面的话:读Tomcat源码也有段时间了,大领悟谈不上.一些小心得记录下来,供大家参考相护学习. 一.启动流程 Tomcat启动首先需要熟悉的是它的启动流程.和初学者第一天开始写Hello Wor ...
- 数据结构与算法(C/C++版)【树与二叉树】
第六章<树与二叉树> 树结构是一种非线性存储结构,存储的是具有"一对多"关系的数据元素的集合. 结点: A.B.C等,结点不仅包含数据元素,而且包含指向子树的分支.例如 ...
- Android安全专项-利用androguard分析微信
androguard Androguard经常使用API学习1 安装 做 Android 安全測试之前你应该知道的工具 (一) 分析 ./androlyze.py -s进入分析的交互界面 然后运行 a ...
- 使用milang出错:LookupError: unknown encoding: idna
今天同事安装了milang,结果发现例如以下出错: Traceback (most recent call last): File "F:\vmid.py", line 11, i ...
- 浅谈MySQL中的查询优化
mysql的性能优化包罗甚广: 索引优化,查询优化,查询缓存,服务器设置优化,操作系统和硬件优化,应用层面优化(web服务器,缓存)等等.这里的记录的优化技巧更适用于开发人员,都是从网络上收集和自己整 ...
- 前端(各种demo)三:优惠券,热区,等模块的实现(css方式)
各种样式的css实现 1.优惠券样式的实现: 2.热区的实现: 在电商平台上总会发出各种券,需要对应到不同的产品,对应到不同的服务.而使用券可以使用UED的设计稿里的照片,但是本来一次性的加载过多 ...
- CSS实现文字换行
强制不换行:div{ white-space:nowrap; } 自动换行: div{ word-wrap:break-word; word-break:normal; } 强制不换行 white-s ...