SQL菜鸟学习札记(一)
刚开始学SQL,从最基础的语句开始写,用一个LOL数据库做实验。目前使用的工具是MySQL Workbench,感觉比较顺手,界面没花多久时间就读懂的差不多了,所以目前就使用这个工具来做SQL的学习了。
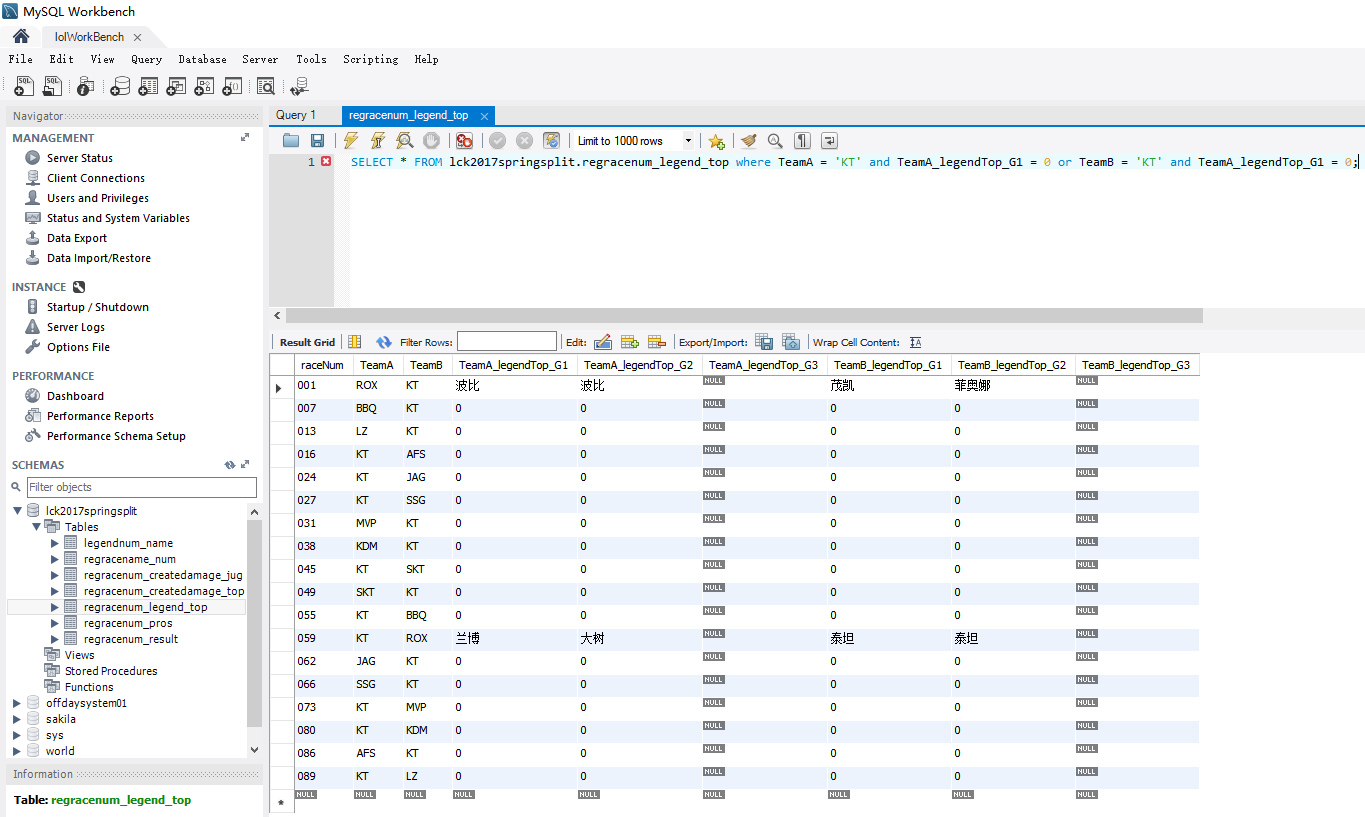
(1)多条件查询,然后修改值。因为我这里是需要编辑原来是0值的行,所以多条件查询中使用的是 A = 0为条件搜索。

刚刚提到的0值行就是这个样子,刚开始Copy行的时候遇到了很奇葩的错误——有些行必须存在默认值才能将数据进行表与表之间的Copy和Paste,所以就给默认值放了个0值。
(2)仔细琢磨了之前这个BUG,是自己刚开始处理的太复杂了,直接把NOT NULL的Option取消了,就不会报这个错误了,默认值就成了NULL。
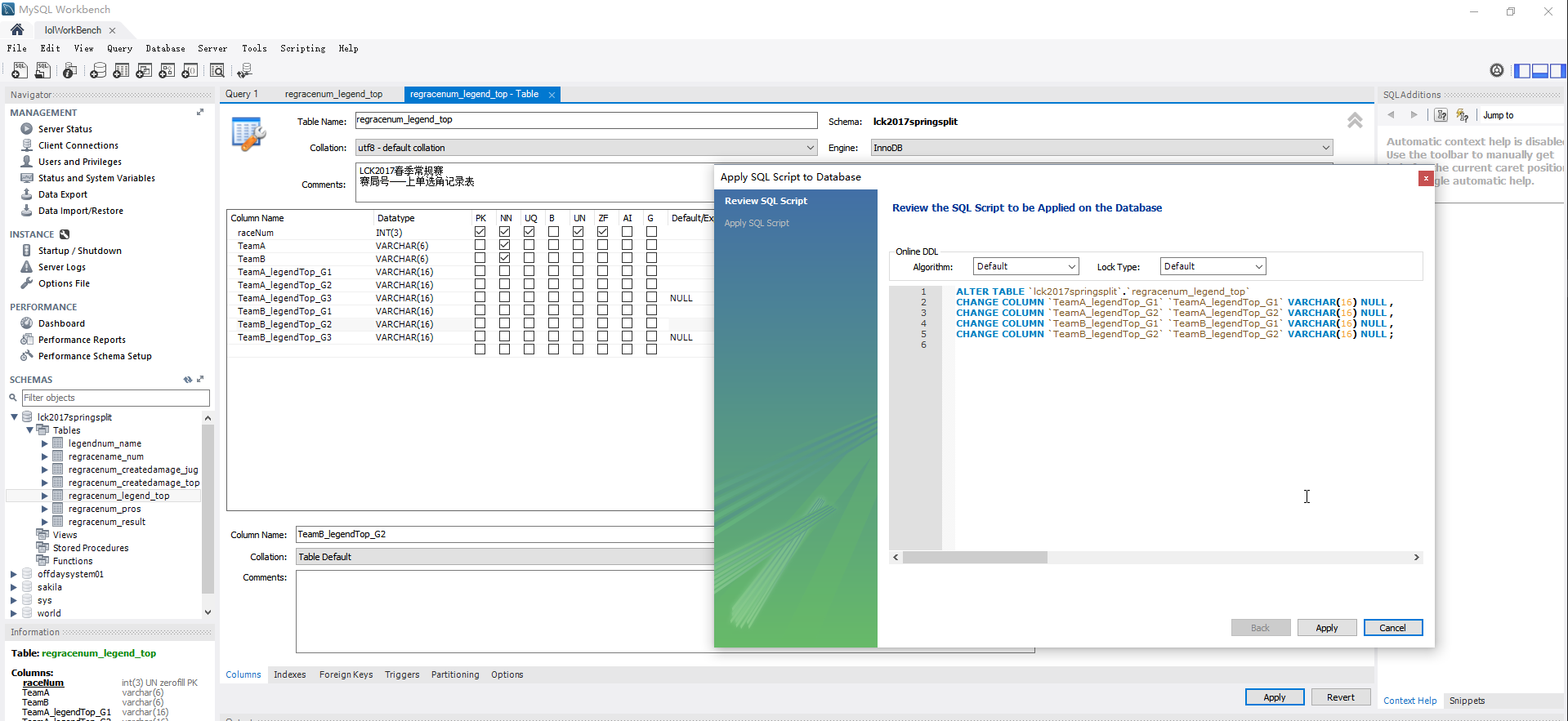
然后这里出现了更奇葩的东西,直接清除0值,并不能将值置为NULL,而是将值变成了 ‘’ ,即不能算作空格,也没有长度的一个值,所以表格上没有NULL的标识。

这个连带出的问题就是,以NULL为搜索条件,是查不出来这些值为 ‘’ 的行的。

我异想天开,‘’既然没有长度,那我就用length函数来搜索,结果会是什么样子呢?果然,这些包括这个值的行都被搜索出来了,因为这个奇特的值长度为0,小于1。

因为要录入这部分的所有数据,只能按传统方法,认栽。
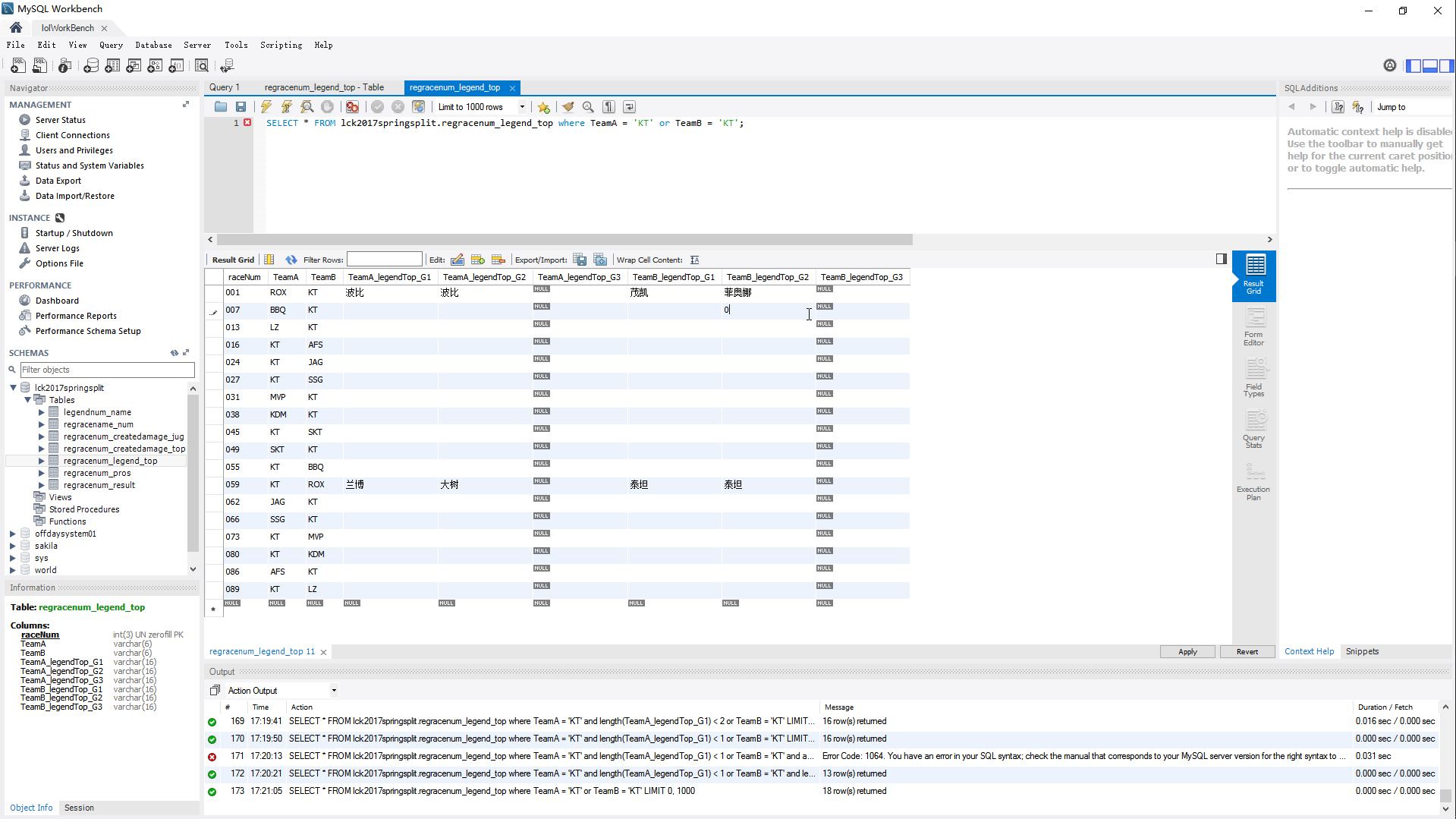
看了一下后台,之前不太理解主键和改值SQL的关系,原来是通过WHERE将主键与修改的元组,修改的元组中的某个值建立关联的。
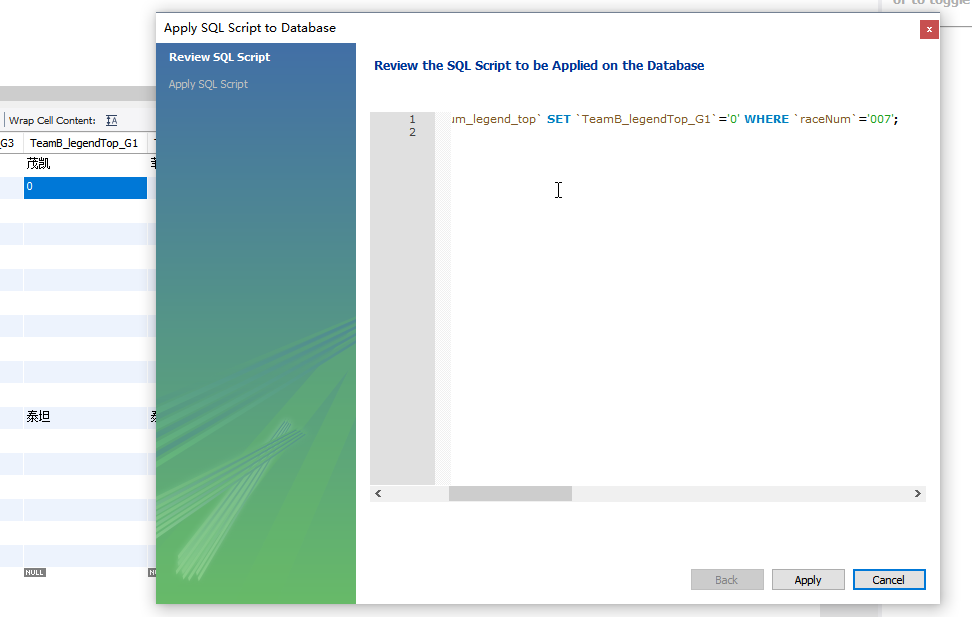
这个奇特的值的后台就在这里,这个 ‘’ 值真是能让人记住了。

这个NULL值还是要这么赋予,点击某个值,Set Field to NULL,这样就能有NULL的左上角标识了。

(3)4月26号写了第一个利用内联(inner join)来批量复制列的语句。内联就是A,B两个表格在某列拥有共性(至少有一个值相匹配)的情况下,建立连接。这个值通常就是主键了,因为一个表的数据录入通常都是主键开始的。

之后学了不少复制列的方法,又忘了这个经典方法,真是不应该。这也说明,学SQL真的得学会回溯过去的语句,否则花时间一直学新方法效率太低了,还增加无谓的学习负荷。
——————分隔线——————
(4)26号还写了第一个返回多列值的多表连接查询。语法不太难,SELECT A FROM B 还是基础框架,在这里 A 表示的就是多个表,简记为a.ELEMENT1,b.ELEMENT2,c.ELEMENT3.....。既然这里用到了a,b,c...来做简记,后面肯定还需要逐一补充说明,a表是指的哪个表,b表是指的哪个表...。(PS:这段代码就是不够优雅,看起来很乱,左边的几个‘X’也是让我看的心惊胆战,不过幸好跑成功了,也算没白写小半天)
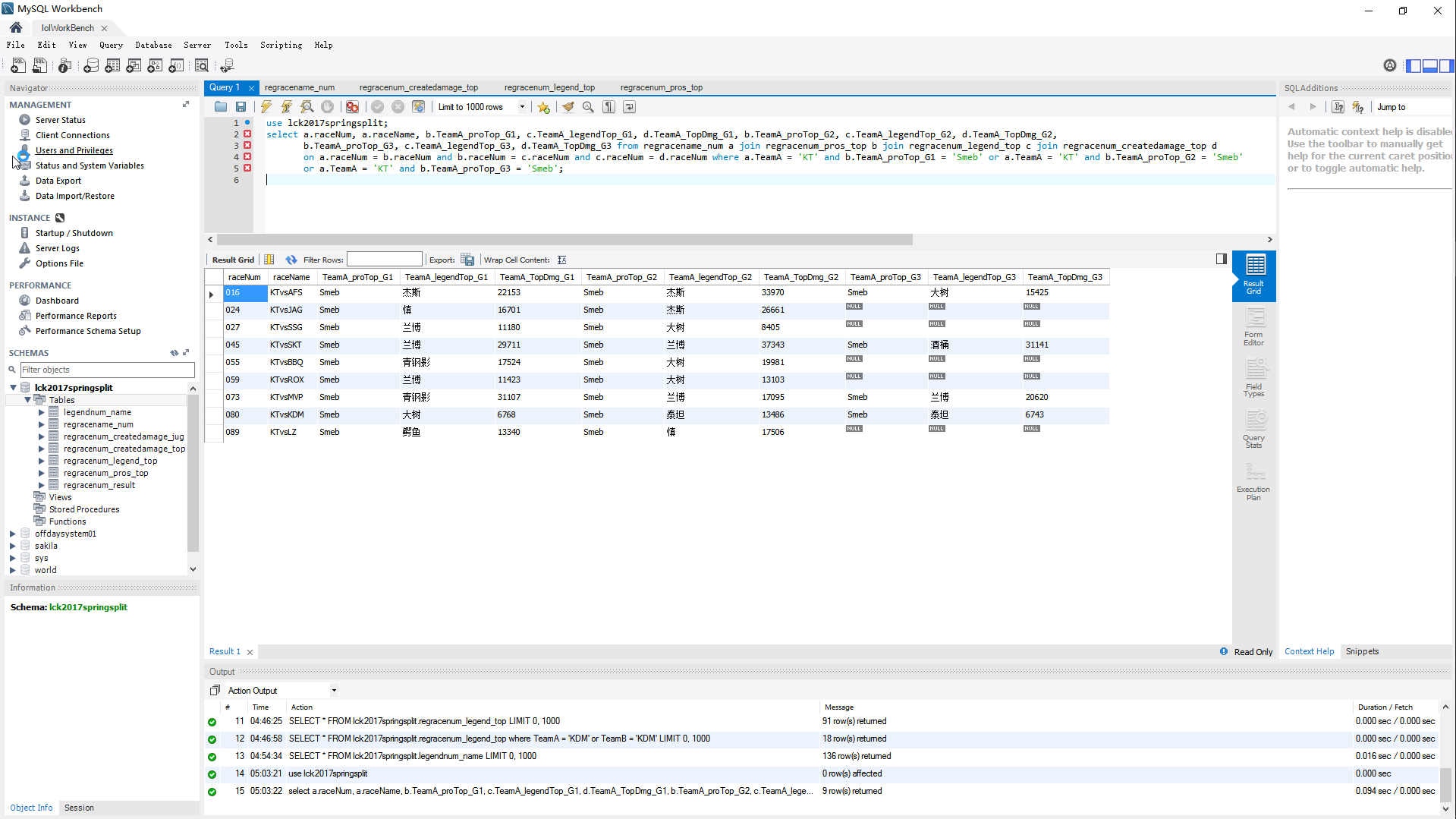
进阶型的多表连接查询,这次整体看起来就很优美了。没有学习SQL的时候我还一直怀疑数据库存在的意义,现在算是明白了,数据分类存放,建立关联,取出和阅读起来真的比传统的Excel要容易和方便许多。由于关联的存在,数据的修改也更容易快速同步。

(5)对表格中列的拖动,在SQL中的反映就是AFTER。比如C AFTER B;B AFTER A;那么最后表格列的顺序(从左到右)就是 A B C。AFTER出现的位置在语句最后,分号之前,和COMMENT的位置是差不多的。

(6)以前都是单表单值或者多表单值查询,对多值的查询也是分开写,效率感觉不高,因为同一个语句要用 OR 和 AND 连接几次,很费时间。后来知道 IN 这个关键字,省事了许多。

顺带get了DISTINCT的使用方法。SELECT DISTINCT(A) 就是去掉重复的 A 值,当然,这个去掉是要建立在元组完全相同的情况下的。这个表里面由于studentNum和lessonNum是联合主键,所以是没法用DISTINCT过滤的,因为各个主键(这里指联合主键)都是不同的,即实际存在的主键都是(a,b)(a,c)(b,c)(b,d)这样的形式,各自不同,自然就不能用DISTINCT过滤其中一个值包含的重复值。

(7)暴力复制表数据,INSERT INTO 语句很好用,也是第一次知道 SELECT FROM 语句可以这么嵌套。

——————分隔线——————
SQL这门语言真的越学越有趣,也很实用,毕竟以后大数据的适用范围会越来越广,所以数据库会是必备的技术。
第一次菜鸟学习札记也记录完了~道阻且长,给自己加油!
顺便在最后贴上之前提到的多表连接的查询语句。
use lck2017springsplit;
select a.raceNum, a.raceName, b.TeamA_proTop_G1, c.TeamA_legendTop_G1, d.TeamA_TopDmg_G1,
b.TeamA_proTop_G2, c.TeamA_legendTop_G2, d.TeamA_TopDmg_G2,
b.TeamA_proTop_G3, c.TeamA_legendTop_G3, d.TeamA_TopDmg_G3,
b.TeamB_proTop_G1, c.TeamB_legendTop_G1, d.TeamB_TopDmg_G1,
b.TeamB_proTop_G2, c.TeamB_legendTop_G2, d.TeamB_TopDmg_G2,
b.TeamB_proTop_G3, c.TeamB_legendTop_G3, d.TeamB_TopDmg_G3 from regracename_num a join regracenum_pros_top b join regracenum_legend_top c join regracenum_createdamage_top d
on a.raceNum = b.raceNum and b.raceNum = c.raceNum and c.raceNum = d.raceNum where a.TeamA = 'KT' and b.TeamA_proTop_G1 = 'Smeb' or
a.TeamA = 'KT' and b.TeamA_proTop_G2 = 'Smeb' or
a.TeamA = 'KT' and b.TeamA_proTop_G3 = 'Smeb' or
a.TeamB = 'KT' and b.TeamB_proTop_G1 = 'Smeb' or
a.TeamB = 'KT' and b.TeamB_proTop_G2 = 'Smeb' or
a.TeamB = 'KT' and b.TeamB_proTop_G3 = 'Smeb' ;
use lck2017springsplit;
select a.raceNum, a.raceName, b.TeamA_proTop_G1, c.TeamA_legendTop_G1, d.TeamA_TopDmg_G1,
b.TeamA_proTop_G2, c.TeamA_legendTop_G2, d.TeamA_TopDmg_G2,
b.TeamA_proTop_G3, c.TeamA_legendTop_G3, d.TeamA_TopDmg_G3,
b.TeamB_proTop_G1, c.TeamB_legendTop_G1, d.TeamB_TopDmg_G1,
b.TeamB_proTop_G2, c.TeamB_legendTop_G2, d.TeamB_TopDmg_G2,
b.TeamB_proTop_G3, c.TeamB_legendTop_G3, d.TeamB_TopDmg_G3 from regracename_num a join regracenum_pros_top b join regracenum_legend_top c join regracenum_createdamage_top d
on a.raceNum = b.raceNum and b.raceNum = c.raceNum and c.raceNum = d.raceNum where a.TeamA = 'KT' and b.TeamA_proTop_G1 = 'Smeb' and c.TeamA_legendTop_G1 = '兰博' or
a.TeamA = 'KT' and b.TeamA_proTop_G2 = 'Smeb' and c.TeamA_legendTop_G2 = '兰博' or
a.TeamA = 'KT' and b.TeamA_proTop_G3 = 'Smeb' and c.TeamA_legendTop_G3 = '兰博' or
a.TeamB = 'KT' and b.TeamB_proTop_G1 = 'Smeb' and c.TeamB_legendTop_G1 = '兰博' or
a.TeamB = 'KT' and b.TeamB_proTop_G2 = 'Smeb' and c.TeamB_legendTop_G2 = '兰博' or
a.TeamB = 'KT' and b.TeamB_proTop_G3 = 'Smeb' and c.TeamB_legendTop_G3 = '兰博' ;
SQL菜鸟学习札记(一)的更多相关文章
- SQL菜鸟学习札记(二)
五月份一直在写SQL,之后写了一个期末大作业的项目,现在才有时间把之前遇到的各种奇怪的问题整理出来.下一部分札记应该是大作业中使用到的SQL的整理. 一.UPDATE SET语句后面可以并列赋值. 之 ...
- Spark菜鸟学习营Day5 分布式程序开发
Spark菜鸟学习营Day5 分布式程序开发 这一章会和我们前面进行的需求分析进行呼应,完成程序的开发. 开发步骤 分布式系统开发是一个复杂的过程,对于复杂过程,我们需要分解为简单步骤的组合. 针对每 ...
- Spark菜鸟学习营Day3 RDD编程进阶
Spark菜鸟学习营Day3 RDD编程进阶 RDD代码简化 对于昨天练习的代码,我们可以从几个方面来简化: 使用fluent风格写法,可以减少对于中间变量的定义. 使用lambda表示式来替换对象写 ...
- Spark菜鸟学习营Day2 分布式系统需求分析
Spark菜鸟学习营Day2 分布式系统需求分析 本分析主要针对从原有代码向Spark的迁移.要注意的是Spark和传统开发有着截然不同的思考思路,所以我们需要首先对原有代码进行需求分析,形成改造思路 ...
- sql server学习路径地址
联机丛书2005:https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2005/ms130214(v=sql.90) 联 ...
- SQL server学习
慕课网sql server学习 数据库第一印象:desktop--web server--database server** 几大数据库:sql server.oracle database.DB2. ...
- 【菜鸟学习jquery源码】数据缓存与data()
前言 最近比较烦,深圳的工作还没着落,论文不想弄,烦.....今天看了下jquery的数据缓存的代码,参考着Aaron的源码分析,自己有点理解了,和大家分享下.以后也打算把自己的jquery的学习心得 ...
- SQL语句学习手册实例版
SQL语句学习手册实例版 表操作 例1 对于表的教学管理数据库中的表 STUDENTS ,可以定义如下: CREATE TABLE STUDENTS (SNO NUMERIC (6, ...
- SQL索引学习-聚集索引
这篇接着我们的索引学习系列,这次主要来分享一些有关聚集索引的问题.上一篇SQL索引学习-索引结构主要是从一些基础概念上给大家分享了我的理解,没有实例,有朋友就提到了聚集索引的问题,这里列出来一下: 其 ...
随机推荐
- [补档]暑假集训D8总结
%dalao 今天有两位大佬来讲课,meaty来讲了Catalan(本来说好的莫比乌斯反演呢),聪聪来讲Splay呢 至于听课笔记= =,没来得及记= = 不过好不想上树啊,上了树就下不来了 考试 仍 ...
- 快慢指针实现不依赖计数器寻找中位数(linked list)
该方法在不借助计数器变量实现寻找中位数的功能.原理是:快指针的移动速度是慢指针移动速度的2倍,因此当快指针到达链表尾时,慢指针到达中点.程序还要考虑链表结点个数的奇偶数因素,当快指针移动x次后到达表尾 ...
- 压缩[SCOI2007]
题目描述 给一个由小写字母组成的字符串,我们可以用一种简单的方法来压缩其中的重复信息.压缩后的字符串除了小写字母外还可以(但不必)包含大写字母R与M,其中M标记重复串的开始,R重复从上一个M(如果当前 ...
- Fiddler基础使用二之捕获手机应用https请求
Fiddler是一款非常流行并且实用的http抓包工具,它的原理是在本机开启了一个http的代理服务器,然后它会转发所有的http请求和响应, 因此,它比一般的firebug或者是chrome自带的抓 ...
- 实现wpf的值转换器
从数据库取出来的数据是1,2,3,4,5,不过要显示在控件上的,是1,2,3,4,5对应的string值,怎么办?wpf提供了很好的实现方法,那就是值转换器,我们需要做的是: 1.定义值转换类,继承I ...
- Python初学时购物车程序练习实例
不多说了,直接上代码: #Author:Lancy Wu product_list=[ ('Iphone',5800), ('Mac Pro',9800), ('Bike', 800), ('Watc ...
- Java 库:为 Java 程序员而生的 10 + 最佳库
众所周知,Java 的生态环境相当庞大,包含了数量相当可观的官方及第三方库.利用这些库,可以解决在用 Java 开发时遇到的各类问题,让开发效率得到显著提升. 举些例子,最常用的官方库有 java.l ...
- 某安寿险HR核人面试问题总结,技术面波澜不惊,HR面反而有被暴击感
之前朋友推荐了某安寿险的技术类职位.经过IQ/EQ网上笔试,技术面之前的java基础笔试和技术面试,基本上没什么意外的.昨天晚上7点安排的HR核人面试(他们的人力部门的工作负荷比较大,目前这个部门处于 ...
- Java入门——(1)Java编程基础
Java入门--(1)Java编程基础 第二章 Java编程基础 JAVA 代码的基本格式: 修饰符 class 类名{ 程序代码 } 2.1关键字:赋予了特殊含义的单词. 2.2标识符: ...
- wpf mvvm datagrid DataGridTemplateColumn的绑定无效的可能原因之一!
昨天在mvvm wpf的开发中遇到一个问题,绑定不起作用,编辑阶段没问题也没有提示找不到对应的绑定,但是在运行之后却不起作用,查了很多资料,说法不一,有些是要删除datagrid的一行,直接绑定del ...