Workout Wednesday Redux (2017 Week 3)
I had started a “52 Vis” initiative back in 2016 to encourage folks to get practice making visualizations since that’s the only way to get better at virtually anything. Life got crazy, 52 Vis fell to the wayside and now there are more visible alternatives such as Makeover Mondayand Workout Wednesday. They’re geared towards the “T” crowd (I’m not giving a closed source and locked-in-data product any more marketing than two links) but that doesn’t mean R, Python or other open-tool/open-data communities can’t join in for the ride and learning experience.
This week’s workout is a challenge to reproduce or improve upon a chart by Matt Stiles. You should go to both (give them the clicks and eyeballs they both deserve since they did great work). They both chose a line chart, but the whole point of these exercises is to try out new things to help you learn how to communicate better. I chose to use geom_segment() to make mini-column charts since that:
- eliminates the giant rose-coloured rectangles that end up everywhere
- helps show the differences a bit better (IMO), and
- also helps highlight some of the states that have had more difficulties than others
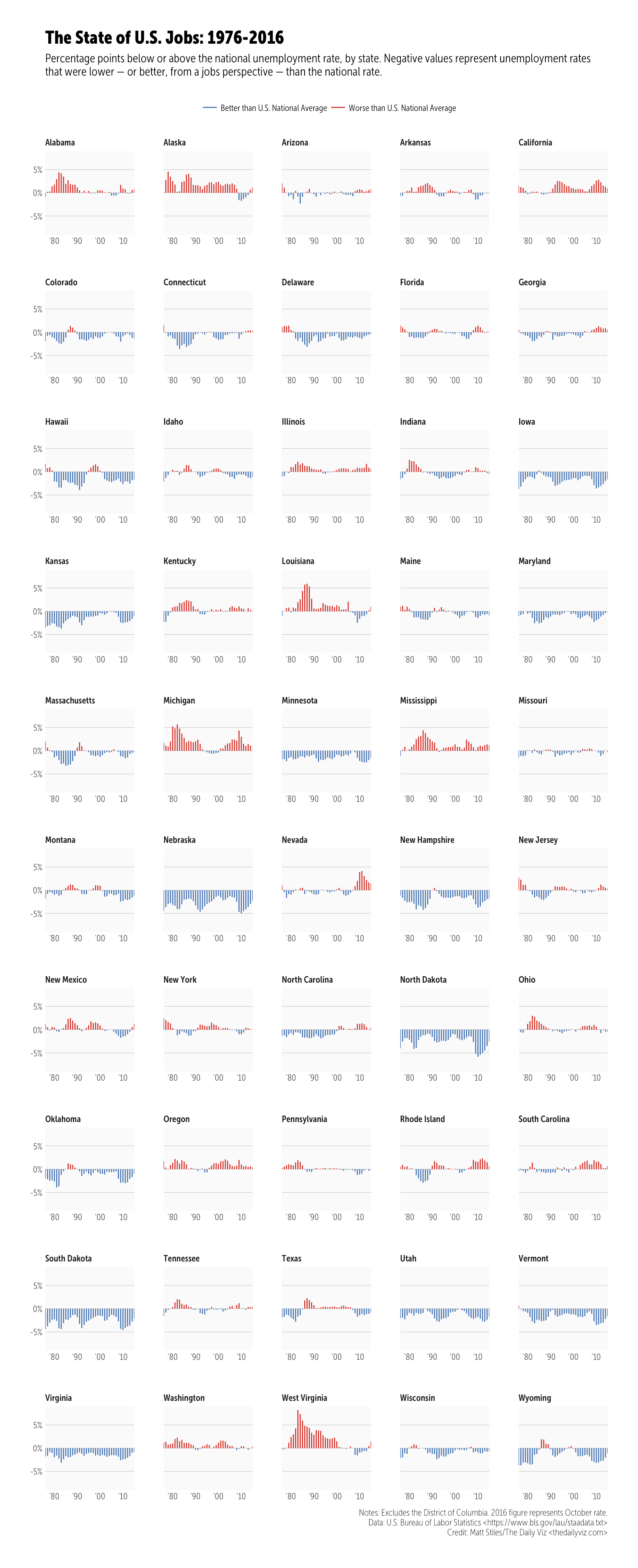
Click/tap to “embiggen”. I kept the same dimensions that Andy did but unlike Matt’s creation this is a plain ol’ PNG as I didn’t want to deal with web fonts (I’m on a Museo Sans Condensed kick at the moment but don’t have it in my TypeKit config yet). I went with official annual unemployment numbers as they may be calculated/adjusted differently (I didn’t check, but I knew that data source existed, so I used it).
One reason I’m doing this is a quote on the Workout Wednesday post:
This will be a very tedious exercise. To provide some context, this took me 2-3 hours to create. Don’t get discouraged and don’t feel like you have to do it all in one sitting. Basically, try to make yours look identical to mine.
This took me 10 minutes to create in R:
#' ---
#' output:
#' html_document:
#' keep_md: true
#' ---
#+ message=FALSE
library(ggplot2)
library(hrbrmisc)
library(readxl)
library(tidyverse)
# Use official BLS annual unemployment data vs manually calculating the average
# Source: https://data.bls.gov/timeseries/LNU04000000?years_option=all_years&periods_option=specific_periods&periods=Annual+Data
read_excel("~/Data/annual.xlsx", skip=10) %>%
mutate(Year=as.character(as.integer(Year)), Annual=Annual/100) -> annual_rate
# The data source Andy Kriebel curated for you/us: https://1drv.ms/x/s!AhZVJtXF2-tD1UVEK7gYn2vN5Hxn #ty Andy!
read_excel("~/Data/staadata.xlsx") %>%
left_join(annual_rate) %>%
filter(State != "District of Columbia") %>%
mutate(
year = as.Date(sprintf("%s-01-01", Year)),
pct = (Unemployed / `Civilian Labor Force Population`),
us_diff = -(Annual-pct),
col = ifelse(us_diff<0,
"Better than U.S. National Average",
"Worse than U.S. National Average")
) -> df
credits <- "Notes: Excludes the District of Columbia. 2016 figure represents October rate.\nData: U.S. Bureau of Labor Statistics <https://www.bls.gov/lau/staadata.txt>\nCredit: Matt Stiles/The Daily Viz <thedailyviz.com>"
#+ state_of_us, fig.height=21.5, fig.width=8.75, fig.retina=2
ggplot(df, aes(year, us_diff, group=State)) +
geom_segment(aes(xend=year, yend=0, color=col), size=0.5) +
scale_x_date(expand=c(0,0), date_labels="'%y") +
scale_y_continuous(expand=c(0,0), label=scales::percent, limit=c(-0.09, 0.09)) +
scale_color_manual(name=NULL, expand=c(0,0),
values=c(`Better than U.S. National Average`="#4575b4",
`Worse than U.S. National Average`="#d73027")) +
facet_wrap(~State, ncol=5, scales="free_x") +
labs(x=NULL, y=NULL, title="The State of U.S. Jobs: 1976-2016",
subtitle="Percentage points below or above the national unemployment rate, by state. Negative values represent unemployment rates\nthat were lower — or better, from a jobs perspective — than the national rate.",
caption=credits) +
theme_hrbrmstr_msc(grid="Y", strip_text_size=9) +
theme(panel.background=element_rect(color="#00000000", fill="#f0f0f055")) +
theme(panel.spacing=unit(0.5, "lines")) +
theme(plot.subtitle=element_text(family="MuseoSansCond-300")) +
theme(legend.position="top")Swap out ~/Data for where you stored the files.
The “weird” looking comments enable me to spin the script and is pretty much just the inverse markup for knitr R Markdown documents. As the comments say, you should really thank Andy for curating the BLS data for you/us.
If I really didn’t pine over aesthetics it would have taken me 5 minutes (most of that was waiting for re-rendering). Formatting the blog post took much longer. Plus, I can update the data source and re-run this in the future without clicking anything. This re-emphasizes a caution I tell my students: beware of dragon droppings (“drag-and-drop data science/visualization tools”).
Hopefully you presently follow or will start following Workout Wednesday and Makeover Monday and dedicate some time to hone your skills with those visualization katas.
转自:https://rud.is/b/2017/01/18/workout-wednesday-redux-2017-week-3/
Workout Wednesday Redux (2017 Week 3)的更多相关文章
- January 25 2017 Week 4 Wednesday
In every triumph, there's a lot of try. 每个胜利背后都有许多尝试. There's a lot of try behind every success, and ...
- November 15th, 2017 Week 46th Wednesday
Of all the tribulations in this world, boredom is the one most hard to bear. 所有的苦难中,无聊是最难以忍受的. When ...
- November 08th, 2017 Week 45th Wednesday
Keep your face to the sunshine and you cannot see the shadow. 始终面朝阳光,我们就不会看到黑暗. I love sunshine, but ...
- November 01st, 2017 Week 44th Wednesday
People always want to lead an active life, and is not it? 人们总要乐观生活,不是吗? Be active, and walk towards ...
- October 25th, 2017 Week 43rd Wednesday
Perseverance is not a long race; it is many short races one after another. 坚持不是一个长跑,她是很多一个接一个的短跑. To ...
- October 18th 2017 Week 42nd Wednesday
Only someone who is well-prepared has the opportunity to improvise. 只有准备充分的人才能够尽兴表演. From the first ...
- October 11th 2017 Week 41st Wednesday
If you don't know where you are going, you might not get there. 如果你不知道自己要去哪里,你可能永远到不了那里. The reward ...
- October 04th 2017 Week 40th Wednesday
We teach people how to remember, we never teach them how to grow. 我们教会人们如何记忆,却从来不教他们如何成长. Without pr ...
- September 27th 2017 Week 39th Wednesday
We both look up at the same stars, yet we see such different things. 我们仰望同一片星空,却看见了不同的事物. Looking up ...
随机推荐
- 学习面向对象编程OOP 第一天
面向对象编程 Object Oriented Programming 一.什么是面向对象编程OOP 1.计算机编程架构; 2.计算机程序是由一个能够起到子程序作用的单元或者对象组合而成.也就是说由多个 ...
- 实现全局同一编码:Filter
request.setCharacterEncoding("UTF-8");只对POST方式提交有用 对于GET方式 ,可以有装饰模式和适配器模式,对获取参数的函数进行重写. 对所 ...
- 利用原生JS判断组合键
<script type="text/javascript"> var isAlt = 0; var isEnt = 0; document.onkeydown = f ...
- 【PAT_Basic日记】1005. 继续(3n+1)猜想
#include <stdio.h> #include <stdlib.h> /** 逻辑上的清晰和代码上的清晰要合二为一 (1)首先在逻辑上一定要清晰每一步需要干什么, (2 ...
- AngularJS学习笔记4
9.AngularJS XMLHttpRequest $http 是 AngularJS 中的一个核心服务,用于读取远程服务器的数据. <div ng-app="myApp" ...
- 基于appium的移动端自动化测试,密码键盘无法识别问题
基于appium做自动化测试,APP密码键盘无法识别问题解决思路 这个问题的解决思路如下: 1.针对iOS无序键盘:首先,iOS的密码键盘是可识别的,但是,密码键盘一般是无序的.针对这个情况,思路是用 ...
- kNN算法个人理解
新手,有问题的地方请大家指教 训练集的数据有属性和标签 同类即同标签的数据在属性值方面一定具有某种相似的地方,用距离来描述这种相似的程度 k=1或则较小值的话,分类对于特殊数据或者是噪点就会异常敏感, ...
- C#如何向word文档插入一个新段落及隐藏段落
编辑Word文档时,我们有时会突然想增加一段新内容:而将word文档给他人浏览时,有些信息我们是不想让他人看到的.那么如何运用C#编程的方式巧妙地插入或隐藏段落呢?本文将与大家分享一种向Word文档插 ...
- [Git]02 如何简单使用
本章将介绍几个最基本的,也是最常用的 Git命令,以后绝大多数时间里用到的也就是这几个命令. 初始化一个新的代码仓库,做一些适当配置:开始或停止跟踪某些文件:暂存或提交某些更新.我们还会展示如何 ...
- Java Web实现IOC控制反转之依赖注入
控制反转(Inversion of Control,英文缩写为IoC)是一个重要的面向对象编程的法则来削减计算机程序的耦合问题,也是轻量级的Spring框架的核心. 控制反转一般分为两种类型,依赖注入 ...