Hadoop学习之旅一:Hello Hadoop
![]()
开篇概述
随着计算机网络基础设施的完善,社交网络和电商的发展以及物连网的推进,产生了越来越多的大数据,使得人工智能最近几年也有了长足的发展(可供机器学习的样本数据量足够大了),大数据的存储和处理也越来越重要,国家对此也比较重视(可上网搜索关键字“大数据白皮书”关键字,以了解详细情况),会长决定和年轻人也一块儿学习一下,于是报了网易云课堂的课程,不定时将学习到的东西整理为博客,此乃开篇。
学习大数据必先学习Hadoop,因为它是目前世界上最流行的分布式数据处理框架。
Tips:所谓大数据,是指数据量庞大、产生数度快、结构多样的价值密度低的数据。其中,数据量庞大是指数据规模超出了1,2台高性能主机所能处理范围;结构多样性是指除了关系型数据库能够处理的结构化数据还包含半结构化数据(如各类传感设备必如地镑、卫星、GPS设备等产生的纯文本格式的数据,还有良心网站NASA官网公布的txt格式的空间天气数据等成行成列的数据)和非结构化数据(视频、图像等)。这些数据的价值密度普遍较低(和具体的应用范围也有关系,比如NASA的数据,如果想知道某天的太阳射电情况,看当天发布的txt就好了,价值密度很高,但是这就不算大数据了,因为需要采集的数据量很小;如果想知道过去N年太阳射电的极值就需要处理很多数据,这些数据的价值密度就低了),大数据处理的目的就是从价值密度的数据里把有价值的数据过滤分析出来。
Hadoop概述
Hadoop是一个用于分布式大数据处理的编程框架。同时它也是个大数据处理完整的生态系统,围绕着Hadoop,这个生态系统还包括但不限于:
- HBase
- Hive
- Pig
- Spark
- ZooKeeper
希望本系列的写作能够坚持下去,对上述内容都有所涉及吧。
Hadoop能干什么
假设老王在某不知名IT公司工作,由于最近太阳活动异常,引起了领导的外甥的读硕士的同学的关注,领导让老王把山西铁岛太阳射电望远镜观测到的近30年的太阳射电数据下载下来,让老王从里面找到最高的记录。老王毕竟搞挨踢已有多年,虽然技术不行,终日碌碌无为,但多年的直觉告诉老王这个很简单。老王立刻下载了其中一个文件并大致看了文件的机构:数据保存在txt文件里,每行N列,其中包含了时间和数据信息列,大约每0.1s记录一条数据,一个文件记录15分钟的数据,大约有9000条记录,1个小时4个文件,1天96个文件,30年大约1051200个文件,一共大约100亿条数据,这其中还有一些损坏的文件,还有一些用9999表示的未检测到值的占位数据需要特殊照顾。
老王觉得单机处理这些数据耗时太久,于是老王找来一些公司淘汰下来的旧服务器(一般小公司最破的机器都是服务器),准备每个机器负责一部分,最后把结果汇总,老王在开发的过程中还是遇到了很多问题,比如,如何分配任务,有的机器破,有的机器新,还有的文件大,有的文件小,总是不能保证所有的任务一起完成,先完成任务的机器闲置浪费掉了资源;还有最后把结果通过网络通信汇总起来,如何保证数据不丢失,不覆盖;还有如果某台机器出了问题,如何重新分配任务,这些非核心业务的开发使得老王心力憔悴,还好,老王最后找到了Hadoop这个工具,这个工具给老王提供了一个简单的编程模型,老王在map方法中写了分配的任务的逻辑,在reduce方法中写了合并结果的逻辑,然后Hadoop帮老王完成了其他所有事情,Hadoop就是干这个的。以上故事纯属虚构,如有雷同,实属巧合。
其实上述意淫的例子里的数据量不是很大,如果每天产生上TB级别的数据,就算是速度很快的固态硬盘也需要小时级时间才能读取一遍,速度还是远远跟不上,终归有上限,而且高性能主机价格不菲,不如把数据分开放到一个相对廉价又可扩展的计算机集群中,每个节点上运行一段程序并处理一小块数据,然后在汇总处理结果,使用Hadoop可以让开发者不必把精力放在集群的建设上,采用Hadoop提供的简单的编程模型就可以实现分布式处理。
Hadoop的构造模块
Hadoop集群中运行的守护进程共有5类:
- NameNode
- DataNode
- Secondary NameNode
- JobTracker
- TaskTracker
Hadoop集群中的机器(节点)分为2类:主节点和从节点,NameNode、JobTracker所在节点为主节点(负责管理),DataNode和TaskTracker所在节点为从节点(负责干活儿)。
NameNode
NameNode节点负责将一个文件分成若干文件块,并记录了HDFS文件系统中的文件块放了在哪些DataNode中(一个数据块被冗余地放到1个或多个DataNode节点中),一个集群中只有一个NameNode节点(Hadoop2.X中情况有所不同了),且该节点通常不再运行DataNode和TaskTracker守护进程。
DataNode
DataNode实际管理很多NameNode分配给它的很多数据块,当有文件块变动时会通知NameNode,同时也从NameNode接受指令。一个集群中有多个DataNode节点,DataNode之间也会保持联系,复制冗余文件块,这样当一个DataNode出现故障后不会影响到文件的完整性。
Secondary NameNode
SNN只与NameNode通信,定时获取HDFS元数据的快照,一个集群只有一个SNN,且SNN所在节点只运行SNN守护进程,不干其它的事情。当NameNode出现故障后,可以人工启用SNN作为NameNode。
JobTracker
JobTracker负责分配MapReduce任务给TaskTracker,负责监控任务的执行,如任务失败后重启任务。JobTracker守护进程运行在主节点上,通常该节点不运行DataNode和TaskTracker守护进程。
TaskTracker
TaskTracker负责完成JobTracker分配的任务并和JobTranker进行通信,回报情况。TaskTracker守护进程运行在多个子节点上
看图说话
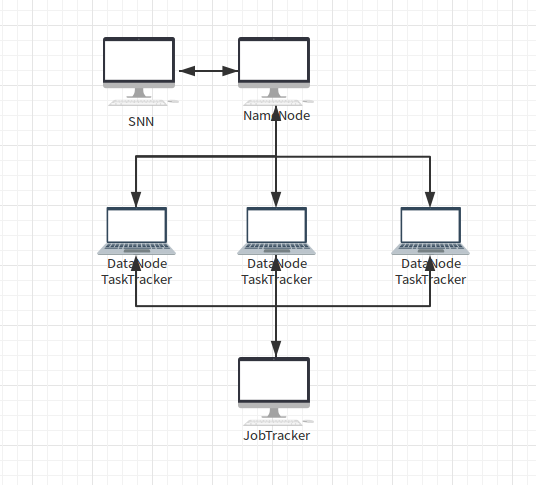
上图中,NameNode和JobTracker是分开的,如果集群规模不大也可以运行在同一个节点上(如果这个节点出现故障该如何恢复?)
安装Hadoop
在安装Hadoop之前需要先安装如下软件:
- JDK
- ssh
- sshd
- ssh-kengen
我用的是Ubuntu16.04,已经预装了ssh和ssh-kengen了,只需要安装jdk和sshd,可以通过执行命令which命令来检查是否安装了某软件,如which sshd
安装JDK8
下载压缩包解压即可:
sudo mkdir /usr/local/lib/jvm
sudo tar -zxv -f ~/setupFiles/jdk-8u101-linux-x64.tar.gz -C /usr/local/lib/jvm
配置环境变量:
修改 /etc/profile文件,追加:
export JAVA_HOME=/usr/local/lib/jvm/jdk1.8.0_101 export PATH=$JAVA_HOME/bin:$PATH
配置完毕后执行命令source /etc/profile,此刻通过echo $JAVA_HOME应该能看到刚才设置的了。
安装sshd
sudo apt install openssh-server
安装完了sshd后应该可以通过ssh lcoalhost命令远程访问了,但是需要输入密码,Hadoop集群节点间要进行通信需要配置为无密码登录方式。
无密码ssh登录设置
执行如下命令:
ssh-keygen -t rsacat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 0600 ~/.ssh/authorized_keys
其中,执行ssh-keygen命令时一路回车不要输入密码,执行完毕后会在/home/userName/.ssh路径下生成公钥和私钥id_rsa和id_rsa.pub。如果一切顺利的话,现在可以通过ssh localhost无密码登录了
安装Hadoop
我下载的是1.0.4版本(2.X版本和1.X版本有着很大的差别,还是先学会1.X再看2.X吧,我们的课程也是以1.X为例的,事实上我刚才下的2.X,发现很多东西不懂,又退回1.X了,
Hadoop学习之旅一:Hello Hadoop的更多相关文章
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- Hadoop学习之旅三:MapReduce
MapReduce编程模型 在Google的一篇重要的论文MapReduce: Simplified Data Processing on Large Clusters中提到,Google公司有大量的 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- hadoop学习之旅1
大数据介绍 大数据本质也是数据,但是又有了新的特征,包括数据来源广.数据格式多样化(结构化数据.非结构化数据.Excel文件.文本文件等).数据量大(最少也是TB级别的.甚至可能是PB级别).数据增长 ...
- Hadoop学习笔记(一)Hadoop的单节点安装
要想深入学习Hadoop分布式文件系统,首先需要搭建Hadoop的实验环境,Hadoop有两种安装模式,即单节点集群模式安装(也称为伪分布式)和完全分布式模式安装,本节只介绍单节点模式的安装,参考官方 ...
- hadoop 学习(二)ubuntu hadoop 2.7.0 伪分部安装
本篇是基于上一篇,ubuntu 安装hadoop单机版基础上的 1.配置core-site.xml /usr/local/hadoop/etc/hadoop/core-site.xml 包含了hado ...
- hadoop学习笔记(五)hadoop伪分布式集群的搭建
本文原创,如需转载,请注明作者和原文链接 1.集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点 2.解压tar.gz包 [root@node01 ~]# ...
- hadoop学习之旅2
集群搭建文档1.0版本 1. 集群规划 所有需要用到的软件: 链接:http://pan.baidu.com/s/1jIlAz2Y 密码:kyxl 2.0 系统安装 2.1 主机名配置 vi /etc ...
- Hadoop学习笔记(3)hadoop伪分布模式安装
为了学习这部分的功能,我们这里的linux都是使用root用户登录的.所以每个命令的前面都有一个#符号. 伪分布模式安装步骤: 关闭防火墙 修改ip地址 修改hostname 设置ssh自动登录 安装 ...
随机推荐
- div实现自适应高度的textarea,实现angular双向绑定
相信不少同学模拟过腾讯的QQ做一个聊天应用,至少我是其中一个. 过程中我遇到的一个问题就是QQ输入框,自适应高度,最高高度为3row. 如果你也像我一样打算使用textarea,那么很抱歉,你一开始就 ...
- QT5利用chromium内核与HTML页面交互
在QT5.4之前,做QT开发浏览器只能选择QWebkit,但是有过使用的都会发现,这个webkit不是出奇的慢,简直是慢的令人发指,Release模式下还行,debug下你就无语了,但是webkit毕 ...
- [原]Redis主从复制各种环境下测试
Redis 主从复制各种环境下测试 测试环境: Linux ubuntu 3.11.0-12-generic 2GB Mem 1 core of Intel(R) Core(TM) i5-3470 C ...
- 编写高质量代码:改善Java程序的151个建议(第8章:多线程和并发___建议126~128)
建议126:适时选择不同的线程池来实现 Java的线程池实现从根本上来说只有两个:ThreadPoolExecutor类和ScheduledThreadPoolExecutor类,这两个类还是父子关系 ...
- 微信小程序前端源码逻辑和工作流
看完微信小程序的前端代码真的让我热血沸腾啊,代码逻辑和设计一目了然,没有多余的东西,真的是大道至简. 废话不多说,直接分析前端代码.个人观点,难免有疏漏,仅供参考. 文件基本结构: 先看入口app.j ...
- Git分布式版本控制教程
Git分布式版本控制Git 安装配置Linux&Unix平台 Debian/Ubuntu $ apt-get install git Fedora $ ) $ dnf and later) G ...
- iOS之开发中一些相关的路径以及获取路径的方法
模拟器的位置: /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs ...
- can't run roscore 并且 sudo 指令返回 unable to resolve host
I'm using ubuntu14 LTS. Problems: 1. When run roscore, got a mistake and an advice to ping the local ...
- Linux初识
在这篇文章中你讲看到如下内容: 计算机的组成及功能: Linux发行版之间的区别和联系: Linux发行版的基础目录及功用规定: Linux系统设计的哲学思想: Linux系统上获取命令帮助,及man ...
- 枚举:enum
枚举 所谓枚举就是指定好取值范围,所有内容只能从指定范围取得. 例如,想定义一个color类,他只能有RED,GREEN,BLUE三种植. 使用简单类完成颜色固定取值问题. 1,就是说,一个类只能完成 ...