JDK1.8 HashMap中put源码分析
一、存储结构
在JDK1.8之前,HashMap采用桶+链表实现,本质就是采用数组+单向链表组合型的数据结构。它之所以有相当快的查询速度主要是因为它是通过计算散列码来决定存储的位置。HashMap通过key的hashCode来计算hash值,不同的hash值就存在数组中不同的位置,当多个元素的hash值相同时(所谓hash冲突),就采用链表将它们串联起来(链表解决冲突),放置在该hash值所对应的数组位置上。结构图如下:
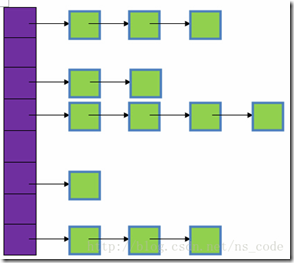
图中,紫色部分代表哈希表,也称为哈希数组,数组中每个元素都是一个单链表的头结点,链表是用来解决冲突的,如果不同的key映射得到了数组的同一位置处,就将其放入单链表。
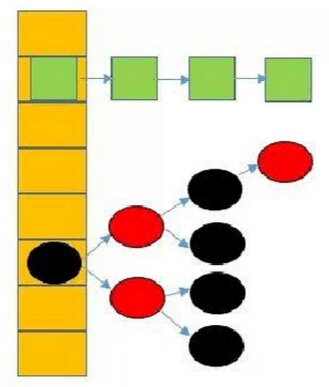
在JDK1.8中,HashMap的存储结构已经发生变化,它采用数组+链表+红黑树这种组合型数据结构。当hash值发生冲突时,会采用链表或者红黑树解决冲突。当同一hash值的结点数小于8时,则采用链表,否则,采用红黑树。这个重大改变,主要是提高查询速度。它的结构图如下:
二、put方法
之所以先介绍存储结构,是为了更好的理解put方法。
public put(K key, V value)
{
return putVal(hash(key), key, value, false, true);
}
put方法调用了putVal方法,那我们再来看看它。
/*
Parameters:
hash hash for key
key the key
value the value to put
onlyIfAbsent if true, don't change existing value
evict if false, the table is in creation mode.
Returns:
previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果table为空,或者还没有元素时,则扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 如果首结点值为空,则创建一个新的首结点。
// 注意:(n - 1) & hash才是真正的hash值,也就是存储在table位置的index。在1.6中是封装成indexFor函数。
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else { // 到这儿了,就说明碰撞了,那么就要开始处理碰撞。
Node<K,V> e; K k;
// 如果在首结点与我们待插入的元素有相同的hash和key值,则先记录。
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) // 如果首结点的类型是红黑树类型,则按照红黑树方法添加该元素
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { // 到这一步,说明首结点类型为链表类型。
for (int binCount = 0; ; ++binCount) {
// 如果遍历到末尾时,先在尾部追加该元素结点。
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 当遍历的结点数目大于8时,则采取树化结构。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 如果找到与我们待插入的元素具有相同的hash和key值的结点,则停止遍历。此时e已经记录了该结点
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 表明,记录到具有相同元素的结点
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); // 这个是空函数,可以由用户根据需要覆盖
return oldValue;
}
}
++modCount;
// 当结点数+1大于threshold时,则进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict); // 这个是空函数,可以由用户根据需要覆盖
return null;
}
参考:
1、JDK1.8HashMap原理和源码分析(java面试收藏)
2、Java类集框架之HashMap(JDK1.8)源码剖析
JDK1.8 HashMap中put源码分析的更多相关文章
- 关于JDK1.8 HashMap扩容部分源码分析
今天回顾hashmap源码的时候发现一个很有意思的地方,那就是jdk1.8在hashmap扩容上面的优化. 首先大家可能都知道,1.8比1.7多出了一个红黑树化的操作,当然在扩容的时候也要对红黑树进行 ...
- 并发-HashMap和HashTable源码分析
HashMap和HashTable源码分析 参考: https://blog.csdn.net/luanlouis/article/details/41576373 http://www.cnblog ...
- HashMap原理及源码分析
HashMap 原理及源码分析 1. 存储结构 HashMap 内部是由 Node 类型的数组实现的.Node 包含着键值对,内部有四个字段,从 next 字段我们可以看出,Node 是一个链表.即数 ...
- 【原】Spark中Client源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Client源码分析(一)http://www.cnblogs.com/yourarebest/p/5313006.html DriverClient中的 ...
- 【原】Spark中Master源码分析(二)
继续上一篇的内容.上一篇的内容为: Spark中Master源码分析(一) http://www.cnblogs.com/yourarebest/p/5312965.html 4.receive方法, ...
- 【原】 Spark中Worker源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Worker源码分析(一)http://www.cnblogs.com/yourarebest/p/5300202.html 4.receive方法, r ...
- php中foreach源码分析(编译原理)
php中foreach源码分析(编译原理) 一.总结 编译原理(lex and yacc)的知识 二.php中foreach源码分析 foreach是PHP中很常用的一个用作数组循环的控制语句.因为它 ...
- 手把手教你实现栈以及C#中Stack源码分析
定义 栈又名堆栈,是一种操作受限的线性表,仅能在表尾进行插入和删除操作. 它的特点是先进后出,就好比我们往桶里面放盘子,放的时候都是从下往上一个一个放(入栈),取的时候只能从上往下一个一个取(出栈), ...
- 基于JDK1.8,Java容器源码分析
容器源码分析 如果没有特别说明,以下源码分析基于 JDK 1.8. 在 IDEA 中 double shift 调出 Search EveryWhere,查找源码文件,找到之后就可以阅读源码. Lis ...
随机推荐
- HTML中标签和元素的区别
作为一个前端,相信大家最先接触应该都是HTML吧?在HTML中很多人可能都没有把什么叫标签,什么叫元素这个概念搞清楚,为了把这个大家不曾留意的易混淆的搞清楚,特作此一文彻底解决掉这个问题! 首先我们来 ...
- SQLite使用教程11 表达式
SQLite 表达式 表达式是一个或多个值.运算符和计算值的SQL函数的组合. SQL 表达式与公式类似,都写在查询语言中.您还可以使用特定的数据集来查询数据库. 语法 假设 SELECT 语句的基本 ...
- paxos 实现
原文地址:http://rdc.taobao.com/blog/cs/?p=162 本文主要介绍zookeeper中zookeeper Server leader的选举,zookeeper在选举lea ...
- 【转】与BT下载相关的概念
1. DHT DHT全称叫分布式哈希表(Distributed Hash Table),是一种分布式存储方法.在不需要服务器的情况下,每个客户端负责一个小范围的路由,并负责存储一小部分数据,从而实现整 ...
- unity3d 中加入�视频
加入�音频 视频 using UnityEngine; using System.Collections; public class play_video : MonoBehaviour { publ ...
- iOS开发——UI篇OC篇&不规则排列的图片布局
不规则排列的图片布局 一直在500px上看照片,发照片.以前看它的首页图片展示就只是觉得好看,洋气,也没想过自己在iOS上实现一下.昨天不知怎么的就开始想其中的算法了,现在我把思考的过程在这里贴出来分 ...
- eclipse创建多模块maven工程小结
创建maven工程步骤 1 新建一个maven工程,如下图所示: 2 选择项目名称(或项目目录),如下图所示: 3 填写maven工程相关信息,注意父maven工程的packing方式是pom,如下图 ...
- ASP.NET 不同页面之间传值
不同页面之间如何传值?我们假设A和B两个页面,A是传递,B是接收. 下面学习4种方式: 通过URL链接地址传递 POST方式传递 Session方式传递 Application方式传递 1. 通过UR ...
- Adroid_Spinner_ArrayAdapter
XML布局文件 <RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android" xmln ...
- Java中处理Linux信号量
为了防止无良网站的爬虫抓取文章,特此标识,转载请注明文章出处.LaplaceDemon/ShiJiaqi. http://www.cnblogs.com/shijiaqi1066/p/5976361. ...