SQL中INEXISTS和IN 的区别和联系
SET NOCOUNT ON , SET NOCOUNT OFF
当 SET NOCOUNT 为 ON 时,不返回计数(表示受 Transact-SQL 语句影响的行数)。
当 SET NOCOUNT 为 OFF 时,返回计数。
如果存储过程中包含的一些语句并不返回许多实际的数据, 则该设置由于大量减
少了网络流量,因此可显著提高性能。
SQL 中 IN 和 EXISTS 用法的区别:
NOT IN
SELECT DISTINCT MD001 FROM BOMMD WHERE MD001 NOT IN (SELECT MC001
FROM BOMMC)
NOT EXISTS,exists 的用法跟 in 不一样,一般都需要和子表进行关联,而且关联时,需要
用索引,这样就可以加快速度
select DISTINCT MD001 from BOMMD WHERE NOT EXISTS (SELECT MC001 FROM
BOMMC where BOMMC.MC001 = BOMMD.MD001 )
exists 是用来判断是否存在的, 当 exists( 查询 )中的查询存在结果时则返回真, 否则返回假。
not exists 则相反。
exists 做为 where 条件时,是先对 where 前的主查询询进行查询,然后用主查询的结果
一个一个的代入 exists 的查询进行判断,如果为真则输出当前这一条主查询的结果,否则
不输出。
in 和 exists
in 是把外表和内表作 hash 连接, 而 exists 是对外表作 loop 循环, 每次 loop 循环再对内表
进行查询。一直以来认为 exists 比 in 效率高的说法是不准确的。
如果查询的两个表大小相当,那么用 in 和 exists 差别不大。
如果两个表中一个较小, 一个是大表, 则子查询表大的用 exists , 子查询表小的用 in :
例如:表 A(小表),表 B(大表) 1:
select * from A where cc in (select cc from B)
效率低,用到了 A 表上 cc 列的索引;
select * from A where exists (select cc from B where cc=A.cc)
效率高,用到了 B 表上 cc 列的索引。
相反的 2 :
select * from B where cc in (select cc from A)
效率高,用到了 B 表上 cc 列的索引;
select * from B where exists (select cc from A where cc=B.cc)
效率低,用到了 A 表上 cc 列的索引。
not in 和 not exists 如果查询语句使用了 not in 那么内外表都进行全表扫描, 没有用到索引;
而 not extsts 的子查询依然能用到表上的索引。 所以无论那个表大, 用 not exists 都比 not in
要快。
SQL中 in 与 =的区别:
select name from student where name in ('zhang' ,'wang' ,'li' ,'zhao' );
与
select name from student where name ='zhang' or name ='li' or name ='wang' or name ='zhao'
的结果是相同的。
例子如下(即 exists 返回 where 后 2 个比较的 where 子句中 相同值, not exists 则返回 where 子句中 不同值):
exists (sql 返回结果集为真 )
not exists (sql 不返回结果集为真 )
如下:
表 A
ID NAME
1 A1
2 A2
3 A3
表 B
ID AID NAME
1 1 B1
2 2 B2
3 2 B3
表 A 和表 B 是一对多的关系 A.ID --> B.AID
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE A.ID =B.AID)
执行结果为
1 A1
2 A2
原因可以按照如下分析
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID = 1)
-->SELECT * FROM B WHERE B.AID = 1 有值返回真所以有数据
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID = 2)
-->SELECT * FROM B WHERE B.AID = 2 有值返回真所以有数据
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID = 3)
-->SELECT * FROM B WHERE B.AID = 3 无值返回真所以没有数据
NOT EXISTS 就是反过来
SELECT ID , NAME FROM A WHERE NOT EXIST ( SELECT * FROM B WHERE A.ID =B.AID)
执行结果为
3 A3
SQL 中 in与 exists区别:
IN
确定给定的值是否与子查询或列表中的值相匹配。
EXISTS
指定一个子查询,检测行的存在。
比较使用 EXISTS 和 IN 的查询
这个例子比较了两个语义类似的查询。 第一个查询使用 EXISTS 而第二个查询使用 IN 。 注
意两个查询返回相同的信息。
USE pubs
SELECT DISTINCT pub_name
FROM publishers
WHERE EXISTS
(SELECT *
FROM titles
WHERE pub_id = publishers.pub_id
AND type = 'business')
using the IN clause:
USE pubs;
SELECT distinct pub_name
FROM publishers
WHERE pub_id IN
(SELECT pub_id
FROM titles
WHERE type = 'business')
GO
下面是任一查询的结果集:
pub_name
----------------------------------------
Algodata Infosystems
New Moon Books
(2 row(s) affected)
exits 相当于存在量词:表示集合存在 ,也就是集合不为空只作用一个集合 .
例如:
exist P 表示 P 不空时为真 ; not exist P 表示 p 为空时 为真
in 表示一个标量和一元关系的关系。
例如:
s in P 表示当 s 与 P 中的某个值相等时 为真 ; s not in P 表示 s 与 P 中的每一个值都不相等时为真
in 和 exists性能比较:
in 是把外表和内表作 hash 连接,而 exists 是对外表作 loop 循环,每次 loop 循环再对内表进行查询。
一直以来认为 exists 比 in 效率高的说法是不准确的。如果查询的两个表大小相当,那么用 in 和 exists 差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用 exists,子查询表小的用 in。
例如:表 A(小表),表 B(大表)
1:
select * from A where cc in (select cc from B)
效率低,用到了 A 表上 cc 列的索引;
select * from A where exists(select cc from B where cc=A.cc)
效率高,用到了 B 表上 cc 列的索引。
相反的
2:
select * from B where cc in (select cc from A)
效率高,用到了 B 表上 cc 列的索引;
select * from B where exists(select cc from A where cc=B.cc)
效率低,用到了 A 表上 cc 列的索引。
not in 和 not exists性能比较:
如果查询语句使用了 not in 那么内外表都进行全表扫描,没有用到索引;
而 not extsts 的子查询依然能用到表上的索引。
所以无论那个表大,用 not exists 都比 not in 要快。
in 与 =的区别:
select name from student where name in ('zhang','wang','li','zhao');
与
select name from student where name='zhang' or name='li' or name='wang' or name='zhao'
的结果是相同的。
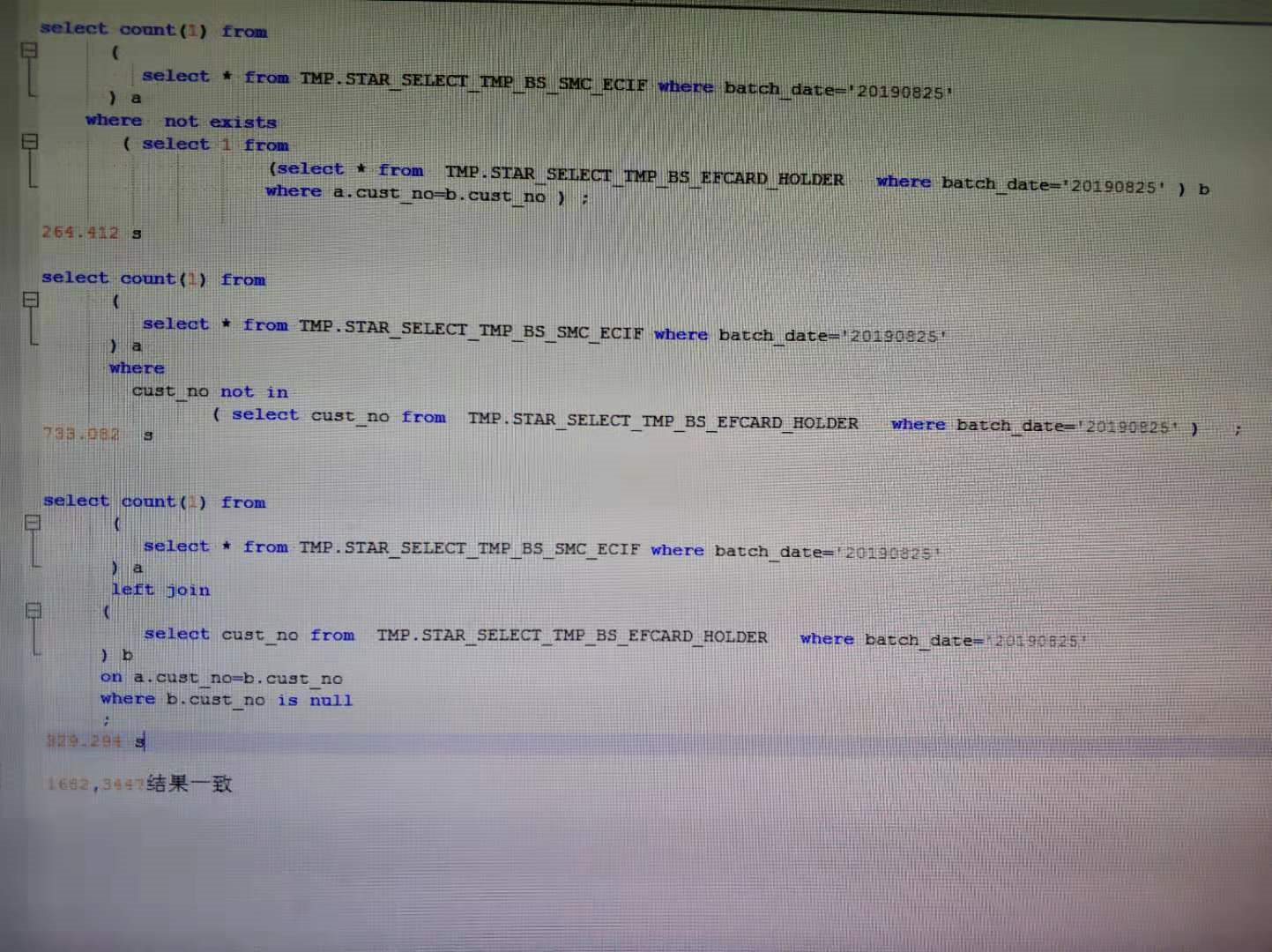
生产环境真实比较:
150节点,数据量 :5000w-3000w:
性能:exists>join null>in
SQL中INEXISTS和IN 的区别和联系的更多相关文章
- SQL中ON和WHERE的区别
SQL中ON和WHERE的区别 - 邃蓝星空 - 博客园 https://www.cnblogs.com/guanshan/articles/guan062.html
- SQL中存储过程和函数的区别
转:https://www.cnblogs.com/jacketlin/p/7874009.html 本质上没区别.只是函数有如:只能返回一个变量的限制.而存储过程可以返回多个. 而函数是可以嵌入在s ...
- 面试问题 - SQL 中存储过程与函数的区别
SQL 中的存储过程与函数没有本质上的区别 函数 -> 只能返回一个变量. 函数可以嵌入到sql中使用, 可以在select 中调用, 而存储过程不行. 但函数也有着更多的限制,比如不能使用临 ...
- SQL中Where与Having的区别
“Where” 是一个约束声明,使用Where来约束来之数据库的数据,Where是在结果返回之前起作用的,且Where中不能使用聚合函数. “Having”是一个过滤声明,是在查询返回结果集以后对查询 ...
- SQL中 WHERE与HAVING的区别
SQL语句中的Having子句与where子句之区别 在说区别之前,得先介绍GROUP BY这个子句,而在说GROUP子句前,又得先说说“聚合函数”——SQL语言中一种特殊的函数.例如SUM, COU ...
- SQL中ON和WHERE的区别(转)
原文:https://www.cnblogs.com/guanshan/articles/guan062.html 数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时 ...
- SQl中drop与truncate的区别
在对SQL的表操作时,我们因不同的需求做出相应的操作. 我来对比一下truncate table '表明'与drop table '表格名'的区别,跟大家一起学习. drop table '表格名'- ...
- SQL 中having 和where的区别分析
在select语句中可以使用groupby子句将行划分成较小的组,然后,使用聚组函数返回每一个组的汇总信息,另外,可以使用having子句限制返回的结果集 在select语句中可以使用groupby子 ...
- sql中Statement与PreparedStatement的区别
1.Statement用于执行静态sql语句,在执行时,必须指定一个事先准备好的sql语句,也就是说sql语句是静态的. 2.PrepareStatement是预编译的sql语句对象,sql语句被预编 ...
随机推荐
- 【ZT】Enhancement Framework – Introduction
Enhancement Framework – Introduction By Naimesh Patel | March 26, 2014 | Enhancement Implementation ...
- 物料批量盘点,调用其中两个BAPI BAPI_MATPHYSINV_COUNT BAPI_MATPHYSINV_CHANGECOUNT
涉及两个BAPI:录入数量BAPI_MATPHYSINV_COUNT 修改数量:BAPI_MATPHYSINV_CHANGECOUNT REPORT ZSC_133 NO STANDARD PAGE ...
- Vue+Python 电商实战
安装webStorm https://blog.csdn.net/qq_38845858/article/details/89850737 安装NodeJs http://nodejs.cn/do ...
- Web04_JavaScript
String对象 match()找到一个或多个正则表达式的匹配 substr()从起始索引号提取字符串中指定数目的字符 substring()提取字符串中两个指定的索引号之间的字符 <!DOCT ...
- Python基础知识思维导图|自学Python指南
微信公众号[软件测试大本营]回复"python",获取50本python精华电子书. 测试/开发知识干货,互联网职场,程序员成长崛起,终身学习. 现在最火的编程语言是什么?答案就是 ...
- Mybatis 之 SQL生成技巧
一.增 1.<trim> 和<if>实现数据插入 <insert id="addInOrder" parameterType="XXX.mo ...
- 从MAP角度理解神经网络训练过程中的正则化
在前面的文章中,已经介绍了从有约束条件下的凸优化角度思考神经网络训练过程中的L2正则化,本次我们从最大后验概率点估计(MAP,maximum a posteriori point estimate)的 ...
- 【神经网络与深度学习】学习笔记:AlexNet&Imagenet学习笔记
学习笔记:AlexNet&Imagenet学习笔记 ImageNet(http://www.image-net.org)是李菲菲组的图像库,和WordNet 可以结合使用 (毕业于Caltec ...
- 【神经网络与深度学习】用训练好的caffemodel来进行分类
现在我正在利用imagenet进行finetune训练,待训练好模型,下一步就是利用模型进行分类.故转载一些较有效的相关博客. 博客来源:http://www.cnblogs.com/denny402 ...
- 禁止layer.msg()回调函数时抖动
layer.msg(resp.msg, { shift: -1, time: 2000 }, function () { window.l ...