SQL中INEXISTS和IN 的区别和联系
SET NOCOUNT ON , SET NOCOUNT OFF
当 SET NOCOUNT 为 ON 时,不返回计数(表示受 Transact-SQL 语句影响的行数)。
当 SET NOCOUNT 为 OFF 时,返回计数。
如果存储过程中包含的一些语句并不返回许多实际的数据, 则该设置由于大量减
少了网络流量,因此可显著提高性能。
SQL 中 IN 和 EXISTS 用法的区别:
NOT IN
SELECT DISTINCT MD001 FROM BOMMD WHERE MD001 NOT IN (SELECT MC001
FROM BOMMC)
NOT EXISTS,exists 的用法跟 in 不一样,一般都需要和子表进行关联,而且关联时,需要
用索引,这样就可以加快速度
select DISTINCT MD001 from BOMMD WHERE NOT EXISTS (SELECT MC001 FROM
BOMMC where BOMMC.MC001 = BOMMD.MD001 )
exists 是用来判断是否存在的, 当 exists( 查询 )中的查询存在结果时则返回真, 否则返回假。
not exists 则相反。
exists 做为 where 条件时,是先对 where 前的主查询询进行查询,然后用主查询的结果
一个一个的代入 exists 的查询进行判断,如果为真则输出当前这一条主查询的结果,否则
不输出。
in 和 exists
in 是把外表和内表作 hash 连接, 而 exists 是对外表作 loop 循环, 每次 loop 循环再对内表
进行查询。一直以来认为 exists 比 in 效率高的说法是不准确的。
如果查询的两个表大小相当,那么用 in 和 exists 差别不大。
如果两个表中一个较小, 一个是大表, 则子查询表大的用 exists , 子查询表小的用 in :
例如:表 A(小表),表 B(大表) 1:
select * from A where cc in (select cc from B)
效率低,用到了 A 表上 cc 列的索引;
select * from A where exists (select cc from B where cc=A.cc)
效率高,用到了 B 表上 cc 列的索引。
相反的 2 :
select * from B where cc in (select cc from A)
效率高,用到了 B 表上 cc 列的索引;
select * from B where exists (select cc from A where cc=B.cc)
效率低,用到了 A 表上 cc 列的索引。
not in 和 not exists 如果查询语句使用了 not in 那么内外表都进行全表扫描, 没有用到索引;
而 not extsts 的子查询依然能用到表上的索引。 所以无论那个表大, 用 not exists 都比 not in
要快。
SQL中 in 与 =的区别:
select name from student where name in ('zhang' ,'wang' ,'li' ,'zhao' );
与
select name from student where name ='zhang' or name ='li' or name ='wang' or name ='zhao'
的结果是相同的。
例子如下(即 exists 返回 where 后 2 个比较的 where 子句中 相同值, not exists 则返回 where 子句中 不同值):
exists (sql 返回结果集为真 )
not exists (sql 不返回结果集为真 )
如下:
表 A
ID NAME
1 A1
2 A2
3 A3
表 B
ID AID NAME
1 1 B1
2 2 B2
3 2 B3
表 A 和表 B 是一对多的关系 A.ID --> B.AID
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE A.ID =B.AID)
执行结果为
1 A1
2 A2
原因可以按照如下分析
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID = 1)
-->SELECT * FROM B WHERE B.AID = 1 有值返回真所以有数据
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID = 2)
-->SELECT * FROM B WHERE B.AID = 2 有值返回真所以有数据
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID = 3)
-->SELECT * FROM B WHERE B.AID = 3 无值返回真所以没有数据
NOT EXISTS 就是反过来
SELECT ID , NAME FROM A WHERE NOT EXIST ( SELECT * FROM B WHERE A.ID =B.AID)
执行结果为
3 A3
SQL 中 in与 exists区别:
IN
确定给定的值是否与子查询或列表中的值相匹配。
EXISTS
指定一个子查询,检测行的存在。
比较使用 EXISTS 和 IN 的查询
这个例子比较了两个语义类似的查询。 第一个查询使用 EXISTS 而第二个查询使用 IN 。 注
意两个查询返回相同的信息。
USE pubs
SELECT DISTINCT pub_name
FROM publishers
WHERE EXISTS
(SELECT *
FROM titles
WHERE pub_id = publishers.pub_id
AND type = 'business')
using the IN clause:
USE pubs;
SELECT distinct pub_name
FROM publishers
WHERE pub_id IN
(SELECT pub_id
FROM titles
WHERE type = 'business')
GO
下面是任一查询的结果集:
pub_name
----------------------------------------
Algodata Infosystems
New Moon Books
(2 row(s) affected)
exits 相当于存在量词:表示集合存在 ,也就是集合不为空只作用一个集合 .
例如:
exist P 表示 P 不空时为真 ; not exist P 表示 p 为空时 为真
in 表示一个标量和一元关系的关系。
例如:
s in P 表示当 s 与 P 中的某个值相等时 为真 ; s not in P 表示 s 与 P 中的每一个值都不相等时为真
in 和 exists性能比较:
in 是把外表和内表作 hash 连接,而 exists 是对外表作 loop 循环,每次 loop 循环再对内表进行查询。
一直以来认为 exists 比 in 效率高的说法是不准确的。如果查询的两个表大小相当,那么用 in 和 exists 差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用 exists,子查询表小的用 in。
例如:表 A(小表),表 B(大表)
1:
select * from A where cc in (select cc from B)
效率低,用到了 A 表上 cc 列的索引;
select * from A where exists(select cc from B where cc=A.cc)
效率高,用到了 B 表上 cc 列的索引。
相反的
2:
select * from B where cc in (select cc from A)
效率高,用到了 B 表上 cc 列的索引;
select * from B where exists(select cc from A where cc=B.cc)
效率低,用到了 A 表上 cc 列的索引。
not in 和 not exists性能比较:
如果查询语句使用了 not in 那么内外表都进行全表扫描,没有用到索引;
而 not extsts 的子查询依然能用到表上的索引。
所以无论那个表大,用 not exists 都比 not in 要快。
in 与 =的区别:
select name from student where name in ('zhang','wang','li','zhao');
与
select name from student where name='zhang' or name='li' or name='wang' or name='zhao'
的结果是相同的。
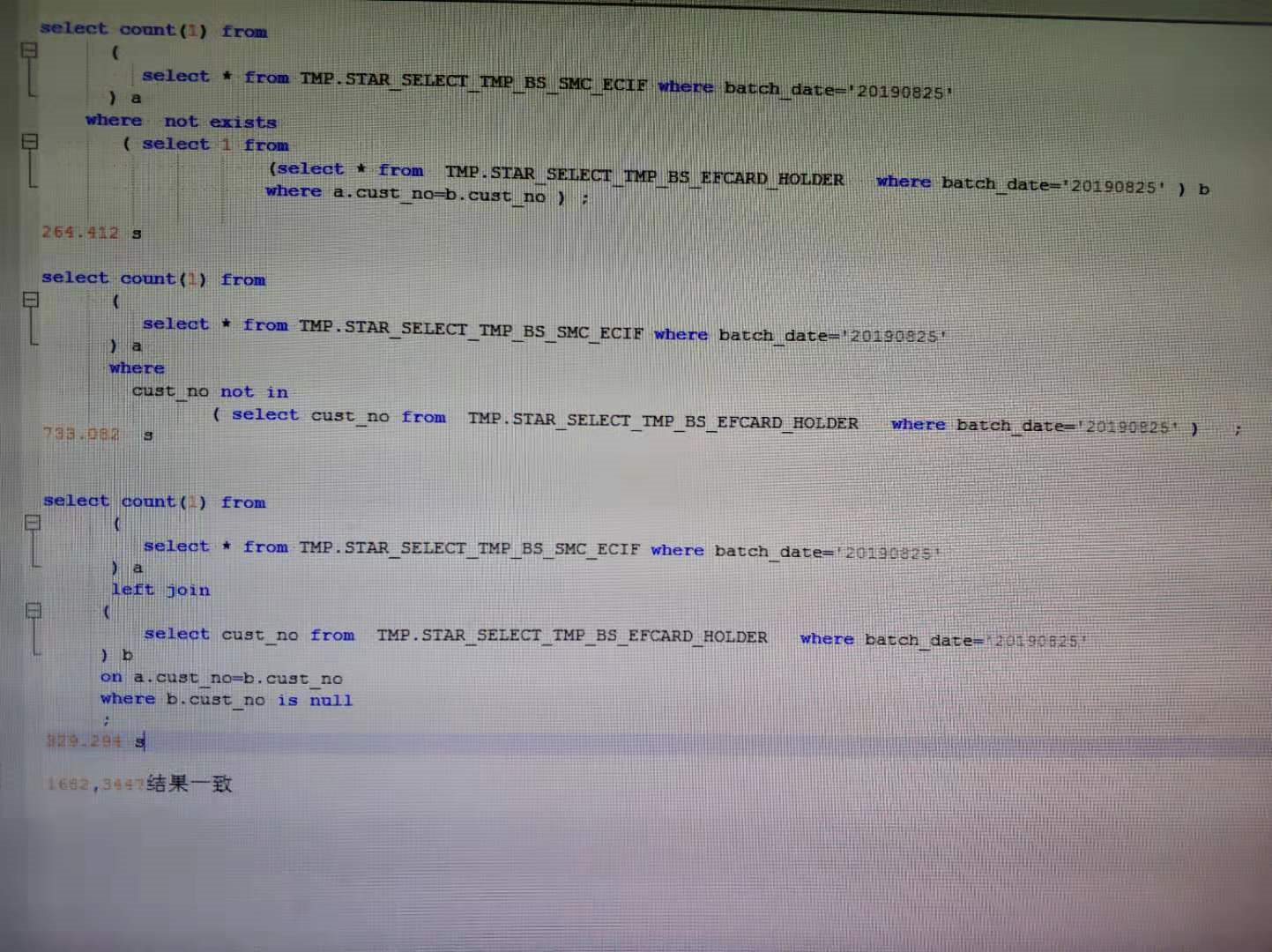
生产环境真实比较:
150节点,数据量 :5000w-3000w:
性能:exists>join null>in
SQL中INEXISTS和IN 的区别和联系的更多相关文章
- SQL中ON和WHERE的区别
SQL中ON和WHERE的区别 - 邃蓝星空 - 博客园 https://www.cnblogs.com/guanshan/articles/guan062.html
- SQL中存储过程和函数的区别
转:https://www.cnblogs.com/jacketlin/p/7874009.html 本质上没区别.只是函数有如:只能返回一个变量的限制.而存储过程可以返回多个. 而函数是可以嵌入在s ...
- 面试问题 - SQL 中存储过程与函数的区别
SQL 中的存储过程与函数没有本质上的区别 函数 -> 只能返回一个变量. 函数可以嵌入到sql中使用, 可以在select 中调用, 而存储过程不行. 但函数也有着更多的限制,比如不能使用临 ...
- SQL中Where与Having的区别
“Where” 是一个约束声明,使用Where来约束来之数据库的数据,Where是在结果返回之前起作用的,且Where中不能使用聚合函数. “Having”是一个过滤声明,是在查询返回结果集以后对查询 ...
- SQL中 WHERE与HAVING的区别
SQL语句中的Having子句与where子句之区别 在说区别之前,得先介绍GROUP BY这个子句,而在说GROUP子句前,又得先说说“聚合函数”——SQL语言中一种特殊的函数.例如SUM, COU ...
- SQL中ON和WHERE的区别(转)
原文:https://www.cnblogs.com/guanshan/articles/guan062.html 数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时 ...
- SQl中drop与truncate的区别
在对SQL的表操作时,我们因不同的需求做出相应的操作. 我来对比一下truncate table '表明'与drop table '表格名'的区别,跟大家一起学习. drop table '表格名'- ...
- SQL 中having 和where的区别分析
在select语句中可以使用groupby子句将行划分成较小的组,然后,使用聚组函数返回每一个组的汇总信息,另外,可以使用having子句限制返回的结果集 在select语句中可以使用groupby子 ...
- sql中Statement与PreparedStatement的区别
1.Statement用于执行静态sql语句,在执行时,必须指定一个事先准备好的sql语句,也就是说sql语句是静态的. 2.PrepareStatement是预编译的sql语句对象,sql语句被预编 ...
随机推荐
- 【DVWA】Brute Force(暴力破解)通关教程
日期:2019-08-01 14:49:47 更新: 作者:Bay0net 介绍:一直以为爆破很简单,直到学习了 Burp 的宏录制和匹配关键词,才发现 burp 能这么玩... 0x01. 漏洞介绍 ...
- 问题:anaconda: command not found
打开Terminal 1.使用命令:sudo apt install vim 安装vim文本编辑器2.使用命令:vim ~/.bashrc 修改环境变量 3.在文本最后添加命令:export PATH ...
- 【LeetCode】122、买卖股票的最佳时机 II
Best Time to Buy and Sell Stock II 题目等级:Easy 题目描述: Say you have an array for which the ith element i ...
- CentOS7 linux系统多种方式安装ClickHouse数据库
clickhouse是由俄罗斯Yandex公司开发的列式存储数据库,于2016年开源,clickhouse的定位是快速的数据分析,对于处理海量数据的情况性能非常好,在网上也有很多测试的案例,在大数据的 ...
- zabbix监控java
参考: 官网: https://www.zabbix.com/documentation/4.0/manual/config/items/itemtypes/jmx_monitoring
- Spring(四)--bean的属性赋值
bean的属性赋值 1.需要的实体类 2.需要的配置文件 <?xml version="1.0" encoding="UTF-8"?> <be ...
- 如何根据对象的属性,对集合(list / set)中的对象进行排序
一:针对list 通过java.util.Collections的sort方法,有2个参数,第一个参数是list对象,第二个参数是new Comparator<对象类>(){}方法,这 ...
- 03: saltstack和ansible的区别和原理
1.1 SaltStack.Ansible.Puppet比较 1.SaltStack 1. saltStack由Python编写,为server-client模式的系统,自己本身支持多master. ...
- day 17 模块
模块是什么? 抖音: 20万行代码全部放在一个py文件中? 为什么不行? 1. 代码太多,读取代码耗时太长. 代码不容易维护. 所以我们怎么样? 一个py文件拆分100文件,100个py文件又有相似相 ...
- Codeforces 1220D. Alex and Julian
传送门 首先考虑怎样的集合一定是合法的 发现全部是奇数的集合一定合法,因为每次都是奇数连偶数,偶数连奇数 然后考虑如果集合同时有奇数和偶数是否一定不合法,结论是一定不合法,证明如下: 设某个奇数为 $ ...