其它——ASCII码,Unicode和UTF-8编码
文章目录
一 ASCII码
计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
ASCII 码一共规定了128个字符的编码,比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
0
1
1
0
0
0
1
0
统一规定为0
0或1
0或1
0或1
0或1
0或1
0或1
0或1
二 非ASCII编码
如果只表示英语,用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。
比如,在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。
于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。
比如,法语中的é的编码为130(二进制10000010)。
这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。
不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。
比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。
但是不管怎样,所有这些编码方式中,0–127表示的符号是一样的,不一样的只是128–255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。
一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。
比如,简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 256 x 256 = 65536 个符号
三 Unicode
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。
因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。
这就是为什么文件经常出现乱码,因为编码和解码用的编码方式不一样
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。
这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。
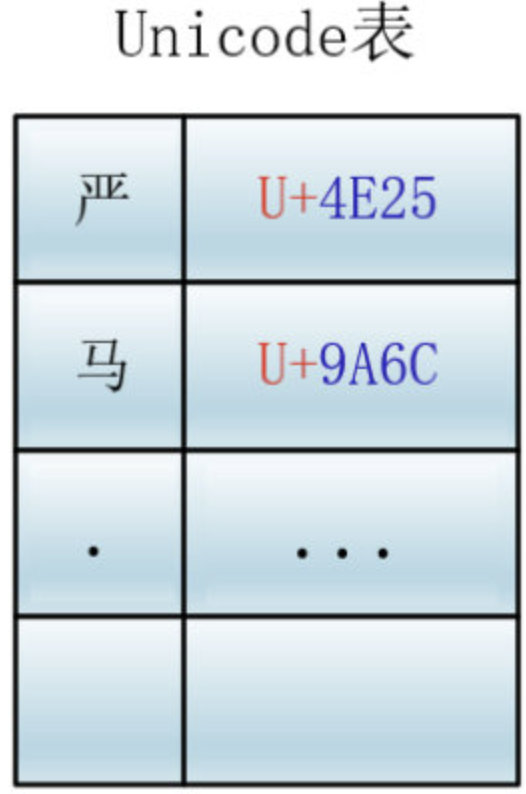
Unicode 为世界上所有字符都分配了一个唯一的数字编号,这个编号范围从 0x000000 到 0x10FFFF (十六进制),有 110 多万,每个字符都有一个唯一的 Unicode 编号,这个编号一般写成 16 进制,在前面加上 U+。例如:
U+9A6C表示汉字马,
U+4E25表示汉字严
U+0639表示阿拉伯字母Ain,
U+0041表示英语的大写字母A,
Unicode 就相当于一张表,建立了字符与编号之间的联系
3.1 Unicode存在的问题
Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题:
问题一: 如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
问题二: 英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍
3.2 它们造成的结果是
结果一: 出现了 Unicode 的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 Unicode,主要有 UTF-8,UTF-16,UTF-32。
结果二: Unicode 在很长一段时间内无法推广,直到互联网的出现
四 UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。
UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。
其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。
注意:UTF-8 是 Unicode 的实现方式之一。
4.1 UTF-8 特点
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
4.2 UTF-8 的编码规则
UTF-8 的编码规则有二条:
**规则一:**对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
**规则二:**对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。下表总结了编码规则,字母x表示可用编码的位。
| 编号范围(编号对应十进制数) | 二进制格式 |
|---|---|
| 十六进制范围:(0x00—0x7f) 十进制范围:(0—127) | 0XXXXXXX |
| 十六进制范围:(0x80—0x7ff) 十进制范围:(128—2047) | 110XXXXX 10XXXXXX |
| 十六进制范围:(0x800—0xffff) 十进制范围:(2048—65535) | 1110XXXX 10XXXXXX 10XXXXXX |
| 十六进制范围:(0x10000—0x10ffff) 十进制范围:(65536以上) | 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX |
五 Unicode和UTF-8之间的转换
跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是以汉字严为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5
后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5
其它——ASCII码,Unicode和UTF-8编码的更多相关文章
- ascii、unicode、utf、gb等编码详解
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物.他们看到8个开关状态是好的,于是他们把这称为"字节".再后来,他们又做了一些可以处理这 ...
- Ascii码 unicode码 utf-8编码 gbk编码的区别
ASCII码: 只包含英文,数字,特殊符号的编码,一个字符用8位(bit)1字节(byte)表示 Unicode码: 又称万国码,包含全世界所有的文字,符号,一个字符用32位(bit)4字节(byte ...
- ASCII,Unicode和UTF-8字符编码
ASCII码 我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串.每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte).也就是 ...
- ASCII、Unicode、UTF-8字符集编码
ASCII码 计算机内部,所有信息都是由二进制的字符串表示 每一个二进制位有“0”.“1”两种状态,因此8个二进制位可以表示256个状态,每个状态代表一个符号就是256个符号,从0000000到111 ...
- ASCII、UNICODE、UTF
在计算机中,一个字节对应8位,每位可以用0或1表示,因此一个字节可以表示256种情况. ascii 美国人用了一个字节中的后7位来表达他们常用的字符,最高位一直是0,这便是ascii码. 因此asci ...
- python中的字符串编码问题——2.理解ASCII码、ANSI码、Unicode编码、UTF-8编码
ASCII码:全名是American Standard Code for Information Interchange,ASCII码中,一个英文字母(不分大小写)占一个字节的空间,范围0x00~0x ...
- ASCII与Unicode编码消息写文件浅析
[文章摘要] ASCII与Unicode是两种常见的字符编码. 它们的表示方法不一样,因而在程序中就要差别处理. 本文基于作者的实际开发经验,对ASCII与Unicode两种字符编码消息的写文件过程进 ...
- 字符编码笔记:ASCII,Unicode 和 UTF-8(理解)
1.ASCII 码 美国制定的字符编码规则,对英语字符与二进制位之间的关系做了统一规定. 占一个字节,8 位,最多可表示 2^8 = 256 种状态(字符) 实际共有 128 个字符,只占用一个字节的 ...
- 【python路飞】编码 ascii码(256位 =1个字节)美国;unicode(万国码)中文 一共9万个 用4个字节表示这9万个子 17位就能表示
8位一个字节 1024字节 1KB 1024KB 1MB ASCII码不能包含中文.创建了unicode,一个中文4个字节.UTF-8一个中文3个.GBK中国人用的只包含中文2个字节 升级 Un ...
- Java基础笔记(六)——进制表示、ASCII码和Unicode编码
Java中有三种表示整数的方法:十进制.八进制.十六进制. 八进制:以0开头,包括0~7的数字.如:int octal=020; //定义int型变量存放八进制数据 十六进制:以0x或0X开头,包括 ...
随机推荐
- ProtocolBuffers的国际化和本地化支持
目录 1. 引言 2. 技术原理及概念 3. 实现步骤与流程 4. 应用示例与代码实现讲解 5. 优化与改进 34.< Protocol Buffers 的国际化和本地化支持> 本文将介绍 ...
- [ARM 汇编]高级部分—ARM汇编编程实战—3.3.2 嵌入式开发环境搭建
搭建一个嵌入式开发环境主要包括以下几个部分: 安装交叉编译器 配置集成开发环境(IDE) 安装调试工具 下载和烧录程序 接下来,我们将详细介绍每个部分,并提供相应的实例. 安装交叉编译器 交叉编译器是 ...
- 6个常见的IB网络不通问题
摘要:如果遇到IB网络不通,可以试着从高层往底层逐步分析看看. 本文分享自华为云社区<常见IB网络不通问题记录>,作者: tsjsdbd . 如果遇到IB网络不通,可以试着从高层往底层逐步 ...
- sFlow-RT监控设备教程
1.前言 sflow-rt网站国内无法访问,这里使用蓝奏云下载 2.下载源码 https://lvpeiming.lanzoup.com/imRxy10was0h密码:5rxk 3.开启sFlow-R ...
- 如何通过Java读取到Windows系统日志evtx文件
近日公司有个需求,需要调研如何使用Java来读取Windows日志文件(类型:应用程序,安全,Setup,系统) 一番调研以后,在仅使用java的基础上系统日志文件似乎不太可能(就个人调研结果来看), ...
- 利用身份验证和授权机制,例如OAuth、JWT 和 API 密钥,APIaaS 如何帮助解决安全挑战?
什么是 APIaaS? APIaaS,即 API 即服务(API as a Service)是一种创新的基于云的方法,提供 API(应用程序编程接口),使第三方服务提供商能够访问特定服务.数据或资源. ...
- Centos7中搭建Redis6集群操作步骤
目录 下载安装包 解压安装装包 安装依赖 安装 创建目录 设置配置文件 创建启动服务 制作启动文件 启动并验证Redis 开放防火墙端口 创建集群 集群其他操作 注意 下载安装包 # 进入软件下载目录 ...
- 【阅读笔记】超分之LANR-NLM算法
论文信息 [Single Image Super-Resolution via Locally Regularized Anchored Neighborhood Regression and Non ...
- hexo博客git报错
一.意外的标记异常 1.异常内容: xxx:blog xxxx$ hexo g INFO Start processing FATAL Something's wrong. Maybe you can ...
- SAP ABAP 使用GENIOS求解线性规划问题的简单例子
主要内容来自Operations Research & ABAP ,结合我遇到的需求,做了一些修改. 需求:有BOX1和BOX2两种箱子,分别能包装不同数量的A物料和B物料,给出若干数量的A, ...