RDD练习:词频统计
一、词频统计:
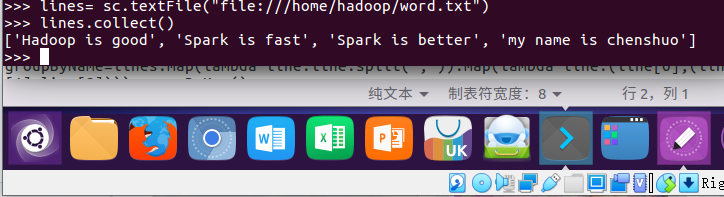
1.读文本文件生成RDD lines
lines=sc.textFile("file:///home/hadoop/word.txt") #读取本地文件
lines.collect()
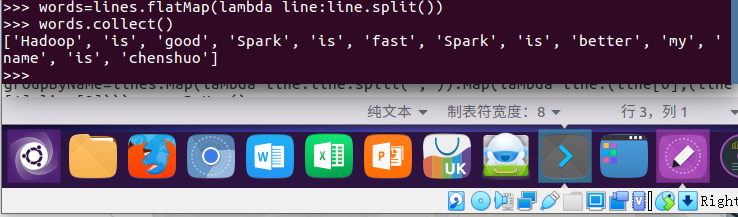
2.将一行一行的文本分割成单词 words flatmap()
words=lines.flatMap(lambda line:line.split()) #划分单词
words.collect()
3.全部转换为小写 lower()
words=words.map(lambda line:line.lower()) #变为小写
words.collect()

4.去掉长度小于3的单词 filter()
words=words.filter(lambda word:len(word)>3)
words.collect()

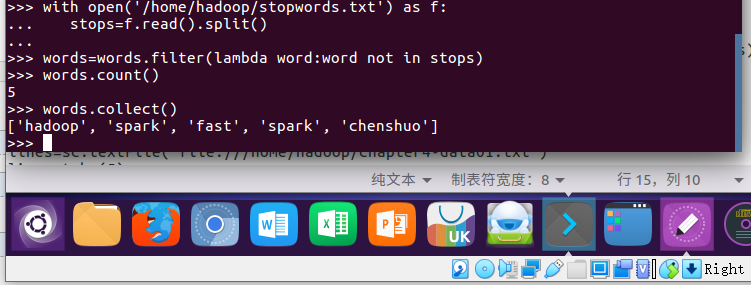
5.去掉停用词
with open('/home/hadoop/stopwords.txt')
stops=f.read().split()
words=words.filter(lambda word:word not in stops)
words.count()
words.collect()
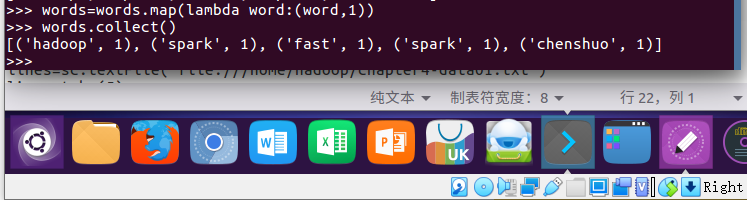
6.转换成键值对 map()
words=words.map(lambda word:(word,1))
words.collect()
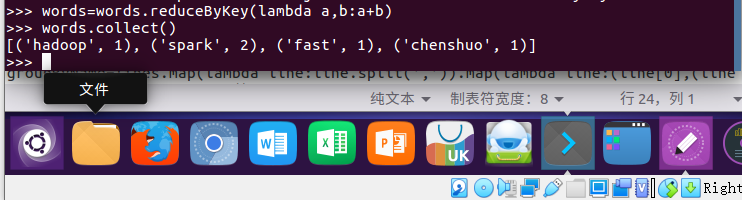
7.统计词频 reduceByKey()
words=words.reduceByKey(lambda a,b:a+b)
words.collect()
二、学生课程分数 groupByKey()
-- 按课程汇总全总学生和分数
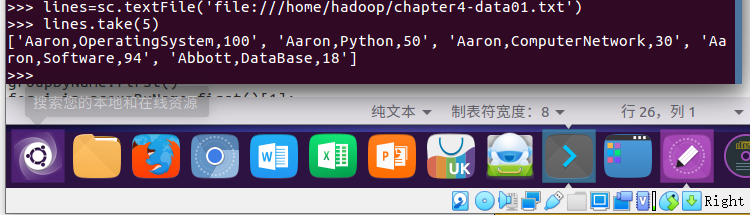
lines = sc.textFile('file:///home/hadoop/chapter4-data01.txt')
lines.take(5)
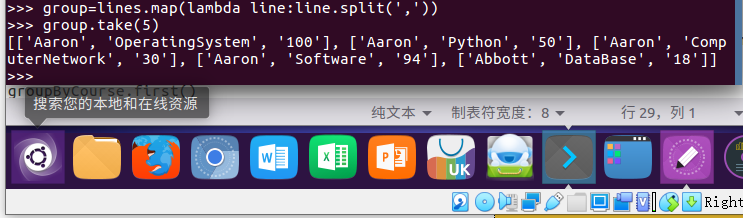
1. 分解出字段 map()
group=lines.map(lambda line:line.split(','))
group.take(5)
2. 生成键值对 map()
group=lines.map(lambda line:line.split(',')).map(lambda line:(line[1],(line[0],line[2])))
group.take(5)

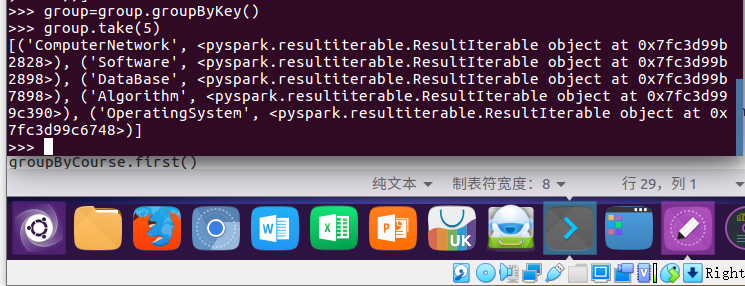
3. 按键分组
group=group.groupByKey()
group.take(5)
4. 输出汇总结果
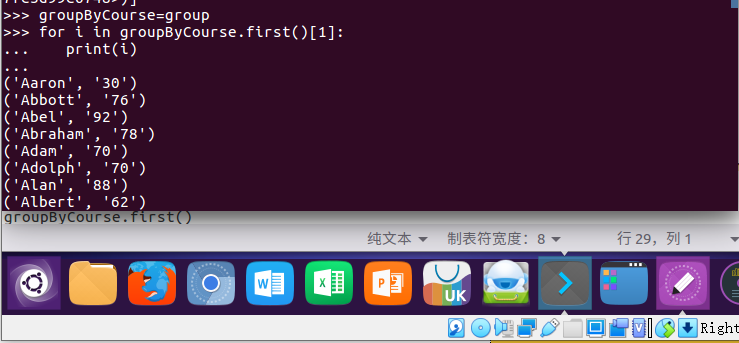
groupByCourse=group
for i in groupByCourse.first()[1]:
print(i)
三、学生课程分数 reduceByKey()
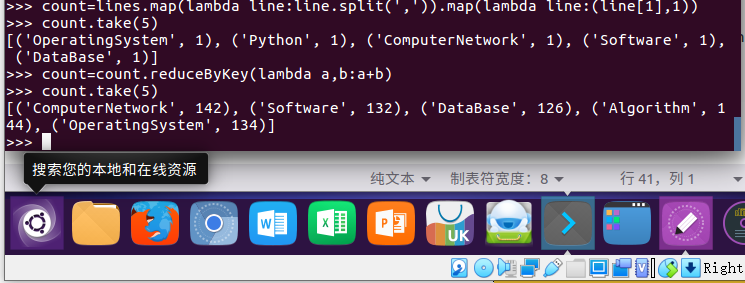
-- 每门课程的选修人数
count=lines.map(lambda line:line.split(',')).map(lambda line:(line[1],1))
count=count.reduceByKey(lambda a,b:a+b)
count.take(5)
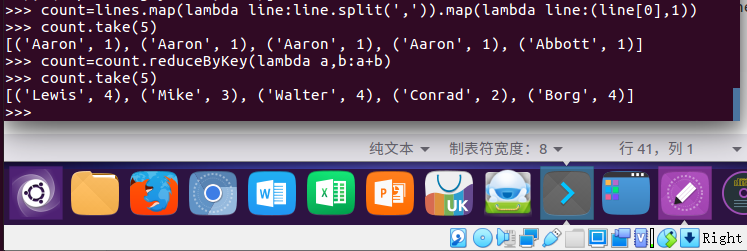
-- 每个学生的选修课程数
count=lines.map(lambda line:line.split(',')).map(lambda line:(line[0],1))
count=count.reduceByKey(lambda a,b:a+b)
count.take(5)
RDD练习:词频统计的更多相关文章
- 05 RDD练习:词频统计,学习课程分数
.词频统计: 1.读文本文件生成RDD lines 2.将一行一行的文本分割成单词 words flatmap() 3.全部转换为小写 lower() 4.去掉长度小于3的单词 filter() 5. ...
- 05 RDD练习:词频统计
一.词频统计: 1.读文本文件生成RDD lines 2.将一行一行的文本分割成单词 words flatmap() 3.全部转换为小写 lower() 4.去掉长度小于3的单词 filter() 5 ...
- 作业3-个人项目<词频统计>
上了一天的课,现在终于可以静下来更新我的博客了. 越来越发现,写博客是一种享受.来看看这次小林老师的“作战任务”. 词频统计 单词: 包含有4个或4个以上的字 ...
- C语言实现词频统计——第二版
原需求 1.读取文件,文件内包可含英文字符,及常见标点,空格级换行符. 2.统计英文单词在本文件的出现次数 3.将统计结果排序 4.显示排序结果 新需求: 1.小文件输入. 为表明程序能跑 2.支持命 ...
- c语言实现词频统计
需求: 1.设计一个词频统计软件,统计给定英文文章的单词频率. 2.文章中包含的标点不计入统计. 3.将统计结果以从大到小的排序方式输出. 设计: 1.因为是跨专业0.0···并不会c++和java, ...
- 软件工程第一次个人项目——词频统计by11061153柴泽华
一.预计工程设计时间 明确要求: 15min: 查阅资料: 1h: 学习C++基础知识与特性: 4-5h: 主函数编写及输入输出部分: 0.5h: 文件的遍历: 1h: 编写两种模式的词频统计函数: ...
- python瓦登尔湖词频统计
#瓦登尔湖词频统计: import string path = 'D:/python3/Walden.txt' with open(path,'r',encoding= 'utf-8') as tex ...
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
- pyspark进行词频统计并返回topN
Part I:词频统计并返回topN 统计的文本数据: what do you do how do you do how do you do how are you from operator imp ...
- 使用storm分别进行计数和词频统计
计数 直接上代码 public class LocalStormSumTopology { public static void main(String[] agrs) { //Topology是通过 ...
随机推荐
- Django之admin后台管理
目录 创建超级用户 向页面中添加表 admin管理页面表名中文显示 创建超级用户 python manage.py createsuperuser 向页面中添加表 登录后,页面中是什么都没有的,还需要 ...
- 镜像搬运工 skopeo
镜像搬运工 skopeo 介绍 skopeo 是一个命令行工具,可对容器镜像和容器存储进行操作. 在没有dockerd的环境下,使用 skopeo 操作镜像是非常方便的. 安装 # 安装 skopeo ...
- 二进制安装Kubernetes(k8s) v1.21.13 IPv4/IPv6双栈
二进制安装Kubernetes(k8s) v1.21.13 IPv4/IPv6双栈 Kubernetes 开源不易,帮忙点个star,谢谢了 介绍 kubernetes二进制安装 后续尽可能第一时间更 ...
- [Linux]CentOS7 安装指定版本软件包
以安装openssl-libs为例. 查看当前服务器中YUM源可安装的软件包版本 [root@iz2vc84t88x94kno0u49zwz ~]# yum list | grep openssl-l ...
- Golang 常用库之jwt-go
本文地址 https://www.cnblogs.com/zichliang/p/17303759.html github地址:https://github.com/dgrijalva/jwt-go ...
- Clion+dap仿真器,移植stm32项目
如何将Keil项目移植到Clion,先看几位大佬的文章: 稚晖君的回答:配置CLion用于STM32开发[优雅の嵌入式开发] 野火论坛:DAP仿真器的使用教程 wuxx:nanoDAP使用疑难杂症解析 ...
- [python] Python枚举模块enum总结
枚举是一种数据类型,在编程中用于表示一组相关的常量.枚举中的每个常量都有一个名称和一个对应的值,可以用于增强代码的可读性和可维护性.在Python中,枚举是由enum模块提供的,而不是Python提供 ...
- jdbc-plus是一款基于JdbcTemplate增强工具包, 基于JdbcTemplate已实现分页、多租户等插件,可自定义扩展插件
jdbc-plus简介 jdbc-plus是一款基于JdbcTemplate增强工具包, 基于JdbcTemplate已实现分页.多租户等插件,可自定义扩展插件.项目地址: https://githu ...
- Centos7.x 安装Chrome + Chrome driver
一.安装Chrome 1.执行下面命令进行安装操作 yum install https://dl.google.com/linux/direct/google-chrome-stable_curren ...
- 高精度------C++
高精度运算------C++ (加减乘除) 例:ZOJ2001 http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemId=1001 The ...