为 VitePress 网站添加 RSS 订阅支持
省流:使用 vitepress-plugin-rss 这个插件
前言
在看许多个人博客站点的时候,右上角总会有个RSS订阅的标志

恰好我的博客也是基于 VitePress 搭建的,就想看看能不能也实现这个功能呢?
动手前先搜了一下,先是看到了vitepress-blog-zaun上有这个RSS的实现支持,再搜了一下发现Vue的官方博客 vuejs/blog 也是用的这样的实现
大概就是自定义 VitePress 的 buildEnd 钩子,在里面实现逻辑获取 md 文件列表,然后通过 feed 生成 RSS 文件,整个逻辑就 50+ 行代码
由于我的博客还分离了独立的主题包 @sugarat/theme,我想把这个功能加到我的主题包里,这样使用这个主题的就可以简单的配置一下就能使用了,当然也为了方便广大 VitePress 用户更加简便的使用,我将这段逻辑单独分离封装到了 vitepress-plugin-rss 这个插件里。
接下来我将会先介绍一下如何食用这个插件,再介绍它的核心实现原理
插件使用
通过 pnpm/npm/yarn 安装插件
pnpm add vitepress-plugin-rss
在 .vitepress/config.ts 配置文件中添加配置使用
下面是最基础的使用配置
import { RssPlugin, RSSOptions } from 'vitepress-plugin-rss'
const baseUrl = 'https://sugarat.top'
const RSS: RSSOptions = {
title: '粥里有勺糖',
baseUrl,
copyright: 'Copyright (c) 2018-present, 粥里有勺糖',
}
export default defineConfig({
vite: {
// ↓↓↓↓↓
plugins: [RssPlugin(RSS)]
// ↑↑↑↑↑
}
})
然后运行 build 命令,你可以看到在rendering pages...后打印了生成 feed.rss 日志...
pnpm run build

同时会在导航栏的 socialLinks 中添加 rss 图标链接

使用是不是非常简单,只需要 10 行代码。
如果你对插件的实现原理感兴趣,请接着往下看 。
核心实现原理解析
VitePress 的拓展在官方文档 Use Cases 部分有提到

其是基于 Vite 的,因此可以使用 Vite 的插件机制来实现主题内容的拓展。
buildEnd 修改
从官方的demo种可以看到,RSS 的生成逻辑是放在 buildEnd 中的,因此咱们插件也需要实现间接修改 buildEnd 方法
这个非常的简单,利用 Vite 的插件提供的 configResolved 钩子就行
下面是简单的demo
import { SiteConfig } from 'vitepress'
let resolveConfig: any = null
function configResolved(config: any) {
// 避免多次执行
if (resolveConfig) {
return
}
resolveConfig = config
const VPConfig: SiteConfig = config.vitepress
if (!VPConfig) {
return
}
const selfBuildEnd = VPConfig.buildEnd
// 自定义 buildEnd 方法,添加 rss 生成支持
VPConfig.buildEnd = async (siteConfig: any) => {
// 调用自己的
await selfBuildEnd?.(siteConfig)
console.log('buildEnd', '生成 rss 文件');
}
}
通过config.vitepress即可拿到vitepress的配置,然后重新定义 buildEnd 方法即可
这里可以直接快速的验证一下
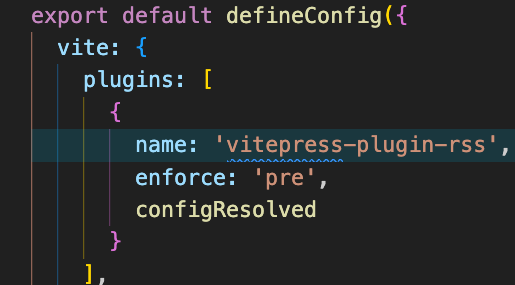
运行后可以看到打印了 buildEnd 生成 rss 文件,说明我们的插件的修改已经生效了
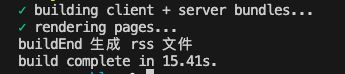
icon 添加
这个也非常的简单,VitePress 在官方文档里有介绍 socialLinks
我们只需要在配置修改中添加一个 socialLinks 的配置即可
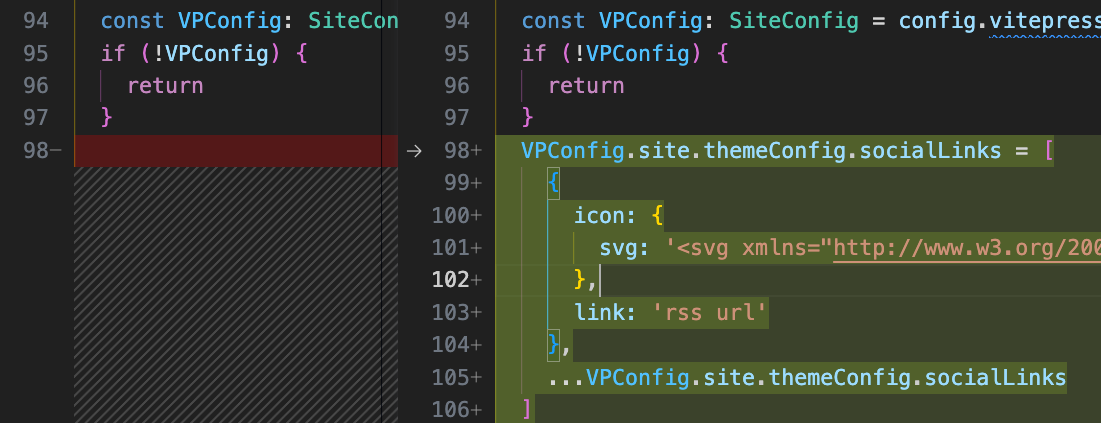
接着上述的demo,添加如下代码
VPConfig.site.themeConfig.socialLinks = [
{
icon: {
svg: 'svg icon'
},
link: 'rss url'
},
...VPConfig.site.themeConfig.socialLinks
]
svg的图标可以通过 xicons 这个网站查找
比如我这里找了一个 sun 的图标配上
启动博客后就能看见右上角这个小太阳了

MD文件获取与解析
这个是最核心的逻辑了,① 需要获取所有的 md 文件,② 解析里面的 frontmatter ③ 渲染HTML
这个在 vuejs/blog 中可以看到使用的是 VitePress 内置的 createContentLoader 方法(里面包含了上述3部分逻辑)
这里把其核心实现拆出来,方便大家理解和更好的自定义(笔者在插件里也没直接使用 createContentLoader 这个方法)
① 通过 fast-glob 获取所有的 md 文件
import glob from 'fast-glob'
const files = glob.sync(`${srcDir}/**/*.md`, { ignore: ['node_modules'] })
其中 srcDir 即文章所在的目录,可以通过如下方式获取到相对路径
// config 即 SiteConfig
const srcDir =
config.srcDir.replace(config.root, '').replace(/^\//, '') ||
process.argv.slice(2)?.[1] ||
'.'
② 通过 gray-matter 解析 frontmatter
这里frontmatter就是文章开头里两个---之间的内容
例如
---
title: 示例标题
description: 文章介绍
---
利用 gray-matter 解析
import matter from 'gray-matter'
import fs from 'fs'
for (const file of files) {
const fileContent = fs.readFileSync(file, 'utf-8')
const { data: frontmatter, excerpt } = matter(fileContent, {
excerpt: true
})
}
其中 excerpt 即为文章的摘要信息(description)
③ MD 渲染为 HTML
这个使用 VitePress 提供的 createMarkdownRenderer 即可
// 由于插件里最后构建成 CJS/ESM 两种格式,VitePress 最新的版本支持 ESM,因此需要动态引入
const { createMarkdownRenderer } = await import('vitepress')
const mdRender = await createMarkdownRenderer(
config.srcDir,
config.markdown,
config.site.base,
config.logger
)
for (const file of files) {
const fileContent = fs.readFileSync(file, 'utf-8')
// 生成html
const html = mdRender.render(fileContent)
}
RSS文件生成
通过上面的 markdown 文件的解析,我们已经拿到了所有的文章信息,接下来就是通过 feed 这个库生成 RSS 文件了
import { Feed } from 'feed'
const feedOptions = {
// ...
}
const feed = new Feed(feedOptions)
for (const file of files){
// 通过前面解析的信息,生成 feed item
feed.addItem({
title,
id: link,
link,
description,
content: html,
author: [
{
name: author,
...authorInfo
}
],
image: frontmatter?.cover,
date: new Date(date)
})
}
const RSSFilename = 'feed.rss'
const RSSFilepath = path.join(config.outDir, RSSFilename)
// 生成 rss 文件
writeFileSync(RSSFilepath, feed.rss2())
最后
插件的完整源码见 GitHub,欢迎大家试用和反馈
参考
为 VitePress 网站添加 RSS 订阅支持的更多相关文章
- 2019-9-2-给博客添加rss订阅
title author date CreateTime categories 给博客添加rss订阅 lindexi 2019-09-02 12:57:38 +0800 2018-2-13 17:23 ...
- 给博客添加rss订阅
如果是自己搭建博客,有一个问题是如何写一篇新的文章就可以告诉读者,你写了一篇新的?一个简单方法是使用 rss ,RSS订阅是站点用来和其他站点之间共享内容的一种简易方式,即Really Simple ...
- 安装FeedReader添加RSS订阅
#0x1 FeedReader FeedReader是一款功能齐全,界面优美的GTK+ 3RSS阅读器客户端,用于在线RSS服务. FeedReader目前支持Feedbin,Feedly,Fresh ...
- 为网站加入Drupal星球制作RSS订阅源
目前中文 Drupal 星球的版块还未成立,但大家的积极性挺高,不少站长都已经调整好自己的网站,生成了可供Drupal Planet 使用的RSS订阅源. 如果你也想让网站做好准备,可以不必再花上不少 ...
- 在自己的网站上使用RSS订阅功能
要增加RSS订阅功能其实很简单 就是填写一个规定好的xml文档,按照要求填好就可以实现 具体的步骤如下: 这是在网上查到的RSSxml文档 <?xml version="1.0&quo ...
- 做个简单的RSS订阅(ASP.NET Core),节省自己的时间
0x01 前言 因为每天上下班路上,午休前,都是看看新闻,但是种类繁多,又要自己找感兴趣的,所以肯定会耗费不少时间. 虽说现在有很多软件也可以订阅一些自己喜欢的新闻,要安装到手机,还是挺麻烦的.所以就 ...
- rome实现rss订阅与发布
1. 什么是RSS RSS也叫聚合RSS,是在线共享内容的一种简易方式(也叫聚合内容, 简易供稿,Really Simple Syndication(真正简单的聚合 )).通常在时效性比较强的内容上使 ...
- 如何用RSS订阅?
本文由云+社区发表 摘要:我们常常会有订阅别人文章的需求,有更新的时候希望能有提醒的功能,RSS就是这样一个订阅的方式.很多网站上看到RSS的入口,点进去以后总是显示一堆的XML代码,我们来看看怎么使 ...
- 利用Feed43为网站自制RSS源
什么是RSS,它可以做什么 快2020年了,RSS日渐式微,我也是去年机缘巧合下才开始使用的,以前只是听说过.RSS,全称Really Simple Syndication,又称简易信息聚合(也叫聚合 ...
- Rss 订阅:php动态生成xml格式的rss文件
Rss 简介: 简易信息聚合(也 叫聚合内容)是一种描述和同步网站内容的格式.使用RSS订阅能更快地获取信息,网站提供RSS输出,有利于让用户获取网站内容的最新更新.网络用户可以在客户端借助于支持RS ...
随机推荐
- 1451, 'Cannot delete or update a parent row: a foreign key constraint fails
问题描述:1451, 'Cannot delete or update a parent row: a foreign key constraint fails (`sysProDB4`.`IM003 ...
- 【Java】包名规范及整理
目录 前言 包名规范 总结 前言 最近学习Java的时候,有一个 class 需要在每一个 java文件中写一写,然后我喜欢一次实验的java文件放到一个 Package 中,这就导致了持续不断的报错 ...
- How to use the shell command to get the version of Linux Distributions All In One
How to use the shell command to get the version of Linux Distributions All In One 如何使用 shell 命令获取 Li ...
- 开源 API 网关-访问策略(二)
在上篇文章API网关:开源 API 网关-访问策略(一) 中,我们简单演示了如何在IP维度中对请求路径设置黑白名单,以此来限制客户端请求的权限和范围. 此外,Apinto网关为客户端提供了一种统一的. ...
- go语言编写算法
1.冒泡排序 // 冒泡排序 a := []uint8{9, 20, 10, 23, 7, 22, 88, 102} for i := 0; i < len(a); i++ { for k := ...
- 2023-06-14:我们从二叉树的根节点 root 开始进行深度优先搜索。 在遍历中的每个节点处,我们输出 D 条短划线(其中 D 是该节点的深度) 然后输出该节点的值。(如果节点的深度为 D,则其
2023-06-14:我们从二叉树的根节点 root 开始进行深度优先搜索. 在遍历中的每个节点处,我们输出 D 条短划线(其中 D 是该节点的深度) 然后输出该节点的值.(如果节点的深度为 D,则其 ...
- 计算机视觉重磅会议VAlSE2023召开,合合信息分享智能文档处理技术前沿进展
近期,2023年度视觉与学习青年学者研讨会 (Vision And Learning SEminar, VALSE) 圆满落幕.会议由中国人工智能学会.中国图象图形学学会主办,江南大学和无锡国家高新技 ...
- Java中AQS的原理与实现
目录 1:什么是AQS? 2:AQS都有那些用途? 3:我们如何使用AQS 4:AQS的实现原理 5:对AQS的设计与实现的一些思考 1:什么是AQS 随着计算机的算力越来越强大,各种各样的并行编 ...
- Codeforces Round #883 (Div. 3) A-G
比赛链接 A 代码 #include <bits/stdc++.h> using namespace std; using ll = long long; bool solve() { i ...
- 6月有奖征文挑战,ZEGO开发者社区首季活动报名入口!
前 言 哈喽 开发者们: ZEGO即构科技作为一家20年技术积累的音视频云服务商,已经为全球200+个国家的企业服务,单日通话时长突破30亿+分钟,现下即构开发者社区举办首期征文活动!本次征文活动围绕 ...