【USENIX ATC】支持异构GPU集群的超大规模模型的高效的分布式训练框架Whale
简介: 高效大模型训练框架Whale(EPL)入选USENIX ATC
作者:张杰、贾贤艳
近日,阿里云机器学习PAI关于深度学习模型高效的分布式训练框架的论文《 Whale: Efficient Giant Model Training over Heterogeneous GPUs 》被计算机系统领域国际顶级学术会议USENIX ATC'22接收。
Whale是阿里云机器学习PAI平台自研的分布式训练框架,开源后的名称是EPL(Easy Parallel Library),Whale通过对不同并行化策略进行统一抽象、封装,在一套分布式训练框架中支持多种并行策略,并进行显存、计算、通信等全方位的优化,来提供易用、高效的分布式训练框架。Whale提供简洁易用的接口,用户只需添加几行annotation即可组合各种混合并行策略。同时Whale提供了基于硬件感知的自动化分布式并行策略,感知不同硬件的算力、存储等资源,根据这些资源来合理的切分模型,均衡不同硬件上的计算量,最大化计算效率。借助Whale的硬件感知负载均衡算法,Bert-Large、Resnet50和GNMT模型 在异构GPU训练上提速1.2至1.4倍。同时,使用Whale框架, 万亿M6模型使用480 张 V100在3天内完成预训练。相比此前业界训练同等规模的模型,节省算力资源超80%,且训练效率提升近11倍。进一步使用512 GPU在10天内即训练出具有可用水平的10万亿模型。
背景和挑战
随着近些年深度学习的火爆,模型的参数规模也增长迅速,OpenAI数据显示:
- 2012年以前,模型计算耗时每2年增长一倍,和摩尔定律保持一致;
- 2012年后,模型计算耗时每3.4个月翻一倍,远超硬件发展速度;
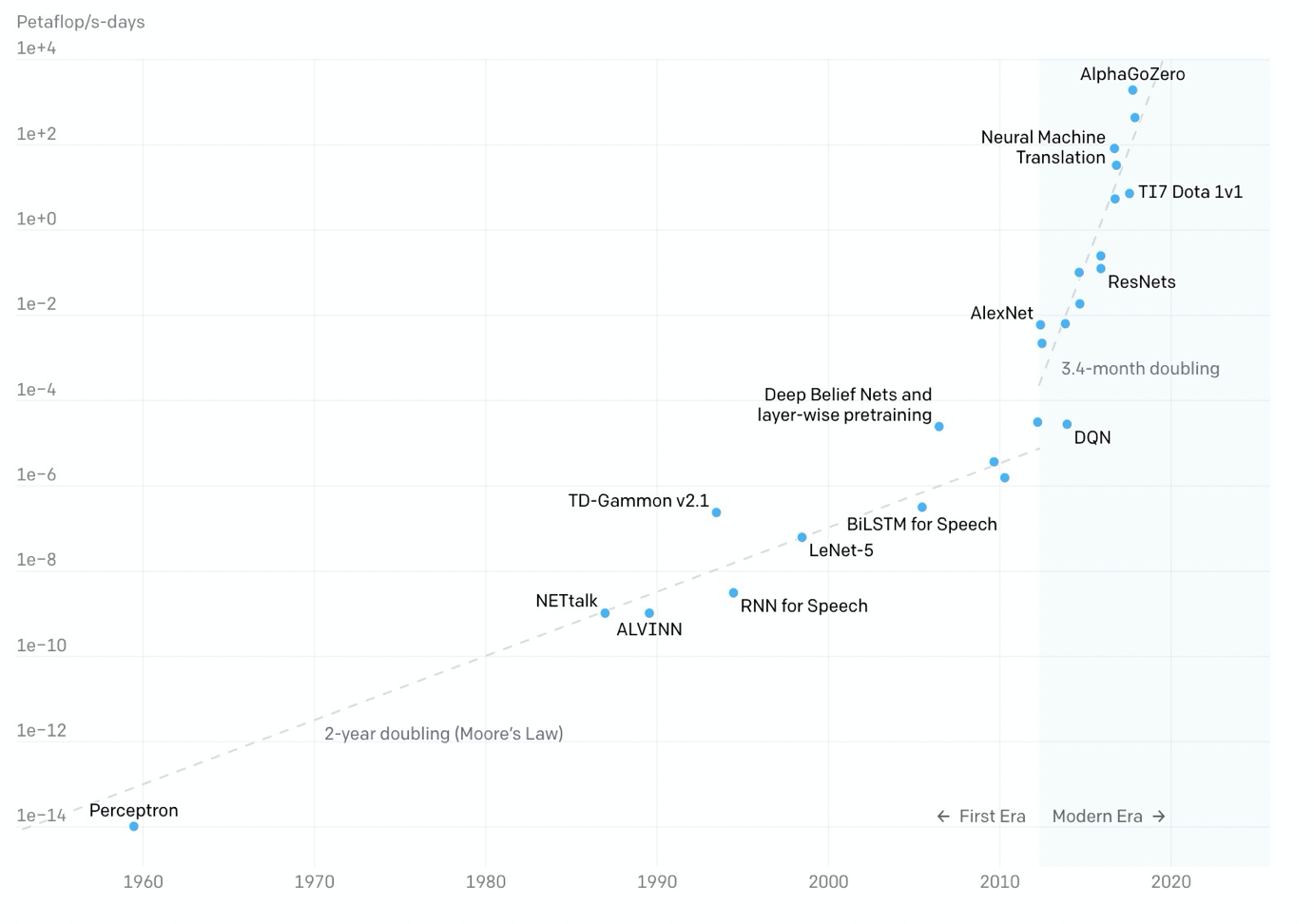
特别最近两年模型参数规模飞速增长,谷歌、英伟达、阿里、智源研究院都发布了万亿参数模型,有大厂也发布了百亿、千亿参数模型。随着模型参数规模增大,模型效果也在逐步提高,但同时也为训练框架带来更大的挑战。当前已经有一些分布式训练框架,例如:Horovod、Tensorflow Estimator、PyTorch DDP等支持数据并行,Gpipe、PipeDream、PipeMare等支持流水并行,Mesh Tensorflow、FlexFlow、OneFlow、MindSpore等支持算子拆分,但当我们要训练一个超大规模的模型时会面临一些挑战:
- 当前的分布式训练框架只支持少量的并行策略,缺乏一个统一的抽象来支持所有的并行策略及其混合策略。
- 实现复杂的并行策略需要大量的模型代码改造和对底层系统的理解,大大增加了用户的使用难度。
- 由于集群中异构GPU计算能力和显存的差异,静态的并行化策略无法充分利用异构资源实现高效训练。
破局
为了应对当前分布式训练的挑战,我们研发了高效、通用、硬件感知的分布式训练框架Whale。Whale抽象并定义了两个分布式原语(replicate和split) 。用户可以通过在模型上添加几行原语标记,即来表达和转换各种并行化策略及其组合,极大降低了分布式框架的使用门槛。Whale runtime将用户的标记信息融合到计算图中,自动完成模型的并行化优化。同时Whale提供了基于硬件感知的自动化分布式并行策略,优化在异构GPU集群上分布式训练性能。Whale的设计很好地平衡了模型用户的干预和系统优化机会,让每一个算法工程师都能轻松高效训练分布式大模型任务。
技术架构
Whale框架如下图所示,主要分为以下几个模块:
- 接口层:用户的模型编程接口基于TensorFlow,同时Whale提供了易用的并行化策略表达接口,让用户可以组合使用各种混合并行策略;
- 中间表达层:将用户模型和并行策略转成化内部表达,通过TaskGraph、VirtualDevices和策略抽象来表达各种并行策略;
- 并行化引擎层:基于中间表达,Whale会对计算图做策略探索,结合硬件资源进行显存/计算/通信优化,并自动生成分布式计算图。
- Runtime执行引擎:将分布式执行图转成TFGraph,再调用TF 的Runtime来执行;

并行化策略表达
Whale通过strategy annotation的方式来划分模型为多个TaskGraph,并在此基础上进行并行化。 Whale有两类strategy:replicate 和 split。通过这两种并行化接口,可以表达出各种不同的并行化策略,例如:
- 数据并行: 下面这个例子是一个数据并行的例子,每个模型副本用一张卡来计算。如果用户申请了8张卡,就是一个并行度为8的数据并行任务。

- 流水并行:在下面的例子里,模型被切分成2个 TaskGraph, "stage0"和"stage1",用户可以通过配置pipeline.num_micro_batch参数来设定pipeline的micro batch数量。 在这个例子里,"stage_0"和"stage_1"组成一个模型副本,共需要2张GPU卡。如果用户申请了8张卡,Whale会自动在pipeline外嵌套一层并行度为4的数据并行(4个pipeline副本并行执行)。

- 算子拆分并行:在以下例子中,Whale会对split scope下的模型定义做拆分,并放置在不同的GPU卡上做并行计算。

- 同时Whale支持对上述并行策略进行组合和嵌套,来组成各种混合并行策略,更多示例可以参考开源代码的文档和示例。
Parallel Planner
Paraller Planner是Whale runtime的重要一环,它的职责是生成一个高效的分布式执行plan。Parallel Planner的流程包含 (a) Paraller Planner的输入包含用户模型、用户标记(可选)、硬件计算资源和其他用户配置配置。 (b) 将物理计算资源映射成VirtualDevice, 用户无需担心如何将算子放置在分布式物理设备上。(c) 模型被分割成TaskGraph子图。因为Whale允许对不同的TaskGraph应用不同的分布式策略,所以在TaskGraph之间可能存在输入/输出shape不匹配。在这种情况下,Paraller Planner将自动在两个TaskGraphs之间插入相应的桥接层。

硬件感知的负载均衡算法
当模型训练资源包含异构硬件(比如混合了V100和T4),硬件感知的负载均衡算法可以提高在异构资源下的训练效率。Whale设计了两种平衡策略:Intra-TaskGraph和Inter-TaskGraph的平衡。
(1)对于Intra-TaskGraph的计算平衡,Whale会profile出模型的算力FLOP,并按照机器的计算能力按比例分配对应的计算负载,以此均衡每个step不同卡型上的模型计算时间。对于数据并行,我们可以通过调整不同副本上的batch大小来实现计算负载的均衡(保持全局batch不变)。对于算子拆分,我们可以通过不均匀的维度拆分来实现不同卡上子模块的计算负载均衡。
(2)当多个TaskGraph在多个异构GPU上执行流水并行,我们需要Inter-TaskGraph的计算平衡来提升整体的计算效率。由于流水并行的计算特点,前面的TaskGraph会比后面的TaskGraph多缓存一些前向计算的结果,因此对于Transformer类模型均衡layer切分的情况下,前面的TaskGraph会有更大的显存压力。因此在TaskGraph放置的时候,Whale会优先将前面的TaskGraph放置在显存容量更大的GPU卡上。与此同时,Whale会按照GPU卡的算力去切分模型,使得切分后的TaskGraph计算load和GPU算力成正比。
应用示例
借助Whale框架,我们4行代码实现M6模型数据并行+专家并行的混合并行训练。

如下图所示,MoElayer采用专家并行,其他layer采用数据并行:

并首次在480 V100 上,3天内完成万亿M6模型的预训练。相比此前业界训练同等规模的模型,此次仅使用480张V100 32G GPU就成功训练出万亿模型M6,节省算力资源超80%,且训练效率提升近11倍。进一步使用512 GPU在10天内即训练出具有可用水平的10万亿模型。
结语
Whale 通过统一的抽象支持各种并行化策略,并提出简洁的并行化原语来提高框架的易用性。同时,Whale提供了异构硬件感知的自动分布式计算图优化,实现高效的分布式模型训练。我们希望Whale能够成为一个大规模深度学习训练的基石,进一步推进模型算法创新和系统优化,使大模型训练技术能够广泛应用在实际生产环境中。Whale已经开源(https://github.com/alibaba/EasyParallelLibrary),欢迎大家来试用和共建。
- 论文名称:Whale: Efficient Giant Model Training over Heterogeneous GPUs
- 论文作者:贾贤艳,江乐,王昂,肖文聪,石子骥,张杰,李昕元,陈浪石,李永,郑祯,刘小勇,林伟
- 论文链接:https://arxiv.org/pdf/2011.09208.pdf
- 开源链接:https://github.com/alibaba/easyparallellibrary
- 参考文献:
[1] Junyang Lin, An Yang, Jinze Bai, Chang Zhou, Le Jiang, Xianyan Jia, Ang Wang, Jie Zhang, Yong Li, Wei Lin, et al. M6-10t: A sharing-delinking paradigm for effi- cient multi-trillion parameter pretraining. arXiv preprint arXiv:2110.03888, 2021.
[2] Junyang Lin, Rui Men, An Yang, Chang Zhou, Ming Ding, Yichang Zhang, Peng Wang, Ang Wang, Le Jiang, Xianyan Jia, Jie Zhang, Jianwei Zhang, Xu Zou, Zhikang Li, Xiaodong Deng, Jie Liu, Jinbao Xue, Huiling Zhou, Jianxin Ma, Jin Yu, Yong Li, Wei Lin, Jingren Zhou, Jie Tang, and Hongxia Yang. M6: A chinese multimodal pretrainer, 2021.
[3] William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity, 2021.
[4] Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R Devanur, Gregory R Ganger, Phillip B Gibbons, and Matei Zaharia. Pipedream: gen- eralized pipeline parallelism for dnn training. In Pro- ceedings of the 27th ACM Symposium on Operating Systems Principles, pages 1–15, 2019.
了解更多精彩内容,欢迎关注我们的阿里灵杰公众号,获取大数据+AI最新资讯
原文链接:http://click.aliyun.com/m/1000348768/
本文为阿里云原创内容,未经允许不得转载。
【USENIX ATC】支持异构GPU集群的超大规模模型的高效的分布式训练框架Whale的更多相关文章
- 深度学习GPU集群管理软件 OpenPAI 简介
OpenPAI:大规模人工智能集群管理平台 2018年5月22日,在微软举办的“新一代人工智能开放科研教育平台暨中国高校人工智能科研教育高峰论坛”上,微软亚洲研究院宣布,携手北京大学.中国科学技术大学 ...
- 玩转nodeJS系列:使用原生API实现简单灵活高效的路由功能(支持nodeJs单机集群),nodeJS本就应该这样轻快
前言: 使用nodeJS原生API实现快速灵活路由,方便与其他库/框架进行整合: 1.原生API,简洁高效的轻度封装,加速路由解析,nodeJS本就应该这样轻快 2.不包含任何第三方库/框架,可以灵活 ...
- logstash7.3版本不支持从redis集群中拉取数据
filebeat可以把收集到的日志传输到redis集群中,但是logstash如何从从redis集群中拉取数据的呢? ogstash使用的是7.3版本 经过查看官网文档,发现logstash7.3版本 ...
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- Spring集成jedis支持Redis3.0集群
接着上一节,我们通过spring FactoryBean实现redis 3.0集群JedisCluster与spring集成. http://www.linuxidc.com/Linux/2016- ...
- java架构师负载均衡、高并发、nginx优化、tomcat集群、异步性能优化、Dubbo分布式、Redis持久化、ActiveMQ中间件、Netty互联网、spring大型分布式项目实战视频教程百度网盘
15套Java架构师详情 * { font-family: "Microsoft YaHei" !important } h1 { background-color: #006; ...
- ZooKeeper伪分布集群安装及使用 RMI+ZooKeeper实现远程调用框架
使用 RMI + ZooKeeper 实现远程调用框架,包括ZooKeeper伪集群安装和代码实现两部分. 一.ZooKeeper伪集群安装: 1>获取ZooKeeper安装包 下载地址:ht ...
- Java集群优化——dubbo+zookeeper构建高可用分布式集群
不久前,我们讨论过Nginx+tomcat组成的集群,这已经是非常灵活的集群技术,但是当我们的系统遇到更大的瓶颈,全部应用的单点服务器已经不能满足我们的需求,这时,我们要考虑另外一种,我们熟悉的内容, ...
随机推荐
- epoll和ractor的粗浅理解
我们继续上篇的文章继续更新我们的代码. 首先就是介绍一下epoll的三个函数. epoll_create epoll_ctl epoll_wait 如何去理解这3个函数,我是这样去理解这个函数, 就像 ...
- Qt HTTP网络相关GET,POST(HTTP 模拟POST 表单(multipartform)最简单和正式的方法)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- linux使用hostapd+dnsmasq管理多张网卡,搭建dns服务器,并发射wifi热点(支持360wifi等等)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文发布于 2015-03-03 18:37:39 ...
- 9、Azure DevOps安装部署篇
下载地址 微软默认提供了两个版本的下载:Azure DevOps Server和Azure DevOps Server Express . Azure DevOps Server 提供90天试用的收费 ...
- Spring Boot学习日记5
启动器 spring-boot-starter 启动器:说白了就是SpringBoot的启动场景 比如spring-boot-starter-web,会帮我们自动导入web环境所有的依赖 spring ...
- 浅谈React与SolidJS对于JSX的应用
React将JSX这一概念深入人心.但,并非只有React利用了JSX,VUE.SolidJS等JS库或者框架都使用了JSX这一概念.网上已经有大量关于JSX的概念与形式的讲述文章,不在本文的讨论范围 ...
- 云VR的未来发展方向
随着元宇宙元年的到来,VR正呈现出蓬勃的发展势头.然而,更好的用户体验大多依赖于高性能PC或主机进行本地渲染,这使得用户的VR消费成本更高,在一定程度上影响了产业发展,成为业界亟待解决的问题. 的确, ...
- 爬虫实战:从HTTP请求获取数据解析社区
在过去的实践中,我们通常通过爬取HTML网页来解析并提取所需数据,然而这只是一种方法.另一种更为直接的方式是通过发送HTTP请求来获取数据.考虑到大多数常见服务商的数据都是通过HTTP接口封装的,因此 ...
- Spring Boot框架中针对数据文件模板的下载总结
1.前言 在我们的日常开发中,经常会碰到注入导入Excel数据到系统中的需求,而在导入Excel数据时,一般的业务系统都会提供数据的Excel模板,只有提交的Excel数据满足业务系统要求的模板时,数 ...
- MySQL备份还原工具
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...