03 什么是预训练(Transformer 前奏)
预训练有什么用
机器学习:偏数学(《统计学习方法》-李航)
深度学习(人工智能)的项目:大数据支持(主流)
我们很多项目没有大数据支持(小数据)
猫狗分类任务:100 张猫和狗的图片 --》给你一张图片,分出是猫还是狗(无法解决的一个问题,精度很低)
100000 张鹅和鸭的图片(已知,有人做过的,通过这10w 张图片做了一个模型 A)

有人发现,浅层通用的(横竖撇捺)
我通过10w个鹅和鸭训练了一个模型 A,100 层的 CNN
任务 B:100 张猫和狗的图片,分类 --》 训练处 100层的 CNN,不可能实现的
尝试使用 A 的前 50 层,使用 100 层去完成任务 B
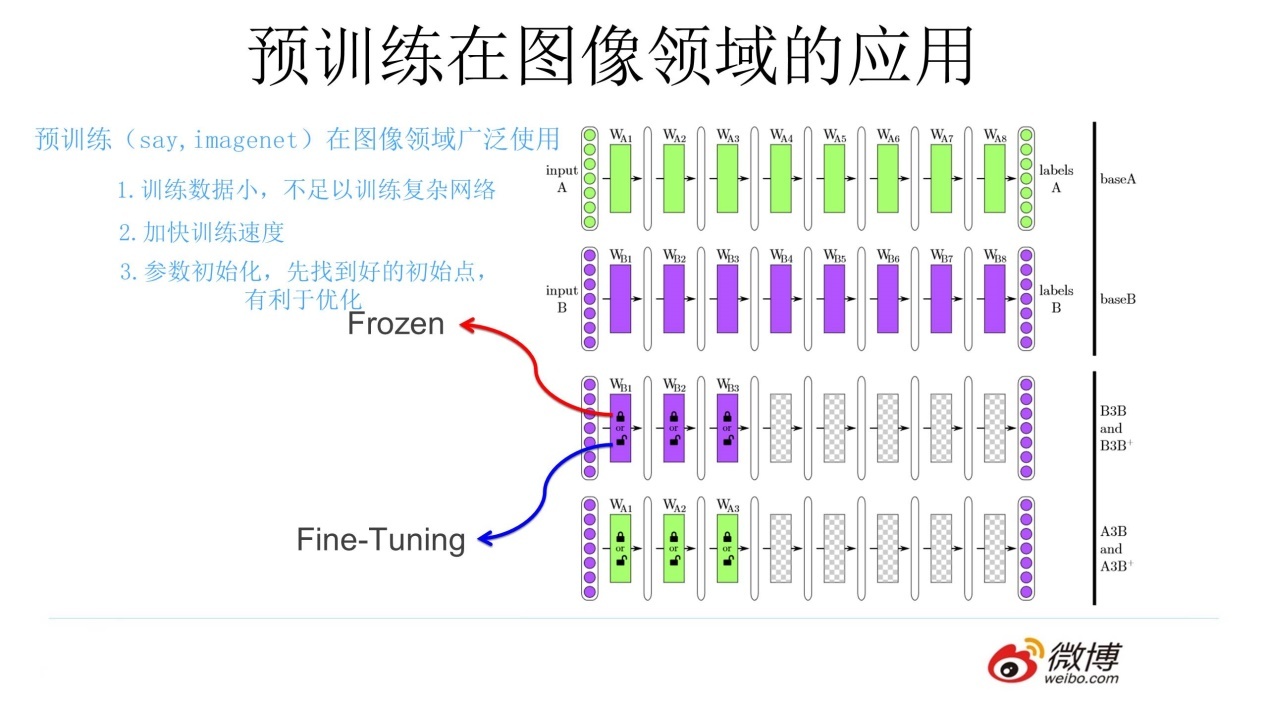
- 冻结:浅层参数不变
- 微调:浅层参数会跟着任务 B 训练而改变
预训练是什么
通过一个已经训练好的模型 A,去完成一个小数据量的任务 B(使用了模型 A 的浅层参数)
任务 A 和任务 B 极其相似
预训练怎么用
fairseq 、transformers 库
总结
一个任务 A,一个任务 B,两者极其相似,任务 A 已经训练处一个模型 A,使用模型 A 的浅层参数去训练任务 B,得到模型 B,1.
03 什么是预训练(Transformer 前奏)的更多相关文章
- 【译】深度双向Transformer预训练【BERT第一作者分享】
目录 NLP中的预训练 语境表示 语境表示相关研究 存在的问题 BERT的解决方案 任务一:Masked LM 任务二:预测下一句 BERT 输入表示 模型结构--Transformer编码器 Tra ...
- 【转载】BERT:用于语义理解的深度双向预训练转换器(Transformer)
BERT:用于语义理解的深度双向预训练转换器(Transformer) 鉴于最近BERT在人工智能领域特别火,但相关中文资料却很少,因此将BERT论文理论部分(1-3节)翻译成中文以方便大家后续研 ...
- 知识图谱顶会论文(KDD-2022) kgTransformer:复杂逻辑查询的预训练知识图谱Transformer
论文标题:Mask and Reason: Pre-Training Knowledge Graph Transformers for Complex Logical Queries 论文地址: ht ...
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
- 预训练语言模型的前世今生 - 从Word Embedding到BERT
预训练语言模型的前世今生 - 从Word Embedding到BERT 本篇文章共 24619 个词,一个字一个字手码的不容易,转载请标明出处:预训练语言模型的前世今生 - 从Word Embeddi ...
- 知识增强的预训练语言模型系列之KEPLER:如何针对上下文和知识图谱联合训练
原创作者 | 杨健 论文标题: KEPLER: A unified model for knowledge embedding and pre-trained language representat ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- 【算法】Bert预训练源码阅读
Bert预训练源码 主要代码 地址:https://github.com/google-research/bert create_pretraning_data.py:原始文件转换为训练数据格式 to ...
- 文本分类实战(一)—— word2vec预训练词向量
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 第二十四节,TensorFlow下slim库函数的使用以及使用VGG网络进行预训练、迁移学习(附代码)
在介绍这一节之前,需要你对slim模型库有一些基本了解,具体可以参考第二十二节,TensorFlow中的图片分类模型库slim的使用.数据集处理,这一节我们会详细介绍slim模型库下面的一些函数的使用 ...
随机推荐
- (续) MindSpore 如何实现一个线性回归 —— Demo示例
前文: https://www.cnblogs.com/devilmaycry812839668/p/14975860.html 前文中我们使用自己编写的损失函数和单步梯度求导来实现算法,这里是作为扩 ...
- baselines算法库common/tile_images.py模块分析
该模块只有一个函数,全部内容: import numpy as np def tile_images(img_nhwc): """ Tile N images into ...
- java关于二维数组的操作
代码: ''' package tests; public class Yanghui { public static void main(String[] args) { //声明二维数组的三种方式 ...
- 删除个文件夹,vfs2上传文件到ftp就异常553,这么不经事吗
开心一刻 今天逛街碰到街头采访,一上来就问我敏感话题 主持人:小哥哥,你单身吗 我:是啊 主持人:你找女朋友的话,是想找一个小奶猫呢,还是小野猫呢 我沉思了一下,叹气道:如果可以的话,我想找个人,而且 ...
- 08-canvas绘制表格
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="U ...
- Git删除当前分支下的所有历史版本与log
- 视频中ppt、代码、ubuntu环境请扫描下面二维码,回复:ubuntu,即可获得
历时4个多月,第一期Linux驱动视频录制完毕, 一共32期,现在全部同步到了B站. 如果你觉得视频对你有用,建议大家多多点赞,投投免费硬币, 算是对我辛苦的劳动的认可. 视频中ppt.代码.ubun ...
- 技术如何通过API接口获取自己想要同款商品的数据
确定数据源: 首先,你需要确定哪些平台或服务提供商提供了你感兴趣的商品数据.例如,电商平台.品牌商.市场调研公司等. 了解API文档: 访问提供商的开发者门户网站,阅读API文档.文档会详细介绍如何使 ...
- LaTeX 几种中文字体的比较
根据自己的喜好给常见的几个中文字体的打分: 字体选项 字体名 得分 adobe Adobe 宋体 Std 5 fandol FandolSong 0 founder 方正书宋_GBK 10 hanyi ...
- 【YashanDB知识库】如何远程连接、使用YashanDB?
问题现象 在各个项目实施中,我们经常遇到客户.开发人员需要连接和使用YashanDB但不知如何操作的问题,本文旨在介绍远程连接.使用YashanDB的几种方式. 问题的风险及影响 无风险 问题影响的版 ...