Spark 开源新特性:Catalyst 优化流程裁剪
摘要:为了解决过多依赖 Hive 的问题, SparkSQL 使用了一个新的 SQL 优化器替代 Hive 中的优化器, 这个优化器就是 Catalyst。
本文分享自华为云社区《Spark 开源新特性:Catalyst 优化流程裁剪》,作者:hzjturbo 。
1. 问题背景
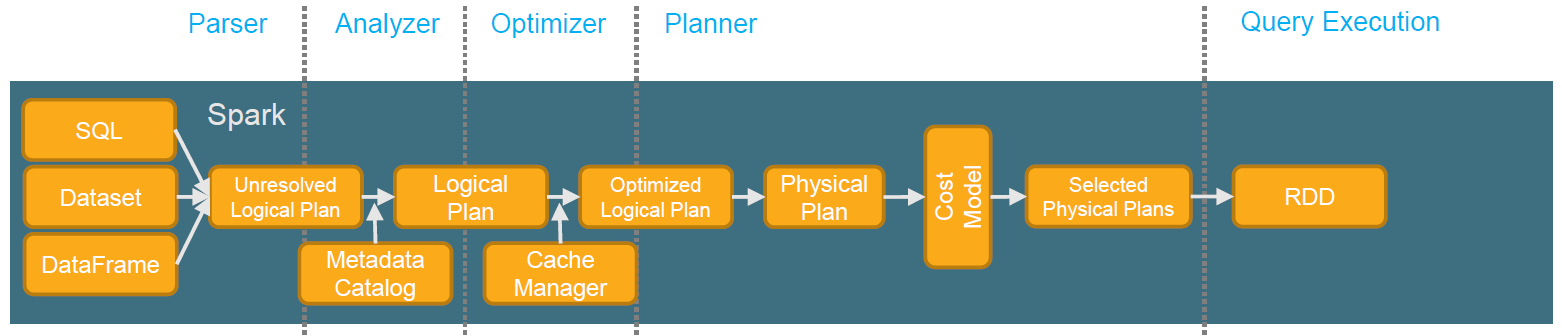
上图是典型的Spark Catalyst优化器的布局,一条由用户输入的SQL,到真实可调度执行的RDD DAG任务,需要经历以下五个阶段:
- Parser: 将SQL解析成相应的抽象语法树(AST),spark也称为 Unresolved Logical Plan;
- Analyzer: 通过查找Metadata的Catalog信息,将 Unresolved Logical Plan 变为 Resolved Logical Plan,这个过程会做表、列、数据类型等做校验;
- Optimizer: 逻辑优化流程,通过一些优化规则对匹配上的Plan做转换,得到优化后的逻辑Plan
- Planner:根据Optimized Logical Plan的统计信息等转换成相应的Physical Plan
- Query Execution: 主要是执行前的一些preparations优化,比如AQE, Exchange Reuse, CodeGen stages合并等
上述的五个阶段中,除了Parser (由Antlr实现),其他的每个阶段都是由一个个规则(Rule)构成,总共大约有200+个,对于不同的规则,还可能需要跑多次,所以对于相对比较复杂的查询,可能得到一个executed Plan都需要耗费数秒。
Databricks内部基准测试表明,对于TPC-DS查询,每个查询平均调用树转换函数约280k次,这远远超出了必要的范围。因此,我们探索在每个树节点中嵌入BitSet,以传递自身及其子树的信息,并利用计划不变性来修剪不必要的遍历。通过原型实现验证:在TPC-DS基准测试中,我们看到优化的速度约为50%,分析的速度约为30%,整个查询编译的速度约为34%(包括Hive元存储RPC和文件列表)[1]。
2. 设计实现
2.1 Tree Pattern Bits and Rule Id Bits
- Tree pattern bits
在TreeNode 增加nodePatterns属性,所有继承该类的节点可以通过复写该属性值来标识自己的属性。
/**
* @return a sequence of tree pattern enums in a TreeNode T. It does not include propagated
* patterns in the subtree of T.
*/
protected val nodePatterns: Seq[TreePattern] = Seq()
TreePattern 是一个枚举类型, 对于每个节点/表达式都可以为其设置一个TreePattern方便标识,具体可见 TreePatterns.scala 。
例如对于Join节点的nodePatterns:
override val nodePatterns : Seq[TreePattern] = {
var patterns = Seq(JOIN)
joinType match {
case _: InnerLike => patterns = patterns :+ INNER_LIKE_JOIN
case LeftOuter | FullOuter | RightOuter => patterns = patterns :+ OUTER_JOIN
case LeftSemiOrAnti(_) => patterns = patterns :+ LEFT_SEMI_OR_ANTI_JOIN
case NaturalJoin(_) | UsingJoin(_, _) => patterns = patterns :+ NATURAL_LIKE_JOIN
case _ =>
}
patterns
}
- Rule ID bits
将规则ID的缓存BitSet嵌入到每个树/表达式节点T中,这样我们就可以跟踪规则R对于根植于T的子树是有效还是无效。这样,如果R在T上被调用,并且已知R无效,如果R再次应用于T(例如,R位于定点规则批处理中),我们可以跳过它。这个想法最初被用于Cascades optimizer,以加快探索性规划。
Rule:
abstract class Rule[TreeType <: TreeNode[_]] extends SQLConfHelper with Logging {
// The integer id of a rule, for pruning unnecessary tree traversals.
protected lazy val ruleId = RuleIdCollection.getRuleId(this.ruleName)
TreeNode:
/**
* A BitSet of rule ids to record ineffective rules for this TreeNode and its subtree.
* If a rule R (which does not read a varying, external state for each invocation) is
* ineffective in one apply call for this TreeNode and its subtree, R will still be
* ineffective for subsequent apply calls on this tree because query plan structures are
* immutable.
*/
private val ineffectiveRules: BitSet = new BitSet(RuleIdCollection.NumRules)
2.2 Changes to The Transform Function Family
改造后的transform 方法相比之前的多了两个判断,如下所示
def transformDownWithPruning(
cond: TreePatternBits => Boolean, // 判断是否存在可优化的节点,由规则设计者所提供
ruleId: RuleId = UnknownRuleId // 不会生效的规则ID,自动更新
)(rule: PartialFunction[BaseType, BaseType]): BaseType = {
// 如果上述两个条件存在一个不满足,直接跳过本次规则
if (!cond.apply(this) || isRuleIneffective(ruleId)) {
return this
}
// 执行rule的逻辑
val afterRule = CurrentOrigin.withOrigin(origin) {
rule.applyOrElse(this, identity[BaseType])
} // Check if unchanged and then possibly return old copy to avoid gc churn.
if (this fastEquals afterRule) {
val rewritten_plan = mapChildren(_.transformDownWithPruning(cond, ruleId)(rule))
// 如果没生效,把规则ID加入到不生效的BitSet里
if (this eq rewritten_plan) {
markRuleAsIneffective(ruleId)
this
} else {
rewritten_plan
}
} else {
// If the transform function replaces this node with a new one, carry over the tags.
afterRule.copyTagsFrom(this)
afterRule.mapChildren(_.transformDownWithPruning(cond, ruleId)(rule))
}
}
2.3 Changes to An Individual Rule
规则的例子:
object OptimizeIn extends Rule[LogicalPlan] with SQLConfHelper {
def apply(plan: LogicalPlan): LogicalPlan = plan transform ({
case q: LogicalPlan => q transformExpressionsDown ({
case In(v, list) if list.isEmpty => ...
case expr @ In(v, list) if expr.inSetConvertible => ...
}, _.containsPattern(IN), ruleId) // 必须包含IN
}, _.containsPattern(IN), ruleId) // 必须包含IN
}
3. 测试结果
在Delta中使用TPC-DS SF10对TPC-DS查询编译时间进行了基准测试。结果如下:
- 图1显示了查询编译速度;
- 表1显示了几个关键树遍历函数的调用计数和CPU减少的细分。
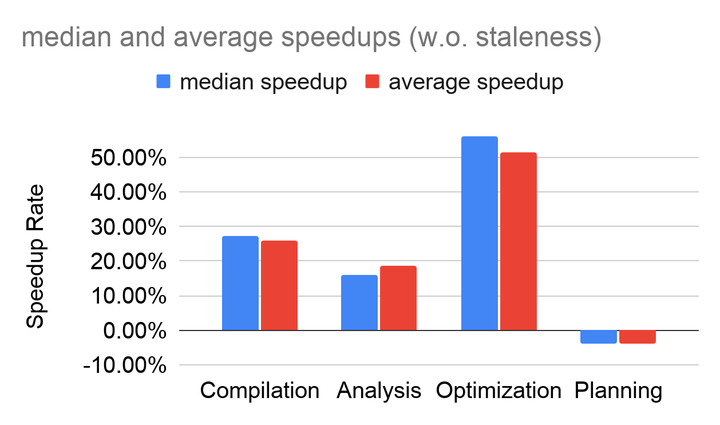
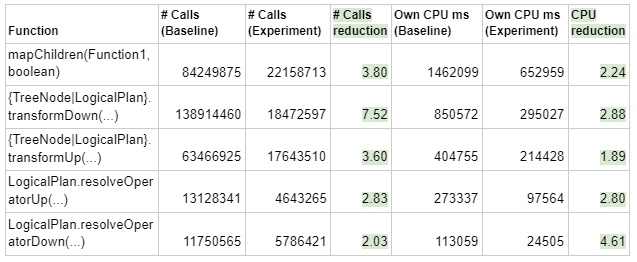
我简单运行了开版本的TPCDSQuerySuite,该测试会把TPCDS的语句解析优化,并且检查下生成的代码(CodeGen),平均耗时的时间为三次运行得到的最优值, 得到的结果如下:
- 合入PR前[2], 包含156个Tpcds查询,平均总耗时~56s
- 最新Spark开源代码,包含150个Tpcds查询,平均总耗时~19s
之所以最新的Tpcds查询比合入PR前的条数少6条,是因为后续有个减少重复TPCDS的PR。总时长优化前是优化后的两倍多。
参考引用
[1]. [SPARK-34916] Tree Traversal Pruning for Catalyst Transform/Resolve Function Families. SISP
[2]. [SPARK-35544][SQL] Add tree pattern pruning to Analyzer rules.
[3]. Building a SIMD Supported Vectorized Native Engine for Spark SQL. link
Spark 开源新特性:Catalyst 优化流程裁剪的更多相关文章
- 【php】php7新特性及其优化原理
php7.x版本系列相比之前的php的版本提交性能提高了不少,这里面其中的一些主要改变是性能提高的关键,主要有以下内容. 1.zval使用栈内存 在zend引擎和扩展中,经常要创建php变量,其底 ...
- 【译】 Node.js v0.12的新特性 -- 性能优化
原文: https://strongloop.com/strongblog/performance-node-js-v-0-12-whats-new/ January 21, 2014/in Comm ...
- Android7.0新特性,及Android N适配
新特性部分 Android 7.0 Nougat 提供新功能以提升性能.生产效率和安全性,主要新增了下面的新特性和优化: 一.新的Notification Android N 添加了很多新的notif ...
- 构建基于WinRT的WP8.1 App 02:数据绑定新特性
基于WinRT的Windows Phone 8.1以及Windows 8.1中Xaml数据绑定增加了一些新特性. FallBackValue属性:FallBackValue在绑定的值属性值不存在时,可 ...
- QQ音乐:React v16 新特性实践
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由QQ音乐技术团队发表于云+社区专栏 自从去年9月份 React 团队发布了 v16.0 版本开始,到18年3月刚发布的 v16.3 版 ...
- 你应该知道的Python3.6、3.7、3.8新特性
很多人在学习了基本的Python语言知识后,就转入应用阶段了,后期很少对语言本身的新变化.新内容进行跟踪学习和知识更新,甚至连已经发布了好几年的Python3.6的新特性都缺乏了解. 本文列举了Pyt ...
- HTML新特性--canvas绘图-文本
一.html5新特性--canvas绘图-文本(重点) #常用方法与属性 -ctx.strokeText(str,x,y); 绘制描边文字(空心) str:绘制文本 x,y:字符串左上角位置(以文 ...
- Spark 3.0 新特性 之 自适应查询与分区动态裁剪
Spark憋了一年半的大招后,发布了3.0版本,新特性主要与Spark SQL和Python相关.这也恰恰说明了大数据方向的两大核心:BI与AI.下面是本次发布的主要特性,包括性能.API.生态升级. ...
- 深入研究Spark SQL的Catalyst优化器(原创翻译)
Spark SQL是Spark最新和技术最为复杂的组件之一.它支持SQL查询和新的DataFrame API.Spark SQL的核心是Catalyst优化器,它以一种新颖的方式利用高级编程语言特性( ...
- Apache Spark 1.6公布(新特性介绍)
Apache Spark 1.6公布 CSDN大数据 | 2016-01-06 17:34 今天我们很高兴可以公布Apache Spark 1.6,通过该版本号,Spark在社区开发中达到一个重要的里 ...
随机推荐
- Fiddler安装,使用及汉化教程
Fiddler安装及汉化教程 一.下载安装 1.下载 官网链接:https://www.telerik.com/download/fiddler 左侧填写用途,邮箱及城市,然后下载就可以 左侧下载即D ...
- Mysql [Show global status] 命令 参数详解(转)
Aborted_clients:由于客户端没有正确关闭连接导致客户端终止而中断的连接数. Aborted_connects:试图连接到MySQL服务器而失败的连接数. Binlog_cache_dis ...
- IIS和PHP相关权限问题及解决方案_500错误_500.19 - Internal Server Error与401未授权错误_401.3 - Unauthorized
在IIS添加网站(假设站点为xxx.yyy.com,本例假设IIS版本为7.5或以上),如果采用IIS默认配置,会在创建站点同时创建相应同名的"应用程序池"(也是xxx.yyy.c ...
- 使用Python将MySQL查询结果导出到Excel(xlsxwriter)
在实际工作中,我们经常需要将数据库中的数据导出到Excel表格中进行进一步的分析和处理.Python中的pymysql和xlsxwriter库提供了很好的解决方案,使得这一过程变得简单而高效. 建立数 ...
- 提升运维效率:轻松掌握JumpServer安装和使用技巧
前言 JumpServer 是一个开源的跳板机的解决方案,提供了对远程服务器的安全访问.会话录制和审计.用户身份管理等功能,适用于需要管理机器资源&大量服务器资源的情况. 本文将在分享 doc ...
- 原生JS实现视频截图
视频截图效果预览 利用Canvas进行截图 要用原生js实现视频截图,可以利用canvas的绘图功能 ctx.drawImage,只需要获取到视频标签,就可以通过drawImage把视频当前帧图像绘制 ...
- Git如何回到拉取之前的代码
1.执行git reflog命令查看你的历史变更记录: 2.git reset --hard 2aee3f(拉代码之前的提交记录) Git基础命令总结请参考:https://blog.csdn.net ...
- 电子元器件工厂的金蝶 ERP 与赛意 WMS 系统数据集成平台进行对接
项目背景 国内某晶振集成电路研发单位,涵盖从产品开发.设计.生产.销售.服务等各个环节.需要全面建成以ERP.WMS.BOM.PLM.DMS.SRM.OA 为核心的企业信息系统,支持研发.生产.营销. ...
- [ARC165E] Random Isolation
Problem Statement There is a tree with $N$ vertices numbered $1$ to $N$. The $i$-th edge connects ve ...
- [CF1601C] Optimal Insertion
Optimal Insertion 题面翻译 题目大意 给定两个序列 \(a,b\),长度分别为 \(n,m(1\leq n,m\leq 10^6)\).接下来将 \(b\) 中的所有元素以任意方式插 ...