[转帖]JDK8使用G1 垃圾回收器能解决大问题吗?
https://zhuanlan.zhihu.com/p/458098236
G1 垃圾回收器真的不行吗?
本文想突出两个问题:
- 解决问题的思路:从最原始的角度去思考,问题的本身是因为缓存数据导致的GC,那我们就应该去思考缓存数据是否合理,而不是去思考JVM的参数是否合理
- 学习G1的知识,其关键的概念,关键参数,已经相对CMS解决的两个问题:1.浮动垃圾 2.可预期的停顿时间
1. 背景
最近项目有两个问题
- 加了内存缓存,防止穿透到redis的missCache,导致大量的GC。
- 项目在每次发布的时候GC时间很长达到2s,导致大量的超时。
就针对这两个问题进行了分析和优化。
2. 问题分析
首先我们系统是内存32G,使用了大量的内存做为内存缓存数据。
结合业务和GC日志以及业务日志得出:
- 第一个启动的问题和第二个问题是一致的,都是因为内存缓存数据,导致每一次新来一个请求在redis查到数据后存入内存中去,导致存活对象在新生代不停的复制导致超时。
- 再者我们使用的是CMS垃回收器,新生代使用的是复制清除的垃圾回收机制,通过查看GC日志,每次存活的对象太多,以致于复制数据量很大。导致GC耗时和停顿时间较长,大概在200-300ms,又因为我们对外的借口客户端超时时间时200ms这就导致,我们服务不断出现超市请求。
- 继续从垃圾回收器的日志中得出垃圾回收的频率也高,大概13秒每次。
问题本质 :每次新生代存活对象太多
那既然已经看到问题的本质,那么我们应该怎么解决呢?
3. 解决方案
- 减小新生代的大小,让每次复制的对象小一点,但是会引发另一个问题GC的频率会提高,虽然停顿时间短了但是停顿的频率会飙高。
- 调整进入老年代的年龄,默认的15次,调整为6-7次。让提前进入老年代。
- 更换新的垃圾回收器,使用G1
- 优化业务逻辑,调整内存缓存key的时间。
这四个方案是有先后顺序的,这些方案提出顺序也意味着我当时在执行实验的顺序,可以看出这是一个糟糕的方案顺序,不记得谁说的了应该是鲁迅吧:“调参JVM是迫不得已的选择!”。
在实验过程中细节比较多就不细讲了,就着重讲一下升级为G1的方案,因为我这篇文章的主要目的是学习G1。
4. JDK8 升级G1
- G1在jdk6的时候是已经出现了,JDK 7 u9 或更高版本可以使用,在jdk9的时候成为默认的垃圾回收器。因为我们是jdk8所以是需要设置参数指定的。
-Xms24g -Xmx24g -XX:+UseG1GC -XX:MaxGCPauseMillis=95
//最大堆内存24G 使用G1GC,设置预期停顿时间是95ms
- 使用G1的主要原因是:G1的Stop The World(STW)更可控,G1在停顿时间上添加了预测机制,用户可以指定期望停顿时间。
目标很明确,可控的GC时间。 - 升级启用了G1后解惑不尽人意,甚至比CMS的结果还差,我们来看下G1,几个优于CMS的几个特点,以及实现。
5. G1学习和理解
5.1 G1的几个重要概念
- Region
- 传统的GC收集器将连续的内存空间划分为新生代、老年代和永久代(JDK 8去除了永久代,引入了元空间Metaspace),这种划分的特点是各代的存储地址(逻辑地址,下同)是连续的。如下图所示
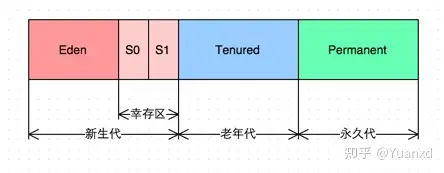
- 对于G1的各代存储地址是不连续的,每一代都使用了n个不连续大小的region,每个Region占有一块连续的虚拟内存地址
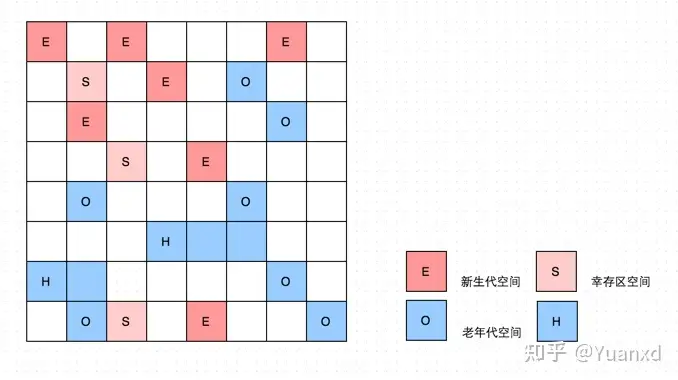
- 如上图,region区分为四种分别是Eden,sourivor,Old, 我们注意到还有一些Region标明了H,它代表Humongous,这表示这些Region存储的是巨大对象(humongous object,H-obj),即大小大于等于region一半的对象。H-obj有如下几个特征: H-obj直接分配到了old gen,防止了反复拷贝移动。 *H-obj在global concurrent marking阶段的cleanup 和 full GC阶段回收。 在分配H-obj之前先检查是否超过 initiating heap occupancy percent和the marking threshold, 如果超过的话,就启动global concurrent marking,为的是提早回收,防止 evacuation failures 和 full GC。
- SATB
- 全称是Snapshot-At-The-Beginning,由字面理解,是GC开始时活着的对象的一个快照。它是通过Root Tracing得到的,作用是维持并发GC的正确性。 那么它是怎么维持并发GC的正确性的呢?
- 根据三色标记算法,我们知道对象存在三种状态:
- 白:对象没有被标记到,标记阶段结束后,会被当做垃圾回收掉。
- 灰:对象被标记了,但是它的field还没有被标记或标记完。 *
- 黑:对象被标记了,且它的所有field也被标记完了。
- 对于第一个条件,在并发标记阶段,如果该白对象是new出来的,并没有被灰对象持有,那么它会不会被漏标呢?Region中有两个top-at-mark-start(TAMS)指针,分别为prevTAMS和nextTAMS。在TAMS以上的对象是新分配的,这是一种隐式的标记。对于在GC时已经存在的白对象,如果它是活着的,它必然会被另一个对象引用,即条件二中的灰对象。如果灰对象到白对象的直接引用或者间接引用被替换了,或者删除了,白对象就会被漏标,从而导致被回收掉,这是非常严重的错误,所以SATB破坏了第二个条件。也就是说,一个对象的引用被替换时,可以通过write barrier 将旧引用记录下来。
- SATB也是有副作用的,如果被替换的白对象就是要被收集的垃圾,这次的标记会让它躲过GC,这就是float garbage。因为SATB的做法精度比较低,所以造成的float garbage也会比较多。
- RSet(跨region的对象引用关系的处理)
- 全称是Remembered Set,是辅助GC过程的一种结构,典型的空间换时间工具,和Card Table有些类似。
- 还有一种数据结构也是辅助GC的:Collection Set(CSet),它记录了GC要收集的Region集合,集合里的Region可以是任意年代的。
- 在GC的时候,对于old->young和old->old的跨代对象引用,只要扫描对应的CSet中的RSet即可。 逻辑上说每个Region都有一个RSet,RSet记录了其他Region中的对象引用本Region中对象的关系,属于points-into结构(谁引用了我的对象)。而Card Table则是一种points-out(我引用了谁的对象)的结构,每个Card 覆盖一定范围的Heap(一般为512Bytes)。G1的RSet是在Card Table的基础上实现的:每个Region会记录下别的Region有指向自己的指针,并标记这些指针分别在哪些Card的范围内。 这个RSet其实是一个Hash Table,Key是别的Region的起始地址,Value是一个集合,里面的元素是Card Table的Index.
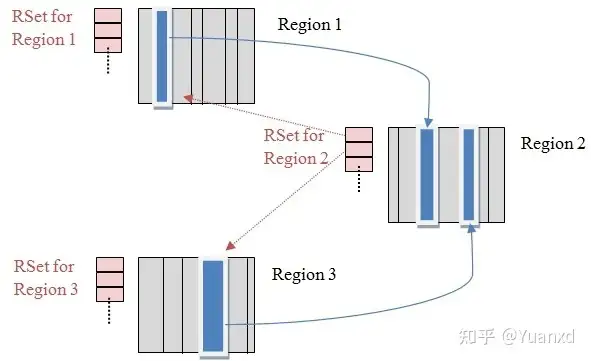
- 上图中有三个Region,每个Region被分成了多个Card,在不同Region中的Card会相互引用,Region1中的Card中的对象引用了Region2中的Card中的对象,蓝色实线表示的就是points-out的关系,而在Region2的RSet中,记录了Region1的Card,即红色虚线表示的关系,这就是points-into。 而维系RSet中的引用关系靠post-write barrier和Concurrent refinement threads来维护.类似于AOP切面的过程,在进行引用更换操作的时候需要进行修改。
- post-write barrier记录了跨Region的引用更新,更新日志缓冲区则记录了那些包含更新引用的Cards。一旦缓冲区满了,Post-write barrier就停止服务了,会由Concurrent refinement threads处理这些缓冲区日志。
- RSet究竟是怎么辅助GC的呢?在做YGC的时候,只需要选定young generation region的RSet作为根集,这些RSet记录了old->young的跨代引用,避免了扫描整个old generation。 而mixed gc的时候,old generation中记录了old->old的RSet,young->old的引用由扫描全部young generation region得到,这样也不用扫描全部old generation region。所以RSet的引入大大减少了GC的工作量。
- Pause Prediction Model
- Pause Prediction Model 即停顿预测模型。它在G1中的作用是: >G1 uses a pause prediction model to meet a user-defined pause time target and selects the number of regions to collect based on the specified pause time target.
- G1 GC是一个响应时间优先的GC算法,它与CMS最大的不同是,用户可以设定整个GC过程的期望停顿时间,参数-XX:MaxGCPauseMillis指定一个G1收集过程目标停顿时间,默认值200ms,不过它不是硬性条件,只是期望值。那么G1怎么满足用户的期望呢?就需要这个停顿预测模型了。G1根据这个模型统计计算出来的历史数据来预测本次收集需要选择的Region数量,从而尽量满足用户设定的目标停顿时间。
- 我们呢可以知道,根据设置停顿时间来决定回收内存的大小。
了解了这几个概念后我们来看,G1清理垃圾的过程是怎么进行的呢?
5.2 G1的垃圾回收过程
- G1提供了两种GC模式,Young GC和Mixed GC,两种都是完全Stop The World的。
- Young GC:选定所有年轻代里的Region。通过控制年轻代的region个数,即年轻代内存大小,来控制young GC的时间开销。
- Mixed GC:选定所有年轻代里的Region,外加根据global concurrent marking统计得出收集收益高的若干老年代Region。在用户指定的开销目标范围内尽可能选择收益高的老年代Region。(用户是上帝的原则)
- 由上面的描述可知,Mixed GC不是full GC(回收全量的老年代),它只能回收部分老年代的Region,如果mixed GC实在无法跟上程序分配内存的速度,导致老年代填满无法继续进行Mixed GC,就会使用serial old GC(full GC)来收集整个GC heap。所以我们可以知道,G1是不提供full GC的。
- global concurrent marking,它的执行过程类似CMS,但是不同的是,在G1 GC中,它主要是为Mixed GC提供标记服务的,并不是一次GC过程的一个必须环节。
- global concurrent marking的执行过程分为四个步骤:
- 初始标记(initial mark,STW)。它标记了从GC Root开始直接可达的对象。
- 并发标记(Concurrent Marking)。这个阶段从GC Root开始对heap中的对象标记,标记线程与应用程序线程并行执行,并且收集各个Region的存活对象信息。
- 最终标记(Remark,STW)。标记那些在并发标记阶段发生变化的对象,将被回收。
- 清除垃圾(Cleanup)。清除空Region(没有存活对象的),加入到free listMixed GC发生的时机:
- G1HeapWastePercent :在global concurrent marking结束之后,我们可以知道old gen regions中有多少空间要被回收,在每次YGC之后和再次发生Mixed GC之前,会检查垃圾占比是否达到此参数G1HeapWastePercent,只有达到了,下次才会发生Mixed GC。
- G1MixedGCLiveThresholdPercent:old generation region中的存活对象的占比,只有在此参数之下,才会被选入CSet。
- G1MixedGCCountTarget:一次global concurrent marking之后,最多执行Mixed GC的次数。
- G1OldCSetRegionThresholdPercent:一次Mixed GC中能被选入CSet的最多old generation region数量。
G1的常用参数配置:
7. G1的常用参数配置(垃圾编辑器表格都复制不了):
| 参数 | 含义 |
| :--------------------------------- | :----------------------------------------------------------- |
| -XX:G1HeapRegionSize=n | 设置Region大小,并非最终值 |
| -XX:MaxGCPauseMillis | 设置G1收集过程目标时间,默认值200ms,不是硬性条件 |
| -XX:G1NewSizePercent | 新生代最小值,默认值5% |
| -XX:G1MaxNewSizePercent | 新生代最大值,默认值60% |
| -XX:ParallelGCThreads | STW期间,并行GC线程数 |
| -XX:ConcGCThreads=n | 并发标记阶段,并行执行的线程数 |
| -XX:InitiatingHeapOccupancyPercent | 设置触发标记周期的 Java 堆占用率阈值。默认值是45%。这里的java堆占比指的是non_young_capacity_bytes,包括old+humongous |
总结
- 写了这么多,从遇到GC问题到问题解决(最后是通过最简单的方式,那就是内存缓存时间的设置合理),最后是使用最方便和最简单的方式解决的。我们一直是为了解决问题而解决最表面的问题。我们深知是因为是内存缓存而导致的问题,而没有从内存缓存的合理性上去思考,而是花费大量的时间和精力的去调优JVM。突然在这里想到musk讲的第一性原理。从最本质去解决问题。
- 本文想突出两个问题:
- 解决问题的思路:从最原始的角度去思考,问题的本身是因为缓存数据导致的GC,那我们就应该去思考缓存数据是否合理,而不是去思考JVM的参数是否合理
- 学习G1的知识,其关键的概念,关键参数,已经相对CMS解决的两个问题:1.浮动垃圾 2.可预期的停顿时间
参考
[转帖]JDK8使用G1 垃圾回收器能解决大问题吗?的更多相关文章
- G1垃圾回收器
垃圾回收器的发展历程 背景 01.G1解决的问题 G1垃圾回收器是04年正式提出,12开始正式支持,在17年作为JDK9默认的垃圾处理器. 在04年的时候,java程序堆的内存越来越大,从而导致程序中 ...
- 深入浅出具有划时代意义的G1垃圾回收器
G1诞生的背景 Garbage First(简称G1)收集器是垃圾收集器技术发展历史上的里程碑式的成果,它开创了收集器面向局部收集的设计思路和基于Region的内存布局形式.HotSpot开发团队最初 ...
- JVM学习——G1垃圾回收器(学习过程)
JVM学习--G1垃圾回收器 把这个跨时代的垃圾回收器的笔记独立出来. 新生代:适用复制算法 老年代:适用标记清除.标记整理算法 二娃本来看G1的时候觉得比较枯燥,但是后来总结完之后告诉我说,一定要慢 ...
- G1垃圾回收器在并发场景调优
一.序言 目前企业级主流使用的Java版本是8,垃圾回收器支持手动修改为G1,G1垃圾回收器是Java 11的默认设置,因此G1垃圾回收器可以用很长时间,现阶段垃圾回收器优化意味着针对G1垃圾回收器优 ...
- G1 垃圾回收器简单调优
G1: Garbage First 低延迟.服务侧分代垃圾回收器. 详细介绍参见:JVM之G1收集器,这里不再赘述. 关于调优目标:延迟.吞吐量 一.延迟,单次的延迟 单次的延迟关系到服务的响应时延, ...
- 探索G1垃圾回收器
前言 最近王子因为个人原因有些忙碌,导致文章更新比较慢,希望大家理解,之后也会持续和小伙伴们一起共同分享技术干货. 上篇JVM的文章中我们对ParNew和CMS垃圾回收器已经有了一个比较透彻的认识,感 ...
- JAVA之G1垃圾回收器
概述 G1 GC,全称Garbage-First Garbage Collector,通过-XX:+UseG1GC参数来启用,作为体验版随着JDK 6u14版本面世,在JDK 7u4版本发行时被正式推 ...
- jvm默认的并行垃圾回收器和G1垃圾回收器性能对比
http://www.importnew.com/13827.html 参数如下: JAVA_OPTS="-server -Xms1024m -Xmx1024m -Xss256k -XX:M ...
- G1垃圾回收器参数配置
下面是完整的 G1 的 GC 开关参数列表. 选项/默认值 说明 -XX:+UseG1GC 使用 G1 (Garbage First) 垃圾收集器 -XX:MaxGCPauseMillis=n 设置最 ...
- JVM七大垃圾回收器下篇G1(Garbage First)
G1回收器:区域化分代式 既然我们已经有了前面几个强大的GC,为什么还要发布Garbage First (G1)GC? 原因就在于应用程序所应对的业务越来越庞大.复杂,用户越来越多,没有GC就不能保 ...
随机推荐
- 神经网络优化篇:详解梯度检验(Gradient checking)
梯度检验 梯度检验帮节省了很多时间,也多次帮发现backprop实施过程中的bug,接下来,看看如何利用它来调试或检验backprop的实施是否正确. 假设的网络中含有下列参数,\(W^{[1]}\) ...
- 玩转Python:用Python处理文本数据,附代码
Python 提供了多种库来处理纯文本数据,这些库可以应对从基本文本操作到复杂文本分析的各种需求.以下是一些常用的纯文本处理相关的库: str 类型: Python 内建的字符串类型提供了许多简便的方 ...
- ajax与thymeleaf分别实现数据传输
小杰笔记篇: 1:第一种:利用Model和thymeleaf引擎来完成: Controller层: @CrossOrigin//解决跨域问题 @Controller public class User ...
- POJ 3003 DP 寻路 记录路径
POJ 3003 DP 寻路 记录路径 我一开始把M看成是每个a_i的上限了,这是致命的,因为这个题dfs暴力搜索+剪枝是过不了的因为M<=40,全部状态有2的四十次幂. 正解是DP,设dp[i ...
- LeetCode DFS、BFS篇(102、200、111、752)
102. 二叉树的层序遍历 给你一个二叉树,请你返回其按 层序遍历 得到的节点值. (即逐层地,从左到右访问所有节点). 示例: 二叉树:[3,9,20,null,null,15,7], 3 / 9 ...
- 智能对联模型太难完成?华为云ModelArts助你实现!手把手教学
摘要:农历新年将至,听说华为云 AI 又将开启智能对对联迎接牛气冲天,让我们拭目以待!作为资深 Copy 攻城狮,想要自己实现一个对对联的模型,是不能可能完成的任务,因此我搜罗了不少前人的实践案例,今 ...
- 华为云MVP程云:知识化转型,最终要赋能一线
摘要:如今的智能语音助手,可以帮助我们完成日常生活中的一些常规动作.同样,在企业中,智能问答机器人也在扮演着同样的角色. 本文分享自华为云社区<[亿码当先,云聚金陵]华为云MVP程云:知识化转型 ...
- Docker 安装 kafka
简单安装为了集成 SpringBoot,真实使用,增加增加更多配置,比如将log映射出来 1.安装 zookeeper [root@centos-linux ~]# docker pull wurst ...
- Web 目录文件浏览配置
IIS 配置目录浏览 在目录下 Web.config 下添加一句: <directoryBrowse enabled="true"/> <?xml version ...
- SpringBoot Docker Skywalking agent 不生效
SpringBoot Skywalking agent 通过 Dockfile 配置 不生效 ENTRYPOINT ["java","-Djava.security.eg ...