用Python制作新浪微博爬虫
早上刷空间发现最近好多人过生日诶~
仔细想想,好像4月份的时候也是特别多人过生日【比如我
那么每个人生日的月份有什么分布规律呢。。。突然想写个小程序统计一下
最简单易得的生日数据库大概就是新浪微博了:
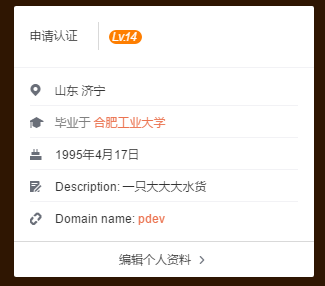
但是电脑版的新浪微博显然是动态网页。。。如果想爬这个应该要解析JS脚本【就像上次爬网易云音乐。。然而并不会解
其实有更高效的方法:爬移动版
移动版因为手机浏览器的限制大多都做了简化,更有利于爬虫
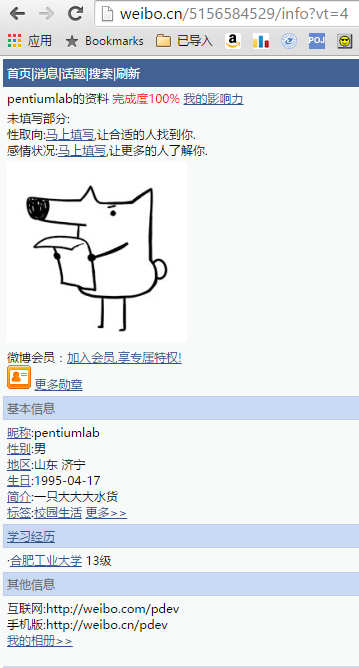
注意上面的网址:http://weibo.cn/5156584529/info
经测试不同的用户仅仅是中间的数字不同,那么只要枚举数字就可以实现爬虫了~
但是移动版微博想查看用户资料是必须要登录的。所以我们要先模拟登录,获取cookie,再访问url,获取用户资料。
许多网站的登录都用到了cookie,大体过程如下:
用户输入用户名密码,浏览器将这些组成一个form(表单)提交给服务器,若服务器判断用户名密码正确则会返回一个cookie,然后浏览器会记录下这个cookie。之后用本地的cookie再访问就不用登录了。
模拟登录:
打开微博移动版主页http://weibo.cn,点击登录,得到登录地址:
http://login.weibo.cn/login/?ns=1&revalid=2&backURL=http%3A%2F%2Fweibo.cn%2F&backTitle=%CE%A2%B2%A9&vt=
【这界面真的好丑。。。
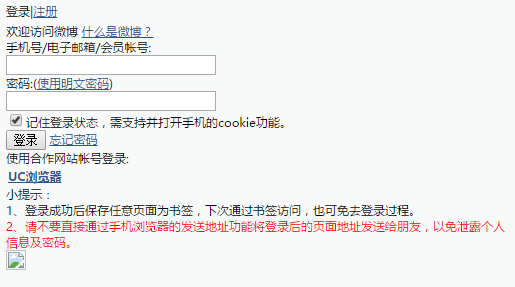
输入用户名密码登录,用chrome抓包,查看表单:
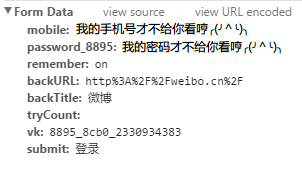
其实我们只需要表单就够了。
用Python中的urllib2,使用表单数据访问登录页,获取cookie,再用cookie访问用户页即可。
但是还要注意一个问题:新浪微博作了反爬虫处理,因此会遇到这个错误:
urllib2.HTTPError: HTTP Error 403: Forbidden
所以还要加上一个头信息headers来冒充浏览器
code:
__author__ = 'IBM'
import urllib2
import urllib
import cookielib
headers = {'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie)) #uurl='http://weibo.cn/5156582529/info'
wurl='http://login.weibo.cn/login/?backURL=&backTitle=&vt=4&revalid=2&ns=1' logindata=urllib.urlencode(
{
'mobile':'不许偷看我手机号!',
'password_8199':'不许偷看我密码!',
'remember':'on',
'backURL':'http%253A%252F%252Fweibo.cn%252F',
'backTitle':'%E5%BE%AE%E5%8D%9A',
'tryCount':'',
'vk':'8199_4012_2261332562',
'submit':'%E7%99%BB%E5%BD%95'
}
) loginreq=urllib2.Request(
url=wurl,
data=logindata,
headers=headers
) loginres=opener.open(loginreq)
print loginres.read() html=opener.open(urllib2.Request(url='http://weibo.cn/5156584529/info',headers=headers))
dat=html.read()
print dat
输出的dat就是用户资料页的HTML。随便想要什么信息都可以去里面找啦~
【但是目前还有个问题没解决:注意表单里红色underline的那两段:
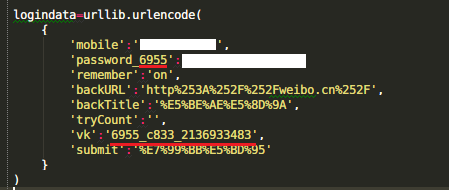
经测试这两个数字每次登录的时候都是不一样的。。而且同一个数字有效期是一定的,也就是说过一会儿这段代码可能就登录不了了。。。
个人猜测这可能是为了反爬虫吧。。。
under construction
Ref:
http://blog.csdn.net/pleasecallmewhy/article/details/9305229
http://www.douban.com/note/131370224/
用Python制作新浪微博爬虫的更多相关文章
- 利用python实现新浪微博爬虫
第一个模块,模拟登陆sina微博,创建weiboLogin.py文件,输入以下代码: #! /usr/bin/env python # -*- coding: utf-8 -*- import sys ...
- Windows 环境下运用Python制作网络爬虫
import webbrowser as web import time import os i = 0 MAXNUM = 1 while i <= MAXNUM: web.open_new_t ...
- dota玩家与英雄契合度的计算器,python语言scrapy爬虫的使用
首发:个人博客,更新&纠错&回复 演示地址在这里,代码在这里. 一个dota玩家与英雄契合度的计算器(查看效果),包括两部分代码: 1.python的scrapy爬虫,总体思路是pag ...
- 利用aiohttp制作异步爬虫
asyncio可以实现单线程并发IO操作,是Python中常用的异步处理模块.关于asyncio模块的介绍,笔者会在后续的文章中加以介绍,本文将会讲述一个基于asyncio实现的HTTP框架--a ...
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- Python 开发轻量级爬虫07
Python 开发轻量级爬虫 (imooc总结07--网页解析器BeautifulSoup) BeautifulSoup下载和安装 使用pip install 安装:在命令行cmd之后输入,pip i ...
- Python 开发轻量级爬虫06
Python 开发轻量级爬虫 (imooc总结06--网页解析器) 介绍网页解析器 将互联网的网页获取到本地以后,我们需要对它们进行解析才能够提取出我们需要的内容. 也就是说网页解析器是从网页中提取有 ...
- Python 开发轻量级爬虫05
Python 开发轻量级爬虫 (imooc总结05--网页下载器) 介绍网页下载器 网页下载器是将互联网上url对应的网页下载到本地的工具.因为将网页下载到本地才能进行后续的分析处理,可以说网页下载器 ...
- Python 开发轻量级爬虫04
Python 开发轻量级爬虫 (imooc总结04--url管理器) 介绍抓取URL管理器 url管理器用来管理待抓取url集合和已抓取url集合. 这里有一个问题,遇到一个url,我们就抓取它的内容 ...
随机推荐
- 适配ios10(iTunes找不到构建版本)
前两天上架App遇到一个比较神奇的问题,打包好的项目使用Application Loader上传成功,但是在iTunes里面却找不到构建版本,App的活动页面也没有相应的版本. 之前了解IOS10对用 ...
- HashSet 浅析示例
* 1.继承自抽象类 AbstractSet,实现接口 Set.Cloneable.Serializable: * 2.元素无顺序: * 3.元素不可重复: * 4.采用哈希算法插入数据,插入速度快: ...
- C++的单例模式与线程安全单例模式(懒汉/饿汉)
1 教科书里的单例模式 我们都很清楚一个简单的单例模式该怎样去实现:构造函数声明为private或protect防止被外部函数实例化,内部保存一个private static的类指针保存唯一的实例,实 ...
- Linux忘记root密码怎么办?
开篇前言:Linux系统的root账号是非常重要的一个账号,也是权限最大的一个账号,但是有时候忘了root密码怎么办?总不能重装系统吧,这个是下下策,其实Linux系统中,如果忘记了root账号密码, ...
- Linux服务器宕机案例一则
案例环境 操作系统 :Oracle Linux Server release 5.7 64bit 虚拟机 硬件配置 : 物理机型号为DELL R720 资源配置 :RAM 8G Intel(R) Xe ...
- SQL SERVER 2000通过链接服务器发送邮件出现错误
案例环境: 服务器A系统: Windows Server 2000 数据库版本 : Microsoft SQL Server 2000 - 8.00.2282 (Intel X86) 服务器B系统: ...
- Vim自动补全神器–YouCompleteMe
一.简介 YouCompleteMe是Vim的自动补全插件,与同类插件相比,具有如下优势 1.基于语义补全 2.整合实现了多种插件 clang_complete.AutoComplPop .Super ...
- Java 多态
多态通过分离做什么和怎么做,从另一个角度将接口和实现分离开来. 继承允许将对象视为它自己本身的类型活基类型来加以处理. 方法调用绑定 绑定: 将一个方法调用同一个方法主体关联起来. 前期绑定:在程序执 ...
- 机器学习库shark安装
经过两天的折腾,一个对c++和机器学习库的安装都一知半解的人终于在反复安装中,成功的将shark库安装好了,小小纪念一下,多亏了卡门的热心帮忙. shark的安装主要分为以下几个部分: (1)下载 s ...
- sicily vector有序插入
实现了简单的vector有序插入,这个题目值得注意的点是1.当vector为空时,需要判断再排除 2.迭代器的使用是此段代码的特点 int insertVector(vector<int> ...