用Python制作新浪微博爬虫
早上刷空间发现最近好多人过生日诶~
仔细想想,好像4月份的时候也是特别多人过生日【比如我
那么每个人生日的月份有什么分布规律呢。。。突然想写个小程序统计一下
最简单易得的生日数据库大概就是新浪微博了:
但是电脑版的新浪微博显然是动态网页。。。如果想爬这个应该要解析JS脚本【就像上次爬网易云音乐。。然而并不会解
其实有更高效的方法:爬移动版
移动版因为手机浏览器的限制大多都做了简化,更有利于爬虫
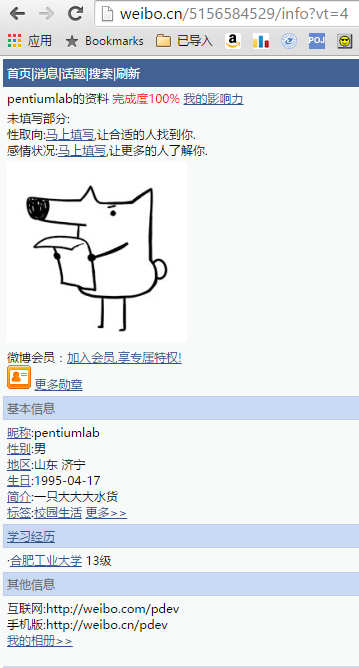
注意上面的网址:http://weibo.cn/5156584529/info
经测试不同的用户仅仅是中间的数字不同,那么只要枚举数字就可以实现爬虫了~
但是移动版微博想查看用户资料是必须要登录的。所以我们要先模拟登录,获取cookie,再访问url,获取用户资料。
许多网站的登录都用到了cookie,大体过程如下:
用户输入用户名密码,浏览器将这些组成一个form(表单)提交给服务器,若服务器判断用户名密码正确则会返回一个cookie,然后浏览器会记录下这个cookie。之后用本地的cookie再访问就不用登录了。
模拟登录:
打开微博移动版主页http://weibo.cn,点击登录,得到登录地址:
http://login.weibo.cn/login/?ns=1&revalid=2&backURL=http%3A%2F%2Fweibo.cn%2F&backTitle=%CE%A2%B2%A9&vt=
【这界面真的好丑。。。
输入用户名密码登录,用chrome抓包,查看表单:
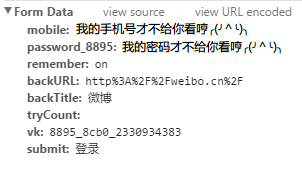
其实我们只需要表单就够了。
用Python中的urllib2,使用表单数据访问登录页,获取cookie,再用cookie访问用户页即可。
但是还要注意一个问题:新浪微博作了反爬虫处理,因此会遇到这个错误:
urllib2.HTTPError: HTTP Error 403: Forbidden
所以还要加上一个头信息headers来冒充浏览器
code:
__author__ = 'IBM'
import urllib2
import urllib
import cookielib
headers = {'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie)) #uurl='http://weibo.cn/5156582529/info'
wurl='http://login.weibo.cn/login/?backURL=&backTitle=&vt=4&revalid=2&ns=1' logindata=urllib.urlencode(
{
'mobile':'不许偷看我手机号!',
'password_8199':'不许偷看我密码!',
'remember':'on',
'backURL':'http%253A%252F%252Fweibo.cn%252F',
'backTitle':'%E5%BE%AE%E5%8D%9A',
'tryCount':'',
'vk':'8199_4012_2261332562',
'submit':'%E7%99%BB%E5%BD%95'
}
) loginreq=urllib2.Request(
url=wurl,
data=logindata,
headers=headers
) loginres=opener.open(loginreq)
print loginres.read() html=opener.open(urllib2.Request(url='http://weibo.cn/5156584529/info',headers=headers))
dat=html.read()
print dat
输出的dat就是用户资料页的HTML。随便想要什么信息都可以去里面找啦~
【但是目前还有个问题没解决:注意表单里红色underline的那两段:
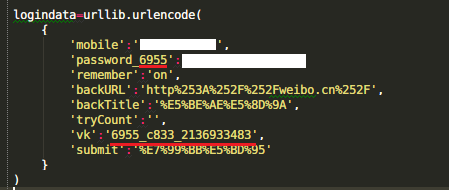
经测试这两个数字每次登录的时候都是不一样的。。而且同一个数字有效期是一定的,也就是说过一会儿这段代码可能就登录不了了。。。
个人猜测这可能是为了反爬虫吧。。。
under construction
Ref:
http://blog.csdn.net/pleasecallmewhy/article/details/9305229
http://www.douban.com/note/131370224/
用Python制作新浪微博爬虫的更多相关文章
- 利用python实现新浪微博爬虫
第一个模块,模拟登陆sina微博,创建weiboLogin.py文件,输入以下代码: #! /usr/bin/env python # -*- coding: utf-8 -*- import sys ...
- Windows 环境下运用Python制作网络爬虫
import webbrowser as web import time import os i = 0 MAXNUM = 1 while i <= MAXNUM: web.open_new_t ...
- dota玩家与英雄契合度的计算器,python语言scrapy爬虫的使用
首发:个人博客,更新&纠错&回复 演示地址在这里,代码在这里. 一个dota玩家与英雄契合度的计算器(查看效果),包括两部分代码: 1.python的scrapy爬虫,总体思路是pag ...
- 利用aiohttp制作异步爬虫
asyncio可以实现单线程并发IO操作,是Python中常用的异步处理模块.关于asyncio模块的介绍,笔者会在后续的文章中加以介绍,本文将会讲述一个基于asyncio实现的HTTP框架--a ...
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- Python 开发轻量级爬虫07
Python 开发轻量级爬虫 (imooc总结07--网页解析器BeautifulSoup) BeautifulSoup下载和安装 使用pip install 安装:在命令行cmd之后输入,pip i ...
- Python 开发轻量级爬虫06
Python 开发轻量级爬虫 (imooc总结06--网页解析器) 介绍网页解析器 将互联网的网页获取到本地以后,我们需要对它们进行解析才能够提取出我们需要的内容. 也就是说网页解析器是从网页中提取有 ...
- Python 开发轻量级爬虫05
Python 开发轻量级爬虫 (imooc总结05--网页下载器) 介绍网页下载器 网页下载器是将互联网上url对应的网页下载到本地的工具.因为将网页下载到本地才能进行后续的分析处理,可以说网页下载器 ...
- Python 开发轻量级爬虫04
Python 开发轻量级爬虫 (imooc总结04--url管理器) 介绍抓取URL管理器 url管理器用来管理待抓取url集合和已抓取url集合. 这里有一个问题,遇到一个url,我们就抓取它的内容 ...
随机推荐
- 显示转换explicit和隐式转换implicit
用户自定义的显示转换和隐式转换 显式转换implicit关键字告诉编译器,在源代码中不必做显示的转型就可以产生调用转换操作符方法的代码. 隐式转换implicit关键字告诉编译器只有当源代码中指定了显 ...
- Linq专题之提高编码效率—— 第三篇 你需要知道的枚举类
众所周知,如果一个类可以被枚举,那么这个类必须要实现IEnumerable接口,而恰恰我们所有的linq都是一个继承自IEnumerable接口的匿名类, 那么问题就来了,IEnumerable使了 ...
- 聊下 git rebase -i
在使用git作为源代码管理工具的时候,开发的时经常会面临一个常见的问题,多个commit 需要合并为一个完整的commit提交. 在一个基本的迭代周期里,你会有很多次commit,有跟配置文件相关的, ...
- Pause/Resume Instance 操作详解 - 每天5分钟玩转 OpenStack(34)
本节通过日志详细分析 Nova Pause/Resume 操作. 有时需要短时间暂停 instance,可以通过 Pause 操作将 instance 的状态保存到宿主机的内存中.当需要恢复的时候,执 ...
- VI常用的命令
vi filename : 打开或者新建一个文件夹,并将光标置于第一行首位 I : 表示光标在当前位置编辑文本 A : 表示光标进入下以恶字符位置编辑文件 X : 每按一次删除光标所在位置的前面一个字 ...
- Redis-cli命令最新总结
资料来源: http://redisdoc.com/ http://redis.io/commands 连接操作相关的命令 默认直接连接 远程连接-h 192.168.1.20 -p 6379 pi ...
- [WPF系列]-高级部分 需要区分的东东
ContentControl VS ContentPresenter What's the difference between ContentControl and ContentPresenter ...
- 帆软报表FineReport SQLServer数据库连接失败常见解决方案
1. 问题描述 帆软报表FineReport客户端连接SQLServer(2000.2005等),常常会出现如下错误:com.microsoft.sqlserver.jdbc.SQLServerExc ...
- 【JavaScript Demo】回到顶部功能实现
随着网站的不断发展,需要展示的内容也越来越丰富,这导致网页上能展示的内容越来越多.当内容堆积影响了用户体验,就需考虑如何提升用户体验.在这一系列的改动中,“回到顶部”的功能成为了一个经典. 1.页面布 ...
- POJ1201 Intervals[差分约束系统]
Intervals Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 26028 Accepted: 9952 Descri ...