Java 集合(一)List
在 Java 中,主要存在以下三种类型的集合:Set、List 和 Map,按照更加粗略的划分,可以分为:Collection 和 Map,这些类型的继承关系如下图所示:
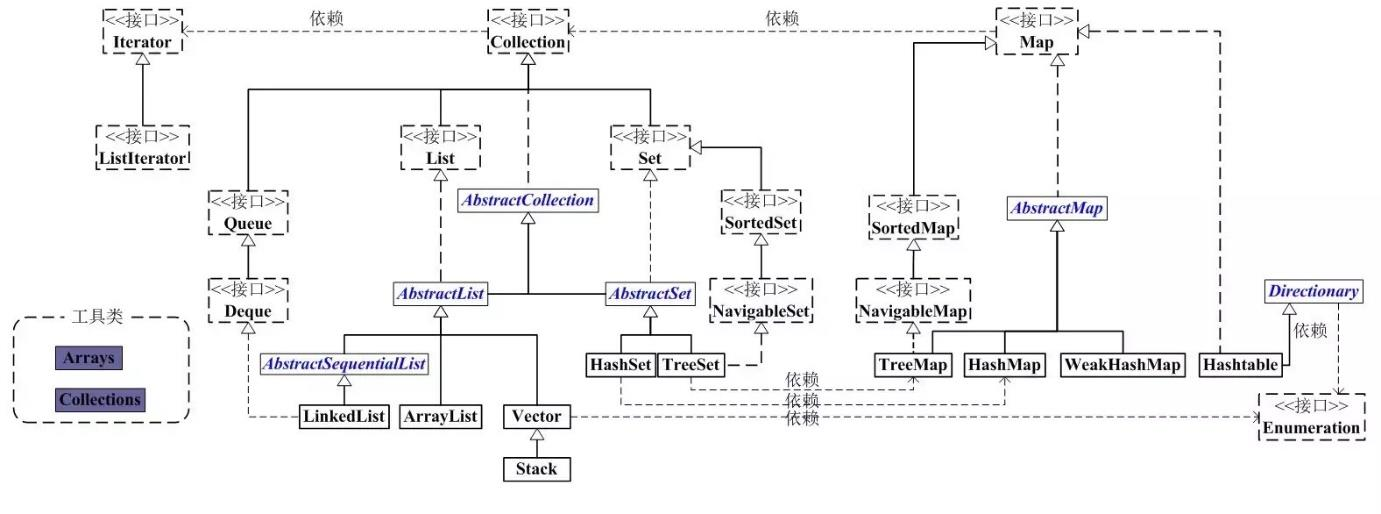
Collection是集合 List、Set、Queue 等最基本的接口Iterator即迭代器,可以通过迭代器遍历集合中的数据Map是映射关系的基本接口
本文将主要介绍有关 List 集合的相关内容,ArrayList 和 LinkedList 是在实际使用中最常使用的两种 List,因此主要介绍这两种类型的 List
本文的 JDK 版本为 JDK 17
ArrayList
具体的使用可以参考 List 接口的相关文档,在此不做过多的介绍
初始化
ArrayList 存在三个构造函数,用于初始化 ArrayList
ArrayList()对应的源代码如下所示:
// 默认的空元素列表
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; // 实际存储元素的数组
transient Object[] elementData; public ArrayList() {
// 调用次无参构造函数时,首先将元素列表指向空的列表,在之后的扩容操作中再进行进一步的替换
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
ArrayList(int)对应的源代码如下所示:
private static final Object[] EMPTY_ELEMENTDATA = {}; public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
ArrayList(Collection<? extend E>)对应的源代码:
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
/*
如果添加的集合和 ArrayList 相同,那么直接修改当前的数据列表的引用
因此在某些情况下对于该数组的修改会出现一些奇怪的问题,
因为对于当前数组元素的修改也会导致原数组元素的改变
*/
elementData = a;
} else {
/*
想比较之下,复制一个数组会更加安全,缺点在于执行速度不是那么的好
*/
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// 如果集合中元素的个数为 0,那么替换为空数组
elementData = EMPTY_ELEMENTDATA;
}
}
添加元素
添加元素是比较重要的部分,特别是 ArrayList 的自动扩容机制
在 ArrayList 中存在以下三个重载函数:
add(E, Object[], int)add(E)add(int, E)
一般情况下,都会调用 add(E) 的重载方法完成添加元素的功能,具体的源代码如下所示:
public boolean add(E e) {
modCount++; // 记录当前的数组的修改次数,适用于并发环境下的检测
add(e, elementData, size);
return true;
}
添加时调用重载函数 add(E, Object[], int),对应的源代码如下所示:
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow(); // 比较关键的地方在这,在这里完成自动扩容
elementData[s] = e;
size = s + 1;
}
而 add(int, E) 的目的是向数组中指定的位置插入对应的元素,对应的源代码如下所示:
public void add(int index, E element) {
rangeCheckForAdd(index); // 首先,检查插入的索引位置是否合法
modCount++; // 记录当前的修改次数
final int s;
Object[] elementData;
if ((s = size) == (elementData = this.elementData).length)
elementData = grow(); // 此时的数组长度不够,需要进行扩容
// 将扩容后(已经复制了原有数组的数据)的数组按照指定的 index 分开复制到原有数组中
System.arraycopy(elementData, index,
elementData, index + 1,
s - index);
// 修改 index 位置的数组元素
elementData[index] = element;
size = s + 1;
}
扩容
grow() 扩容的实现的源代码如下所示:
private Object[] grow() {
return grow(size + 1);
}
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { // 判断当前爱你的数组元素是否被修改过
// 首先,计算扩容后的数组的大小
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, // 最少需要增长的空间
oldCapacity >> 1 /* 每次增大的默认空间大小 ,为 0.5 倍的旧空间大小*/ );
// 然后将创建原有的数据元素数组的副本对象,再将数据填入到副本数组中,完成扩容操作
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
/*
由于没有被修改过,那么直接扩容到目标大小即可,
DEFAULT_CAPACITY=10,这是为了提供一个最小的初始容量,以免扩容机制过于频繁造成的性能损失
*/
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
扩容时关键的是在于新的容量的计算,具体的源代码如下所示:
// jdk.internal.util.ArraysSupport
public static int newLength(int oldLength, int minGrowth, int prefGrowth) {
/*
参照上文中 grow 中传入的参数,最小大小扩容到原来数组大小的 1.5 倍,
如果 minGrwoth 大于 oldCapacity,则以 minGrowth 为准
*/
int prefLength = oldLength + Math.max(minGrowth, prefGrowth);
// 加法操作可能会导致整形变量溢出
if (0 < prefLength && prefLength <= SOFT_MAX_ARRAY_LENGTH) {
return prefLength;
} else {
// 如果溢出的话则调用 hugeLength 进行计算
return hugeLength(oldLength, minGrowth);
}
}
/*
之所以最大值为 Integer.MAX_VALUE - 8 是由于有些 JVM 的实现会限制其不会达到 Integer.MAX_VALUE
*/
public static final int SOFT_MAX_ARRAY_LENGTH = Integer.MAX_VALUE - 8;
private static int hugeLength(int oldLength, int minGrowth) {
int minLength = oldLength + minGrowth;
if (minLength < 0) { // 这里溢出的说明确实是没有足够的空间可以进行分配了
throw new OutOfMemoryError(
"Required array length " + oldLength + " + " + minGrowth + " is too large");
} else if (minLength <= SOFT_MAX_ARRAY_LENGTH) { // 小于最大限制,直接使用即可
return SOFT_MAX_ARRAY_LENGTH;
} else {
// 这种情况说明在 SOFT_MAX_ARRAY_LENGTH — Integer.MAX_VALUE 之间,依旧是一个有效的 int 值
return minLength;
}
}
扩容完成之后,将元素直接放入到末尾位置,完成元素的插入
移除元素
在 ArrayList 中移除元素也存在两个重载函数:
remove(int):移除指定位置的元素remove(Object):移除列表中的指定元素(依据 Object 的equals方法)
remove(int) 方法对应的源代码如下所示:
public E remove(int index) {
Objects.checkIndex(index, size); // 检查删除的索引位置是否是有效的
final Object[] es = elementData;
// 获取这个索引位置的旧有元素
@SuppressWarnings("unchecked") E oldValue = (E) es[index];
fastRemove(es, index); // 移除该索引位置的元素
return oldValue;
}
比较关键的 fastRemove 方法对应的源代码如下所示:
private void fastRemove(Object[] es, int i) {
modCount++;
final int newSize;
// 直接调用 native 方法将 index 后的元素向前移动一个位置
if ((newSize = size - 1) > i)
System.arraycopy(es, i + 1, es, i, newSize - i);
// 最后一个位置现在已经是无效的,设置为 null 帮助 gc
es[size = newSize] = null;
}
remove(Object) 对应的源代码如下所示:
public boolean remove(Object o) {
final Object[] es = elementData;
final int size = this.size;
int i = 0;
/*
这一步的目的是找到对应的元素位置的索引
可以看到,在找到第一个元素后就不会继续向后找了,
因此使用该方法是需要注意这一点
*/
found: {
if (o == null) {
for (; i < size; i++)
if (es[i] == null)
break found;
} else {
for (; i < size; i++)
if (o.equals(es[i]))
break found;
}
return false;
}
// 同 remove(int) 的移除元素一致
fastRemove(es, i);
return true;
}
值得注意的是,在实际使用的过程中,由于 Java “自动装箱/拆箱” 机制的存在,如果此时恰好列表的元素类型为 Integer,那么在调用 remove 方法时将会自动完成拆箱调用 remove(int) 重载方法。可以显示地通过传入 Integer 对象来避免自动拆箱错误地调用 remove(int),如 list.remove(Integer.valueOf(1)) 就会正确地调用 remove(object ) 方法
收缩列表
由于扩容机制的存在,因此出现列表很长,但是数据元素不多的情况是可能的。ArrayList 并不会自动调用收缩列表的方法来收缩列表的长度,但是我们自己可以显示地通过调用 trimToSize 方法来收缩列表。
trimToSize 对应的源代码如下所示:
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
LinkedList
除了 ArrayList 之外,对于 List 接口的实现类,LinkedList 可能是使用得比较多的实现类。和 ArrayList 的实现不同,LinkedList 的底层数据结构是双向链表,具体的节点的定义如下所示:
private static class Node<E> {
E item; // 实际数据元素
Node<E> next; // 后继节点指针
Node<E> prev; // 前驱节点指针
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
添加元素
同样德,从 List 接口过来的两个重载方法:
add(E):添加一个元素到列表的末尾add(int, E):添加一个元素到指定的索引位置
其中, add(E) 对应的源代码如下所示:
public boolean add(E e) {
linkLast(e);
return true;
}
// 链接元素到链表的末尾
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
这个就是简单的双向链表的插入操作,不做过多的介绍。
add(int, E) 对应的源代码如下所示:
public void add(int index, E element) {
checkPositionIndex(index); // 首先,检查插入的索引位置是否合法
// 如果插入的位置就是在末尾,那么直接链接到末尾即可
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
比较关键的是确定插入位置的元素节点,即 node(index) 方法的实现,对应的源代码如下所示:
Node<E> node(int index) {
// 如果索引小于列表长度的一般,则从头开始查找位置节点
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// 否则,从尾部节点开始,向前查找到对应的位置节点
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
最后,将对应的元素插入到找到的元素节点之前即可完成该项操作
移除元素
依旧是从 List 接口带过来的重载方法:
remove(int):移除指定位置的元素remove(Object):移除第一个出现的指定元素
remove(int) 对应的源代码如下所示:
public E remove(int index) {
checkElementIndex(index); // 检查索引位置是否合法
/*
首先通过 node(index) 方法找到对应的索引位置的节点,
然后移除它的链接即可(注意头节点和尾节点的变化)
*/
return unlink(node(index));
}
E unlink(Node<E> x) {
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
// 移除前驱节点,注意前驱节点为 null 的情况
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
// 移除后继节点,注意后继节点为 null 的情况
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null; // 设置为 null 方便 gc
size--;
modCount++;
return element;
}
remove(Object) 对应的源代码如下所示:
public boolean remove(Object o) {
/*
简单来讲就是遍历整个链表,找到要移除的元素,
然后取消它在链表中的链接即可
unlink 方法在上文有所介绍
*/
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
两者的比较
在实际使用中,ArrayList 的使用次数要比 LinkedList 的次数要高。这是由于使用 List 更加倾向于保存数据,然后获取数据的情况要多一些。
其实,在教科书上会提及链表和数组的比较,诸如:链表使用了额外的空间来维护节点的前后指针、插入和删除都在常数的时间复杂度内完成。但是实际上,这两者的操作性能不会有太大的区别,甚至可能 LinkedList 的插入操作的性能还不及 ArrayList(因为要找到插入的位置节点);同样的,ArrayList 对于空间的利用率在某些情况下可能还没有 LinkedList 高,这是由于扩容时默认会扩容到原来的 1.5 倍,有时那 0.5 倍的额外空间是完全没有被使用的。
按照本人的使用情况,一般在选取 List 的实现时会采用 ArrayList 作为具体的实现类,因为 ArrayList 在转换为数组的这个过程会比 LinkedList 更加便捷。而 LinkedList 不仅仅实现了 List 接口,而且还实现了 Queue、Deque 等其它的接口,因此 LinkedList 一般会作为这些接口的默认实现类来使用
Java 集合(一)List的更多相关文章
- Java集合专题总结(1):HashMap 和 HashTable 源码学习和面试总结
2017年的秋招彻底结束了,感觉Java上面的最常见的集合相关的问题就是hash--系列和一些常用并发集合和队列,堆等结合算法一起考察,不完全统计,本人经历:先后百度.唯品会.58同城.新浪微博.趣分 ...
- Scala集合和Java集合对应转换关系
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 用Scala编码的时候,经常会遇到scala集合和Java集合互相转换的case,特意mark一 ...
- java集合你了解多少?
用了java集合这么久,还没有系统的研究过java的集合结构,今天亲自画了下类图,总算有所收获. 一.所有集合都实现了Iterable接口. Iterable接口中包含一个抽象方法:Iterator& ...
- 深入java集合学习1-集合框架浅析
前言 集合是一种数据结构,在编程中是非常重要的.好的程序就是好的数据结构+好的算法.java中为我们实现了曾经在大学学过的数据结构与算法中提到的一些数据结构.如顺序表,链表,栈和堆等.Java 集合框 ...
- Java集合框架List,Map,Set等全面介绍
Java集合框架的基本接口/类层次结构: java.util.Collection [I]+--java.util.List [I] +--java.util.ArrayList [C] +- ...
- Java集合框架练习-计算表达式的值
最近在看<算法>这本书,正好看到一个计算表达式的问题,于是就打算写一下,也正好熟悉一下Java集合框架的使用,大致测试了一下,没啥问题. import java.util.*; /* * ...
- 【集合框架】Java集合框架综述
一.前言 现笔者打算做关于Java集合框架的教程,具体是打算分析Java源码,因为平时在写程序的过程中用Java集合特别频繁,但是对于里面一些具体的原理还没有进行很好的梳理,所以拟从源码的角度去熟悉梳 ...
- Java 集合框架
Java集合框架大致可以分为五个部分:List列表,Set集合.Map映射.迭代器.工具类 List 接口通常表示一个列表(数组.队列.链表 栈),其中的元素 可以重复 的是:ArrayList 和L ...
- Java集合概述
容器,是用来装东西的,在Java里,东西就是对象,而装对象并不是把真正的对象放进去,而是指保存对象的引用.要注意对象的引用和对象的关系,下面的例子说明了对象和对象引用的关系. String str = ...
- 深入java集合系列文章
搞懂java的相关集合实现原理,对技术上有很大的提高,网上有一系列文章对java中的集合做了深入的分析, 先转载记录下 深入Java集合学习系列 Java 集合系列目录(Category) HashM ...
随机推荐
- 一个关于 i++ 和 ++i 的面试题打趴了所有人
前言 都说大城市现在不好找工作,可小城市却也不好招人. 我们公司招了挺久都没招到,主管感到有些心累. 我提了点建议,是不是面试问的太深了,在这种小城市,能干活就行. 他说自己问的面试题都很浅显,如果答 ...
- 点云配准算法-旋转矩阵估计-Kabsch-Umeyama algorithm
Kabsch-Umeyama algorithm 参考文献: https://www.wikiwand.com/en/Kabsch_algorithm 面向点云配准,最小化两点集均方根误差(RMSD, ...
- Linux常用命令大全 Linux Commands Line - v1.0
The most complete and updated list of commands on linux by LinuxGuide.it - over 350 commands! ...
- 查漏补缺,这些热门开源项目你都知道么?「GitHub 热点速览」
本期热点速览的周榜部分的项目,基本上每周都会在 GitHub Trending 见到它们的身影,因为它们实在太火了.一般来说,这些火爆的项目大家都耳熟能详,但是为了防止有些小伙伴不怎么逛 GitHub ...
- MySQL快速导入千万条数据(2)
目录 一.导入前1000万条数据 二.导入前2000万条数据 三.导入后面的1000万条数据 四.建索引 五.总结 接上文,继续测试3000万条记录快速导入数据库. 一.导入前1000万条数据 清库. ...
- JS逆向实战24—— 补环境过某房地产瑞数4.0
前言 瑞数就不过多介绍了,算是国内 2 线产品中的天花板了.4 代其实难度不高,但要弄出来 确实挺费时间和耐心的.今天就简单来讲讲如何用补环境轻松的过瑞数. 本文首发链接为: https://mp.w ...
- vue框架,input相同标签如何定位-label定位
一.问题提出: 后台前端框架改版,之前是angularjs,现在用vue,导致input标签定位失败,只能定位到第一个input标签,查看后台源代码发现这两个标签是一模一样,如下图: 二.问题思考过程 ...
- ESP32-MicroPython 开发环境
Linux/Mac 下使用MicroPython开发ESP32 刷入固件 使用 esptool.py 将 MicroPython 刷入 ESP32 开发板涉及几个步骤. 1. 安装 esptool 如 ...
- acwing第75场周赛
这次题比较水,但是还是没能ak,自己小结一下吧 第一道题就是自己枚举相加就行 第二道题是一个多关键字排序,wa了几次,是因为优先级有两个是相同的需要特判一下,然后可以把字符转化为数字的优先级,我用了一 ...
- OpenWrt主题在菜单中不显示
问题: 路径中有对应的主题,但是make menuconfig中不显示 原因: 需要建立软连接 1. 在路径 SDK-DR232-20221220/package/feeds/luci 中运行 ls ...