使用极限网关助力 ES 集群无缝升级、迁移上/下云
在工作中大家可能会遇到以下这些场景:
- 自建 ES 集群需要平滑迁移到 XX 云;
- 从 XX 云将 ES 集群迁移到自建机房;
- ES 集群进行跨版本升级,同时保留回退能力;
这些场景往往都还有个共同的需求:迁移过程要保证业务的最小停机时间。
幸运的是,在这三个场景中,我们都能使用极限网关来帮助我们进行更丝滑的迁移或升级。下面,我们以迁移 ES 集群上云为例,介绍下整个工作过程。
- 自建版本: 5.4.2
- 云上版本: 5.6.16
- Gateway 和 Console 建议用最新版本
迁移架构
通过将应用端流量走网关的方式,请求同步转发给自建 ES,网关记录所有的写入请求,并确保顺序在 XX 云 ES 上重放请求,两侧集群的各种故障都妥善进行了处理,从而实现透明的集群双写,实现安全无缝的数据迁移。
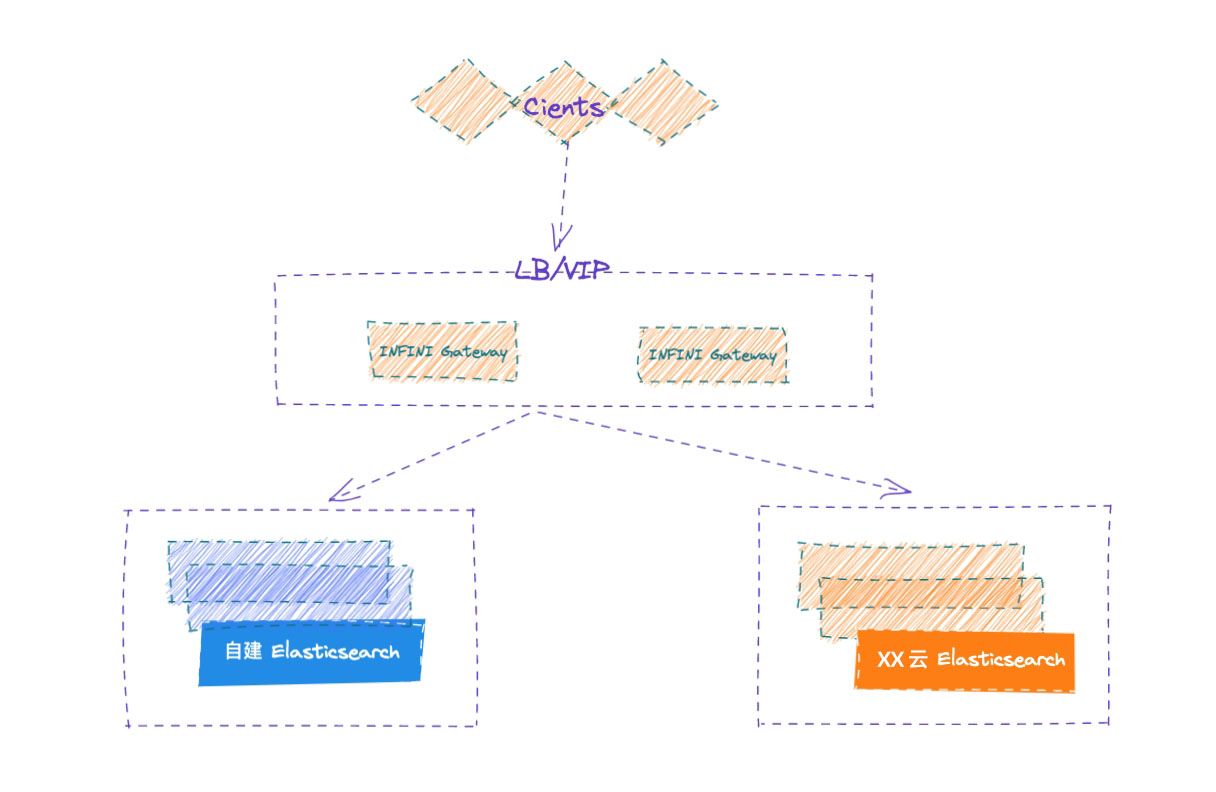
业务端如果已经部署在云上,可以使用云上的 SLB 服务来访问网关,确保后端网关的高可用,如果业务端和极限网关还在企业内网,可以使用极限网关自带的 4 层浮动 IP 来确保网关的 高可用 。
执行步骤
部署 INFINI Gateway
为了保证数据的无缝透明迁移,通过网关来进行双写。
修改网关配置
在此 下载 网关双写配置,默认网关会加载配置文件 gateway.yml 。如果要指定其他配置文件使用 -config 选项。
配置文件内容较多,下面仅展示必要部分。
#primary
PRIMARY_ENDPOINT: http://192.168.56.3:7171
PRIMARY_USERNAME: elastic
PRIMARY_PASSWORD: password
PRIMARY_MAX_QPS_PER_NODE: 10000
PRIMARY_MAX_BYTES_PER_NODE: 104857600 #100MB/s
PRIMARY_MAX_CONNECTION_PER_NODE: 200
PRIMARY_DISCOVERY_ENABLED: false
PRIMARY_DISCOVERY_REFRESH_ENABLED: false
#backup
BACKUP_ENDPOINT: http://192.168.56.3:9200
BACKUP_USERNAME: admin
BACKUP_PASSWORD: admin
BACKUP_MAX_QPS_PER_NODE: 10000
BACKUP_MAX_BYTES_PER_NODE: 104857600 #100MB/s
BACKUP_MAX_CONNECTION_PER_NODE: 200
BACKUP_DISCOVERY_ENABLED: false
BACKUP_DISCOVERY_REFRESH_ENABLED: false
PRIMARY_ENDPOINT:配置主集群地址和端口
PRIMARY_USERNAME、PRIMARY_PASSWORD: 访问主集群的用户信息
BACKUP_ENDPOINT:配置备集群地址和端口
BACKUP_USERNAME、BACKUP_PASSWORD: 访问备集群的用户信息
- 启动网关
启动网关并指定刚刚创建的配置,如下:
./gateway-linux-amd64 -config replication_via-disk.yml.yml
部署 INFINI Console
为了方便在多个集群之间快速切换,管理网关消费任务、查看队列等。使用 INFINI Console 来进行管理。
启动服务
./console-linux-amd64 -service install
./console-linux-amd64 -service start注册资源
将 ES 集群、极限网关都注册到 Console 中。- 注册 ES 集群:方便切换集群,执行命令。除了新旧集群外,将网关也在此注册一次,方便验证网关功能。
- 注册 Gateway:管理网关任务、队列。
测试 INFINI Gateway
为了验证网关是否正常工作,我们通过 INFINI Console 来快速验证一下。
首先通过走网关的接口来创建一个索引,并写入一个文档,如下:
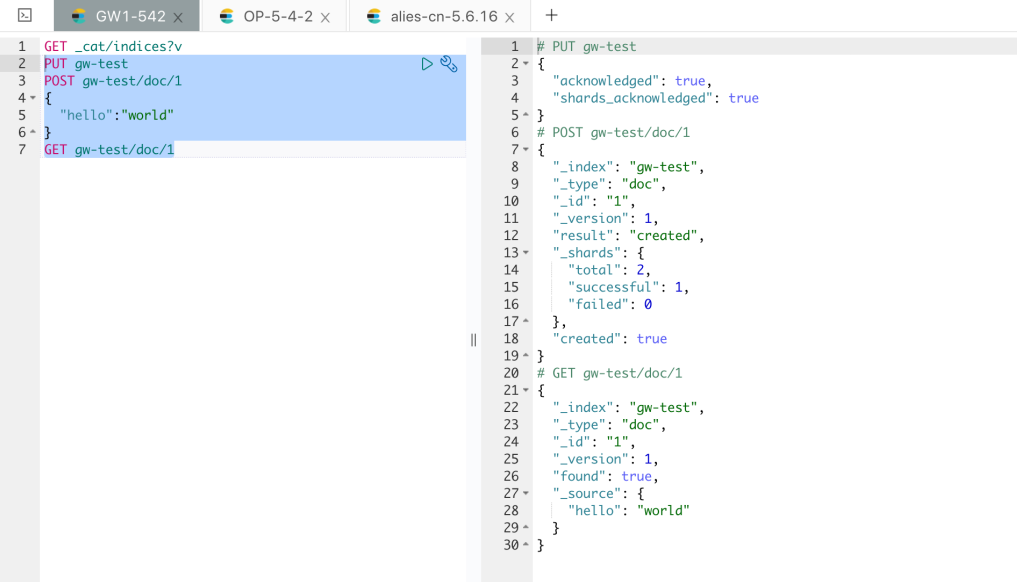
查看 5.4.2 集群的数据情况,如下:
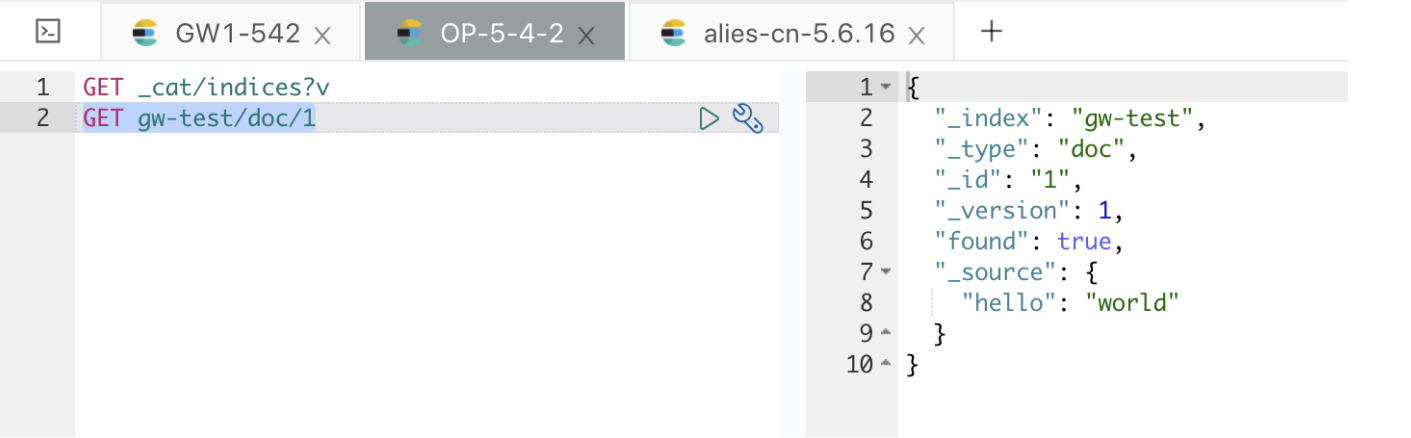
查看集群 5.6.16 的数据情况,如下:

数据一致,说明网关配置都正常,验证结束。
调整网关的消费策略
因为我们需要在全量数据迁移之后,才能进行增量数据的追加,在全量数据迁移完成之前,我们应该暂停增量数据的消费。修改网关配置里面 Pipeline consume-queue_backup-bulk_request_ingestion-to-backup的参数 auto_start为 false,表示不自动启动该任务,具体配置方法如下:
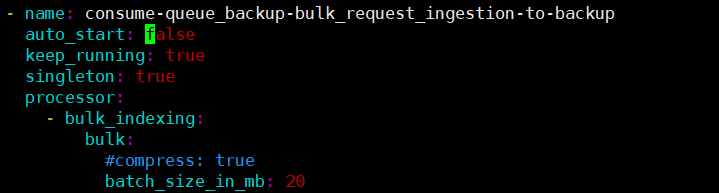
修改完配置之后,需要重新启动网关。
由于之前已经注册了网关,待全量迁移完成之后,可以通过后台的 Task 管理来进行后续的任务启动、停止,如下:

切换流量
接下来,将业务正常写的流量切换到网关,也就是需要把之前指向 ES 5.4.2 的地址指向网关的地址,如果 5.4.2 集群开启了身份验证,业务端代码同样需要传递身份信息,和 5.4.2 之前的用法保持不变。
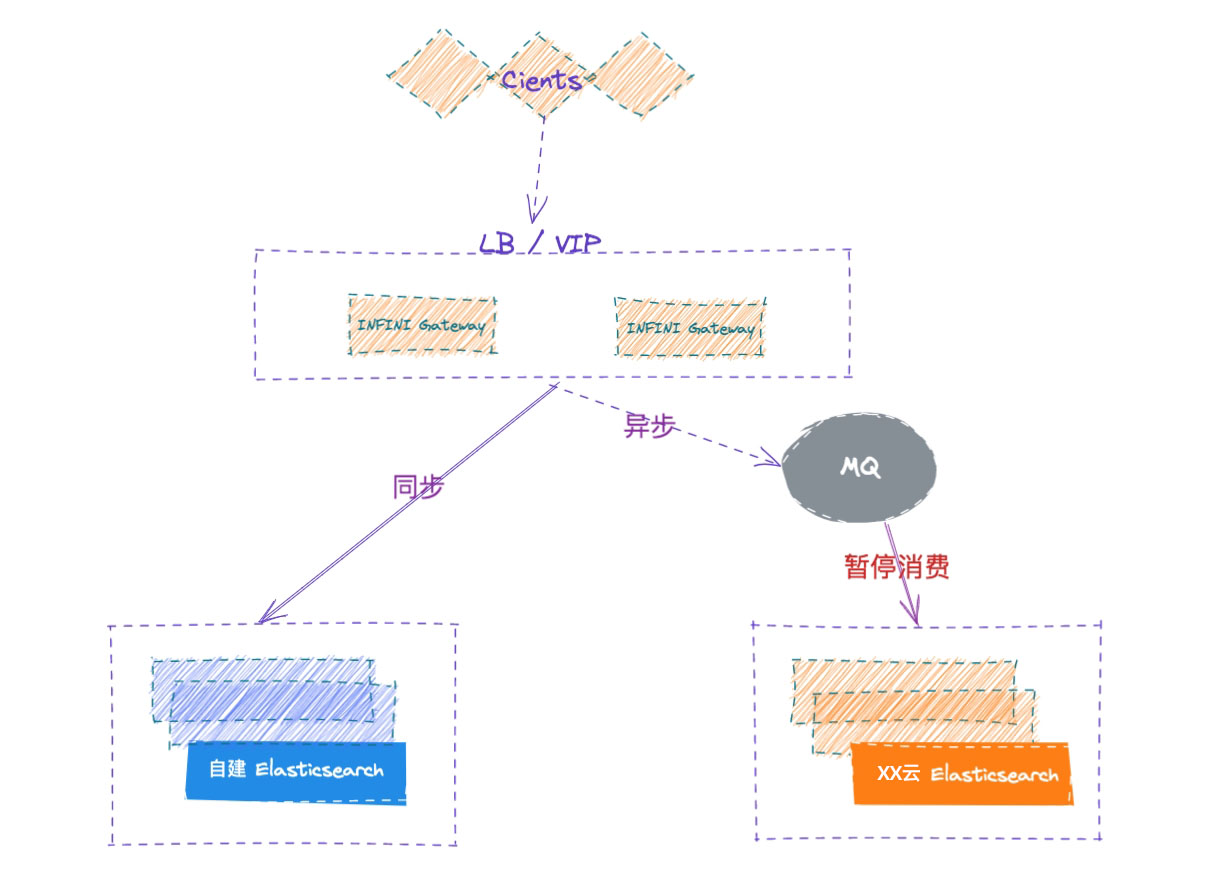
切换流量到网关之后,用户的请求还是以同步的方式正常访问自建集群,网关记录到的请求会按顺序记录到 MQ 里面,但是消费是暂停状态。
如果业务端代码使用的 ES 的 SDK 支持 Sniff,并且业务代码开启了 Sniff,那么应该关闭 Sniff,避免业务端通过 Sniff 直接链接到后端的 ES 节点,所有的流量现在应该都只通过网关来进行访问。
全量数据迁移
在流量迁移到网关之后,我们开始对自建 Elasticsearch 集群的数据进行全量迁移到 XX 云 Elasticsearch 集群。
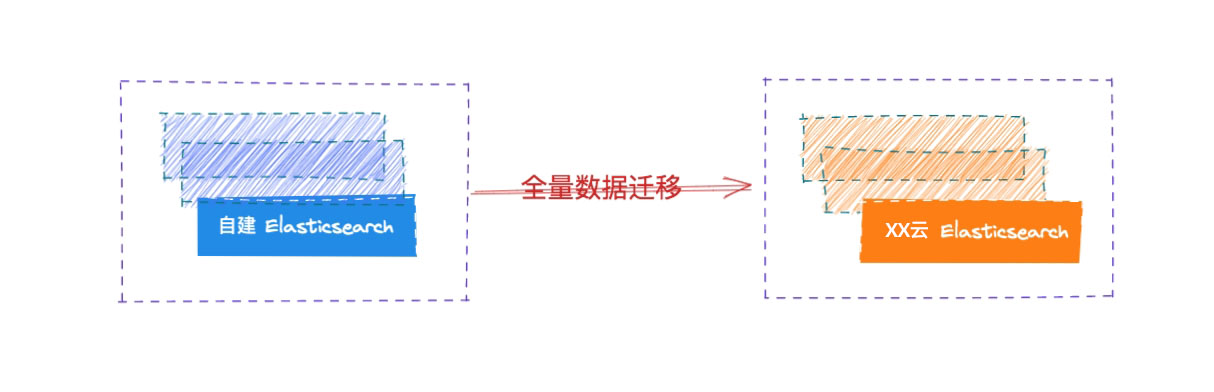
全量迁移已有的数据的方式有很多种:
- 通过快照的方式进行恢复
- 使用 INFINI Console 进行数据迁移
增量数据迁移
在全量导入的过程中,可能存在数据的增量修改,不过这部分请求都已经完整记录下来了,我们只需要开启网关的消费任务即可将积压的请求应用到云端的 ES 集群。

示例操作如下:

通过观察队列是否消费完成来判断增量数据是否做完,如下:
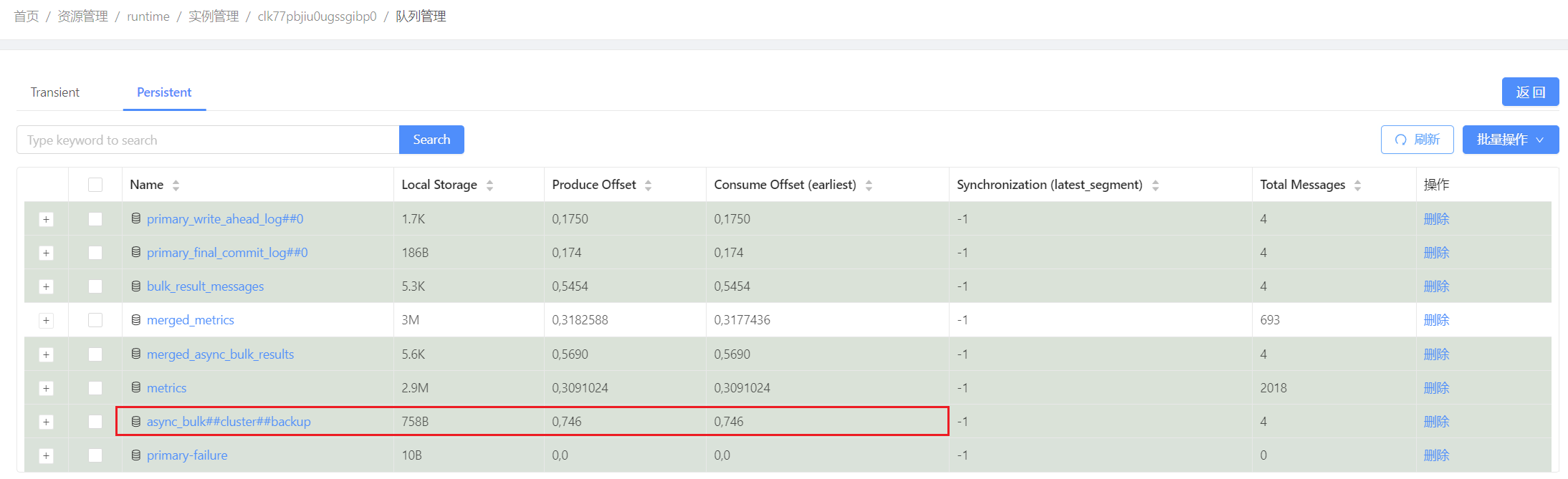
执行数据比对
由于集群内部的数据可能比较多,我们需要进行一个完整的比对才能确保数据的完整性,可以通过 INFINI Console 的数据比对 工具来进行。
切换集群
如果验证完之后,两个集群的数据已经完全一致了,可以将程序切换到新集群,或者将网关的配置里面的主备进行互换,仍旧写两个集群,先写云端集群,再写自建集群。
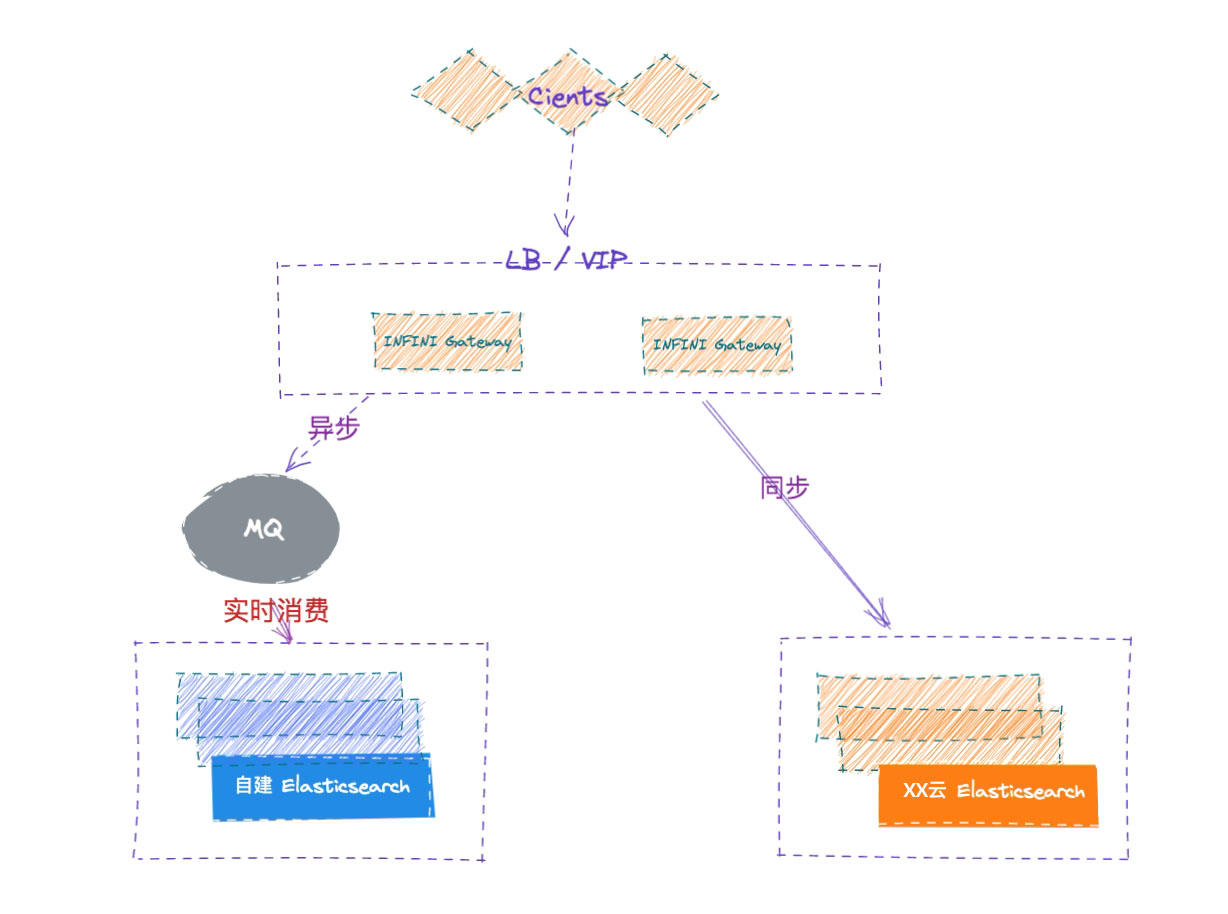
双集群在线运行一段时间,待业务完全验证之后,再安全下线老集群,如遇到问题,也可以随时回切到老集群。
小结
通过使用极限网关,自建 ES 集群可以安全无缝的迁移上云,在迁移的过程中,两套集群通过网关进行了解耦,两套集群的版本也可以不一样,在迁移的过程中还能实现版本的无缝升级。
工作流程图

使用极限网关助力 ES 集群无缝升级、迁移上/下云的更多相关文章
- ES集群7.3.0设置快照,存储库进行索引备份和恢复等
说明:三台ES节点组成ES集群,一台kibana主机,版本均是7.3.0,白金试用版 官方地址:https://www.elastic.co/guide/en/elasticsearch/refere ...
- ELasticSearch(五)ES集群原理与搭建
一.ES集群原理 查看集群健康状况:URL+ /GET _cat/health (1).ES基本概念名词 Cluster 代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产 ...
- 多es 集群数据迁移方案
前言 加入新公司的第二个星期的星期二 遇到另一个项目需要技术性支持:验证es多集群的数据备份方案,需要我参与验证,在这个项目中需要关注到两个集群的互通性.es集群是部署在不同的k8s环境中,K8s环境 ...
- elasticsearch(es) 集群恢复触发配置(Local Gateway参数)
elasticsearch(es) 集群恢复触发配置(Local Gateway) 当你集群重启时,几个配置项影响你的分片恢复的表现. 首先,我们需要明白如果什么也没配置将会发生什么. 想象一下假设你 ...
- ES 集群调整、升级 最佳实践
日常应用中我们会经常对es 集群做一些参数调整或者升级版本,但是每次关闭节点再打开 其中的数据同步的痛苦估计有很多人领悟过(有可能出现IO或者网络拥堵导致恶性循环)官网有套方案可以尝试一下: 1.关掉 ...
- windows单节点下安装es集群
linux下的es的tar包,拖到windows下,配置后,启动bin目录下的bat文件,也是可以正常运行的. 从linux下拷的tar包,需要修改虚拟机的内存elasticsearch.in.bat ...
- ES 集群上,业务单点如何优化升级?
摘要: 原创出处 https://www.bysocket.com 「公众号:泥瓦匠BYSocket 」欢迎关注和转载,保留摘要,谢谢! ES 基础 ES 集群 ES 集群上业务优化 一.ES 基础 ...
- es集群数据库~运维相关
一 数据同步方案 1 ES-JDBC 不能实现删除同步操作.MYSQL如果删除,ES不会删除 2 logstash-input-jdbc 能实现insert update,但是仍然不能实现删除 ...
- elasticsearch系列八:ES 集群管理(集群规划、集群搭建、集群管理)
一.集群规划 搭建一个集群我们需要考虑如下几个问题: 1. 我们需要多大规模的集群? 2. 集群中的节点角色如何分配? 3. 如何避免脑裂问题? 4. 索引应该设置多少个分片? 5. 分片应该设置几个 ...
- docker 快速部署ES集群 spark集群
1) 拉下来 ES集群 spark集群 两套快速部署环境, 并只用docker跑起来,并保存到私库. 2)弄清楚怎么样打包 linux镜像(或者说制作). 3)试着改一下,让它们跑在集群里面. 4) ...
随机推荐
- Oracle ORA-12725 unmatched parentheses in regular expression
Oracle ORA-12725 unmatched parentheses in regular expression 简单来说就是正则表达式中的括号问题 这种一般就可以锁定使用正则的函数,例如 r ...
- 基于阿里云GPU云服务器的AIACC助力UC搜索业务性能提效380%,每年节省数千万成本
简介: 用阿里云GPU计算实例来满足UC极致性价比需求 文丨阿里云神龙计算平台AI加速团队 & UC搜索架构部推理引擎团队 导语:作为国产行列里占有率排名第一的移动浏览器,UC浏览器自身承载着 ...
- 重磅发布:微服务引擎 MSE 专业版
简介: 性能提升 10 倍,更高的 SLA 保障,新用户限时抢购 8 折资源包. 微服务引擎 MSE 专业版发布,支持 Nacos 2.0 ,相比基础版,专业版具有更高的 SLA 保障,性能提升十倍, ...
- 谁来拯救存量SGX1平台?又一个内核特性合并的血泪史
简介: 今天的故事主角,是一个被称为Flexible Launch Control的SGX平台特性. 前言 自从Intel内核开发人员Jarkko Sakkinen于2017年9月2日在inte ...
- 使用ssh连接远程仓库的方法(github)
使用ssh连接远程仓库的方法 但是当我登录虚拟机想提交csapp的代码时,我发现需要验证我的账号密码,感觉每次提交都要输入这个很麻烦.然后就在网上查询了下为何提交代码需要输入账号密码. 使用 HTTP ...
- vue+vant+js实现购物车原理小demo(基础版)
电商毕业设计里的一个购物车demo,拿vue+vant需要写的核心计算代码只有12行.效果图: main.js: Vue.use(Stepper); .vue文件 <template> & ...
- ORACLE查询表的DML最后时间和操作记录条数
ORACLE查询表的DML最后时间和操作记录条数 其中user代表当前用户的.dba代表的是有dba可以看到的相关表. select * from all_tab_modifications; sel ...
- NSThread的start方法内部做了什么?
下面是NSThread start方法的汇编码: 1 1 1 ;Foundation`-[NSThread start]: 2 2 2 -> 0x7fff2594f47f <+0>: ...
- LVS负载均衡(6)--LVS调度算法详解
目录 1. LVS调度算法详解 1.1 静态调度算法 1.1.1 RR调度算法 1.1.2 WRR调度算法 1.1.3 SH调度算法 1.1.4 DH调度算法 1.2 动态调度算法 1.2.1 LC调 ...
- make编译报错:fatal error: filesystem: 没有那个文件或目录 #include <filesystem>
报错: fatal error: filesystem: 没有那个文件或目录 #include(filesystem) 解决方法一: 修改头文件 #include <experimental/f ...