2023-06-18:给定一个长度为N的一维数组scores, 代表0~N-1号员工的初始得分, scores[i] = a, 表示i号员工一开始得分是a, 给定一个长度为M的二维数组operatio
2023-06-18:给定一个长度为N的一维数组scores, 代表0~N-1号员工的初始得分,
scores[i] = a, 表示i号员工一开始得分是a,
给定一个长度为M的二维数组operations,
operations[i] = {a, b, c}。
表示第i号操作为 :
如果a==1, 表示将目前分数<b的所有员工,分数改成b,c这个值无用,
如果a==2, 表示将编号为b的员工,分数改成c,
所有操作从0~M-1, 依次发生。
返回一个长度为N的一维数组ans,表示所有操作做完之后,每个员工的得分是多少。
1 <= N <= 10的6次方,
1 <= M <= 10的6次方,
0 <= 分数 <= 10的9次方。
来自TikTok美国笔试。
答案2023-06-18:
具体步骤如下:
1.创建一个长度为N的一维数组scores,表示每个员工的初始得分。
2.创建一个长度为M的二维数组operations,表示操作序列。
3.定义一个函数operateScores2来处理操作序列。
4.初始化一个节点数组nodes,用于存储每个员工的节点信息。
5.初始化一个空的得分和桶的映射表scoreBucketMap。
6.遍历scores数组,为每个得分值创建一个桶,并将对应的员工节点添加到桶中。
7.遍历operations数组,处理每个操作。
8.对于类型为1的操作,获取小于当前得分的最大得分值floorKeyV,然后将它们的桶合并到新的得分值对应的桶中。
9.对于类型为2的操作,获取该员工节点,并将其从原来的桶中移除,然后添加到新的得分值对应的桶中。
10.遍历得分和桶的映射表scoreBucketMap,将桶中的员工节点按照顺序取出,更新到结果数组ans中。
11.返回最终的结果数组ans。
12.进行功能测试和性能测试。
时间复杂度分析:
遍历
scores数组并创建桶,时间复杂度为O(N)。遍历
operations数组,每个操作的时间复杂度为O(logN)(由于使用了有序映射表来实现桶,检索操作的时间复杂度为O(logN))。遍历得分和桶的映射表
scoreBucketMap,每个桶中的员工节点数量为O(1),遍历的时间复杂度为O(N)。总体时间复杂度为O(N + KlogN),其中K为操作序列的长度。
空间复杂度分析:
创建一个长度为N的数组
scores,空间复杂度为O(N)。创建一个长度为M的数组
operations,空间复杂度为O(M)。创建一个长度为N的节点数组
nodes,空间复杂度为O(N)。创建一个有序映射表
scoreBucketMap,储存每个得分值对应的桶,空间复杂度为O(N)。结果数组
ans的长度为N,空间复杂度为O(N)。总体空间复杂度为O(N + M)。
go完整代码如下:
package main
import (
"fmt"
"math/rand"
"time"
)
// 桶,得分在有序表里!桶只作为有序表里的value,不作为key
type Bucket struct {
head *Node
tail *Node
}
func NewBucket() *Bucket {
head := &Node{index: -1}
tail := &Node{index: -1}
head.next = tail
tail.last = head
return &Bucket{head: head, tail: tail}
}
func (b *Bucket) add(node *Node) {
node.last = b.tail.last
node.next = b.tail
b.tail.last.next = node
b.tail.last = node
}
func (b *Bucket) merge(join *Bucket) {
if join.head.next != join.tail {
b.tail.last.next = join.head.next
join.head.next.last = b.tail.last
join.tail.last.next = b.tail
b.tail.last = join.tail.last
join.head.next = join.tail
join.tail.last = join.head
}
}
// Node represents a node in the bucket
type Node struct {
index int
last *Node
next *Node
}
func (n *Node) connectLastNext() {
n.last.next = n.next
n.next.last = n.last
}
// 暴力方法
func operateScores1(scores []int, operations [][]int) []int {
n := len(scores)
ans := make([]int, n)
copy(ans, scores)
for _, op := range operations {
if op[0] == 1 {
for i := 0; i < n; i++ {
ans[i] = max(ans[i], op[1])
}
} else {
ans[op[1]] = op[2]
}
}
return ans
}
// 正式方法
func operateScores2(scores []int, operations [][]int) []int {
n := len(scores)
nodes := make([]*Node, n)
scoreBucketMap := make(map[int]*Bucket)
for i := 0; i < n; i++ {
nodes[i] = &Node{index: i}
if _, ok := scoreBucketMap[scores[i]]; !ok {
scoreBucketMap[scores[i]] = NewBucket()
}
scoreBucketMap[scores[i]].add(nodes[i])
}
for _, op := range operations {
if op[0] == 1 {
floorKeyV := floorKey(scoreBucketMap, op[1]-1)
if floorKeyV != -1 && scoreBucketMap[op[1]] == nil {
scoreBucketMap[op[1]] = NewBucket()
}
for floorKeyV != -1 {
scoreBucketMap[op[1]].merge(scoreBucketMap[floorKeyV])
delete(scoreBucketMap, floorKeyV)
floorKeyV = floorKey(scoreBucketMap, op[1]-1)
}
} else {
cur := nodes[op[1]]
cur.connectLastNext()
if scoreBucketMap[op[2]] == nil {
scoreBucketMap[op[2]] = NewBucket()
}
scoreBucketMap[op[2]].add(cur)
}
}
ans := make([]int, n)
for score, bucket := range scoreBucketMap {
cur := bucket.head.next
for cur != bucket.tail {
ans[cur.index] = score
cur = cur.next
}
}
return ans
}
func floorKey(m map[int]*Bucket, target int) int {
for score := range m {
if score <= target {
return score
}
}
return -1
}
func max(a, b int) int {
if a > b {
return a
}
return b
}
// RandomScores generates an array of random scores
func randomScores(n, v int) []int {
scores := make([]int, n)
rand.Seed(time.Now().UnixNano())
for i := 0; i < n; i++ {
scores[i] = rand.Intn(v)
}
return scores
}
// RandomOperations generates a 2D array of random operations
func randomOperations(n, m, v int) [][]int {
operations := make([][]int, m)
rand.Seed(time.Now().UnixNano())
for i := 0; i < m; i++ {
operations[i] = make([]int, 3)
if rand.Float32() < 0.5 {
operations[i][0] = 1
operations[i][1] = rand.Intn(v)
} else {
operations[i][0] = 2
operations[i][1] = rand.Intn(n)
operations[i][2] = rand.Intn(v)
}
}
return operations
}
// IsEqual checks if two arrays are equal
func isEqual(arr1, arr2 []int) bool {
if len(arr1) != len(arr2) {
return false
}
for i := 0; i < len(arr1); i++ {
if arr1[i] != arr2[i] {
return false
}
}
return true
}
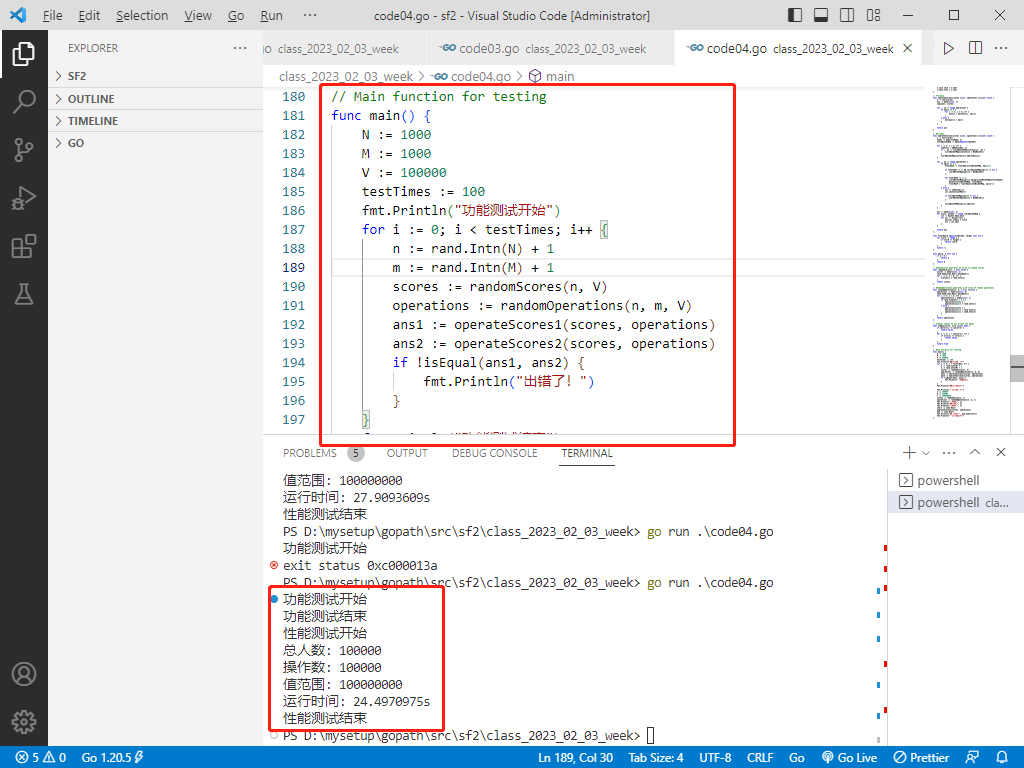
// Main function for testing
func main() {
N := 1000
M := 1000
V := 100000
testTimes := 100
fmt.Println("功能测试开始")
for i := 0; i < testTimes; i++ {
n := rand.Intn(N) + 1
m := rand.Intn(M) + 1
scores := randomScores(n, V)
operations := randomOperations(n, m, V)
ans1 := operateScores1(scores, operations)
ans2 := operateScores2(scores, operations)
if !isEqual(ans1, ans2) {
fmt.Println("出错了!")
}
}
fmt.Println("功能测试结束")
fmt.Println("性能测试开始")
n := 100000
m := 100000
v := 100000000
scores := randomScores(n, v)
operations := randomOperations(n, m, v)
fmt.Println("总人数:", n)
fmt.Println("操作数:", n)
fmt.Println("值范围:", v)
start := time.Now()
operateScores2(scores, operations)
end := time.Now()
fmt.Println("运行时间:", end.Sub(start))
fmt.Println("性能测试结束")
}
c++完整代码如下:
#include <iostream>
#include <vector>
#include <map>
#include <random>
#include <ctime>
using namespace std;
class Bucket;
// Node represents a node in the bucket
class Node {
public:
int index;
Node* last;
Node* next;
void connectLastNext() {
last->next = next;
next->last = last;
}
};
// Bucket, scores stored in a sorted list
class Bucket {
public:
Node* head;
Node* tail;
Bucket() {
head = new Node();
tail = new Node();
head->index = -1;
tail->index = -1;
head->next = tail;
tail->last = head;
}
void add(Node* node) {
node->last = tail->last;
node->next = tail;
tail->last->next = node;
tail->last = node;
}
void merge(Bucket* join) {
if (join->head->next != join->tail) {
tail->last->next = join->head->next;
join->head->next->last = tail->last;
join->tail->last->next = tail;
tail->last = join->tail->last;
join->head->next = join->tail;
join->tail->last = join->head;
}
}
};
vector<int> operateScores1(const vector<int>& scores, const vector<vector<int>>& operations) {
int n = scores.size();
vector<int> ans(scores);
for (const auto& op : operations) {
if (op[0] == 1) {
for (int i = 0; i < n; i++) {
ans[i] = max(ans[i], op[1]);
}
}
else {
ans[op[1]] = op[2];
}
}
return ans;
}
int floorKey(const map<int, Bucket*>& m, int target);
vector<int> operateScores2(const vector<int>& scores, const vector<vector<int>>& operations) {
int n = scores.size();
vector<Node*> nodes(n);
map<int, Bucket*> scoreBucketMap;
for (int i = 0; i < n; i++) {
nodes[i] = new Node();
nodes[i]->index = i;
if (scoreBucketMap.find(scores[i]) == scoreBucketMap.end()) {
scoreBucketMap[scores[i]] = new Bucket();
}
scoreBucketMap[scores[i]]->add(nodes[i]);
}
for (const auto& op : operations) {
if (op[0] == 1) {
int floorKeyV = floorKey(scoreBucketMap, op[1] - 1);
if (floorKeyV != -1 && scoreBucketMap.find(op[1]) == scoreBucketMap.end()) {
scoreBucketMap[op[1]] = new Bucket();
}
while (floorKeyV != -1) {
scoreBucketMap[op[1]]->merge(scoreBucketMap[floorKeyV]);
scoreBucketMap.erase(floorKeyV);
floorKeyV = floorKey(scoreBucketMap, op[1] - 1);
}
}
else {
Node* cur = nodes[op[1]];
cur->connectLastNext();
if (scoreBucketMap.find(op[2]) == scoreBucketMap.end()) {
scoreBucketMap[op[2]] = new Bucket();
}
scoreBucketMap[op[2]]->add(cur);
}
}
vector<int> ans(n);
for (const auto& entry : scoreBucketMap) {
int score = entry.first;
Bucket* bucket = entry.second;
Node* cur = bucket->head->next;
while (cur != bucket->tail) {
ans[cur->index] = score;
cur = cur->next;
}
}
return ans;
}
int floorKey(const map<int, Bucket*>& m, int target) {
for (const auto& entry : m) {
int score = entry.first;
if (score <= target) {
return score;
}
}
return -1;
}
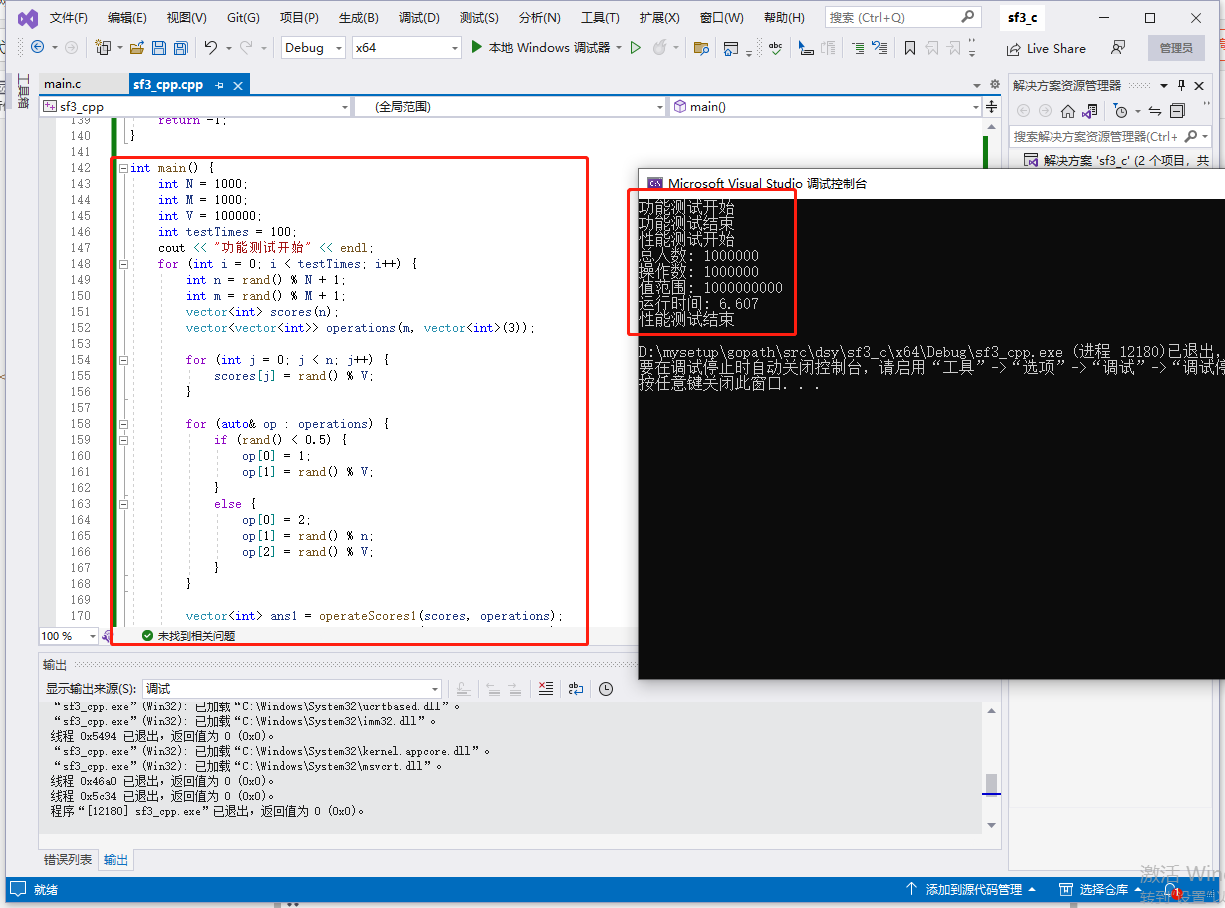
int main() {
int N = 1000;
int M = 1000;
int V = 100000;
int testTimes = 100;
cout << "功能测试开始" << endl;
for (int i = 0; i < testTimes; i++) {
int n = rand() % N + 1;
int m = rand() % M + 1;
vector<int> scores(n);
vector<vector<int>> operations(m, vector<int>(3));
for (int j = 0; j < n; j++) {
scores[j] = rand() % V;
}
for (auto& op : operations) {
if (rand() < 0.5) {
op[0] = 1;
op[1] = rand() % V;
}
else {
op[0] = 2;
op[1] = rand() % n;
op[2] = rand() % V;
}
}
vector<int> ans1 = operateScores1(scores, operations);
vector<int> ans2 = operateScores2(scores, operations);
if (ans1 != ans2) {
cout << "出错了!" << endl;
}
}
cout << "功能测试结束" << endl;
cout << "性能测试开始" << endl;
int n = 1000000;
int m = 1000000;
int v = 1000000000;
vector<int> scores(n);
vector<vector<int>> operations(m, vector<int>(3));
for (int i = 0; i < n; i++) {
scores[i] = rand() % v;
}
for (auto& op : operations) {
op[0] = rand() < 0.5 ? 1 : 2;
op[1] = rand() % n;
op[2] = rand() % v;
}
cout << "总人数: " << n << endl;
cout << "操作数: " << m << endl;
cout << "值范围: " << v << endl;
clock_t start = clock();
operateScores2(scores, operations);
clock_t end = clock();
cout << "运行时间: " << double(end - start) / CLOCKS_PER_SEC << endl;
cout << "性能测试结束" << endl;
return 0;
}
2023-06-18:给定一个长度为N的一维数组scores, 代表0~N-1号员工的初始得分, scores[i] = a, 表示i号员工一开始得分是a, 给定一个长度为M的二维数组operatio的更多相关文章
- C语言数组:C语言数组定义、二维数组、动态数组、字符串数组
1.C语言数组的概念 在<更加优美的C语言输出>一节中我们举了一个例子,是输出一个 4×4 的整数矩阵,代码如下: #include <stdio.h> #include &l ...
- C语言之二维数组
二维数组 还是一个数组,只不过数组中得每一个元素又是一个数组 1). 声明语法 类型 数组名[行][列]; 例: int nums[2][3];//2行3列的二维数组,保存的数据类型是int类型 c ...
- 数组属性的习题、Arrays工具、二维数组
一.数组的练习 1.声明一个char类型的数组, 从键盘录入6个字符: [1]遍历输出 [2]排序 [3]把char数组转化成一个逆序的数组. import java.util.Scanner; pu ...
- 常用的Arrays类和二维数组以及二分法的介绍
---恢复内容开始--- 1.Array类 Array中包含了许多数组的常用操作,较为常见的有: (1)快速输出 import java.util.Arrays; public class Test{ ...
- Java数组之二维数组
Java中除了一维数组外,还有二维数组,三维数组等多维数组.本文以介绍二维数组来了解多维数组. 1.二维数组的基础 二维数组的定义:二维数组就是数组的数组,数组里的元素也是数组. 二维数组表示行列二维 ...
- C语言二维数组
上节讲解的数组可以看作是一行连续的数据,只有一个下标,称为一维数组.在实际问题中有很多数据是二维的或多维的,因此C语言允许构造多维数组.多维数组元素有多个下标,以确定它在数组中的位置.本节只介绍二维数 ...
- LeetCode二维数组中的查找
LeetCode 二维数组中的查找 题目描述 在一个 n*m 的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增.请完成一个搞笑的函数,输入这样的一个二维数组和一个整数,判断数 ...
- LeetCode - 二维数组及滚动数组
1. 二维数组及滚动数组总结 在二维数组num[i][j]中,每个元素都是一个数组.有时候,二维数组中的某些元素在整个运算过程中都需要用到:但是有的时候我们只需要用到前一个或者两个数组,此时我们便可以 ...
- Java基础——二维数组
package com.zhao.demo; public class Demo08 { public static void main(String[] args) { //二维数组 int[][] ...
- 《剑指Offer》面试题-二维数组中的查找
题目1384:二维数组中的查找 时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:7318 解决:1418 题目描述: 在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到 ...
随机推荐
- 别逛了,送你一份2023年Java核心篇JVM(虚拟机)面试题整理
Java内存区域 说一下 JVM 的主要组成部分及其作用? JVM包含两个子系统和两个组件,两个子系统为Class loader(类装载).Execution engine(执行引擎):两个组件为Ru ...
- 深入理解 python 虚拟机:字节码教程(1)——原来装饰器是这样实现的
深入理解 python 虚拟机:字节码教程(1)--原来装饰器是这样实现的 在本篇文章当中主要给大家介绍在 cpython 当中一些比较常见的字节码,从根本上理解 python 程序的执行.在本文当中 ...
- 四月八号java基础
1.复合语句:JAVA语言不允许在两个嵌套的复合语句内声明同样的变量 2.注释:1)单行注释// 2)多行注释/*......*/3)/**......*/文件注释 3.else总是与之最近的if结构 ...
- python轻量级性能工具-Locust
Locust基于python的协程机制,打破了线程进程的限制,可以能够在一台测试机上跑高并发 性能测试基础 1.快慢:衡量系统的处理效率:响应时间 2.多少:衡量系统的处理能力:单位时间内能处理多少个 ...
- vCenter报错:Log Disk Exhaustion on 10
vCenter报错:Log Disk Exhaustion on 10 1.问题现象: 巡检时发现 vCenter Server 中,错误显示为:Log Disk Exhaustion on 10(字 ...
- js 获取 ajax返回数据及处理
$.ajax({ url: "http://xiaocui.dgoods.cn/app/index.php?i=5&c=entry&do=check&m=stonef ...
- Layui+dtree实现左边分类列表,右边数据列表
效果如下 代码实现 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> < ...
- 2020-08-31:描述HTTP的版本之间的区别,主要是1.0/1.1/2.0三个版本的区别。
福哥答案2020-08-31: HTTP1.0与HTTP1.1的主要区别 1.长连接HTTP1.0:需要使用keep-alive参数来告知服务器端要建立一个长连接.HTTP1.1:默认支持长连接.2. ...
- 2020-08-21:网络IO模型有哪些?
福哥答案2020-08-21: 福哥口诀法:阻非复信异(阻塞.非阻塞.多路复用.信号驱动.异步) [知乎答案](https://www.zhihu.com/question/416128059)操作系 ...
- 2022-07-14:以下go语言代码输出什么?A:1;B:3;C:4;D:编译错误。 package main import ( “fmt“ ) func main() { a
2022-07-14:以下go语言代码输出什么?A:1:B:3:C:4:D:编译错误. package main import ( "fmt" ) func main() { a ...