tensorflow的官方强化学习库agents的相关内容及一些注意事项
源代码地址:
https://github.com/tensorflow/agents
TensorFlow给出的官方文档说明:
https://tensorflow.google.cn/agents
相关视频:
https://www.youtube.com/watch?v=U7g7-Jzj9qo
https://www.youtube.com/watch?v=tAOApRQAgpc
https://www.youtube.com/watch?v=52DTXidSVWc&list=PLQY2H8rRoyvxWE6bWx8XiMvyZFgg_25Q_&index=2
-----------------------------------------------------------
框架实现的算法:
论文1:
论文3:
论文4:
论文5:
论文6:
论文7:
论文8:
论文9:
论文10:
====================================
1. gym的环境版本有要求,给出具体安装及Atari的安装:
pip install gym[atari]==0.23.0
pip install gym[accept-rom-license]
=====================================
2. 代码的逻辑bug
tf_agents/specs/array_spec.py 代码bug:
def sample_bounded_spec(spec, rng):
"""Samples the given bounded spec. Args:
spec: A BoundedSpec to sample.
rng: A numpy RandomState to use for the sampling. Returns:
An np.array sample of the requested spec.
"""
tf_dtype = tf.as_dtype(spec.dtype)
low = spec.minimum
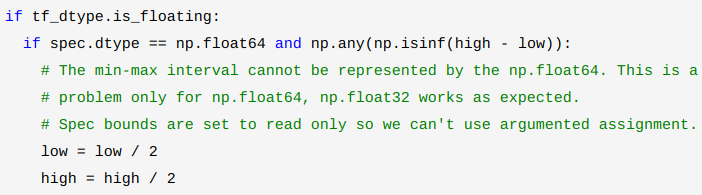
high = spec.maximum if tf_dtype.is_floating:
if spec.dtype == np.float64 and np.any(np.isinf(high - low)):
# The min-max interval cannot be represented by the np.float64. This is a
# problem only for np.float64, np.float32 works as expected.
# Spec bounds are set to read only so we can't use argumented assignment.
low = low / 2
high = high / 2
return rng.uniform(
low,
high,
size=spec.shape,
).astype(spec.dtype) else:
if spec.dtype == np.int64 and np.any(high - low < 0):
# The min-max interval cannot be represented by the tf_dtype. This is a
# problem only for int64.
low = low / 2
high = high / 2 if np.any(high < tf_dtype.max):
high = np.where(high < tf_dtype.max, high + 1, high)
elif spec.dtype != np.int64 or spec.dtype != np.uint64:
# We can still +1 the high if we cast it to the larger dtype.
high = high.astype(np.int64) + 1 if low.size == 1 and high.size == 1:
return rng.randint(
low,
high,
size=spec.shape,
dtype=spec.dtype,
)
else:
return np.reshape(
np.array([
rng.randint(low, high, size=1, dtype=spec.dtype)
for low, high in zip(low.flatten(), high.flatten())
]), spec.shape)
这个代码的意思就是在给定区间能进行均匀抽样,但是由于区间可能过大因此导致无法使用库函数抽样,因此需要对区间进行压缩。
当抽样的数据类型为np.float64时,由代码:
np.array(np.zeros(10), dtype=np.float64)+np.finfo(np.float64).max-np.finfo(np.float64).min

np.random.uniform(size=10, low=np.finfo(np.float64).min, high=np.finfo(np.float64).max)

可以知道,当类型为np.float64时,如果抽样区间过大会(超出数值表示范围)导致无法抽样,因此进行压缩区间:
当数据类型为np.float32时,虽然也会存在超出表示范围的问题:
np.array(np.zeros(10), dtype=np.float32)+np.finfo(np.float32).max-np.finfo(np.float32).min

但是由于函数 np.random.uniform 的计算中会把np.float32转为np.float64,因此不会出现报错,如下:
np.random.uniform(size=10, low=np.finfo(np.float32).min, high=np.finfo(np.float32).max)

---------------------------------------------------
当数值类型为int时,区间访问过大的检测代码为:
np.any(high - low < 0)
原因在意np.float类型数值超出表示范围会表示为infi变量,但是int类型则会以溢出形式表现,如:

但是在使用numpy.random.randint 函数时,即使范围为最大范围也没有报错:
np.random.randint(size=10000, low=tf.as_dtype(np.int64).min, high=tf.as_dtype(np.int64).max)

np.random.randint(size=10000, low=np.iinfo(np.int64).min, high=np.iinfo(np.int64).max)

而且即使由于high值是取开区间的,我们对high值加1以后也没有报错:
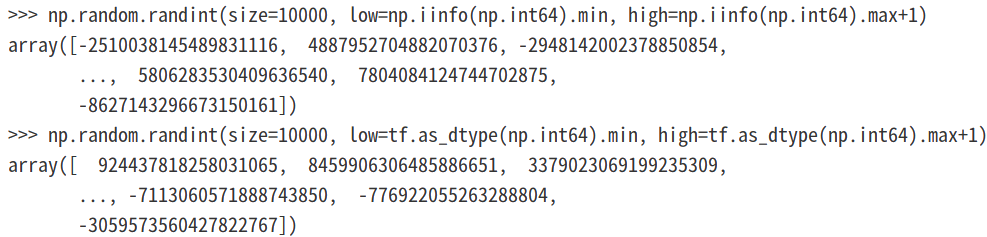
但是需要注意,此时传给np.random.randint函数中的low和high数值都为python数据类型int而不是numpy中的np.int64,下面我们看下numpy.float64类型是否会溢出:
当以数组形式传递最高high值并使其保持np.float64类型,发现使用high+1就会溢出:
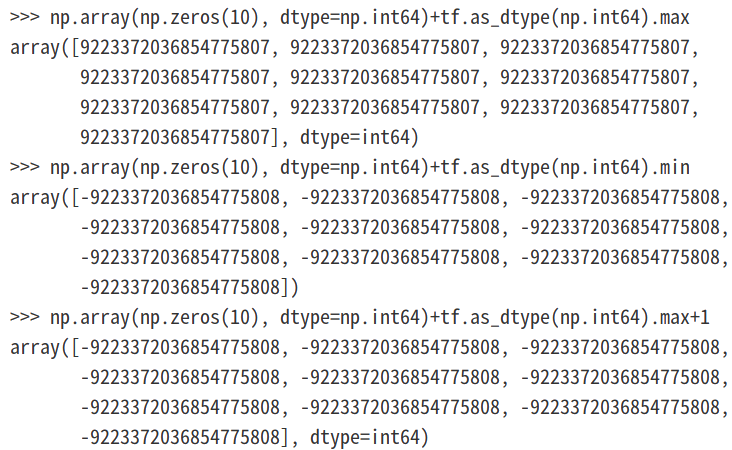
可以看到使用最大范围+1作为high值会导致报错:
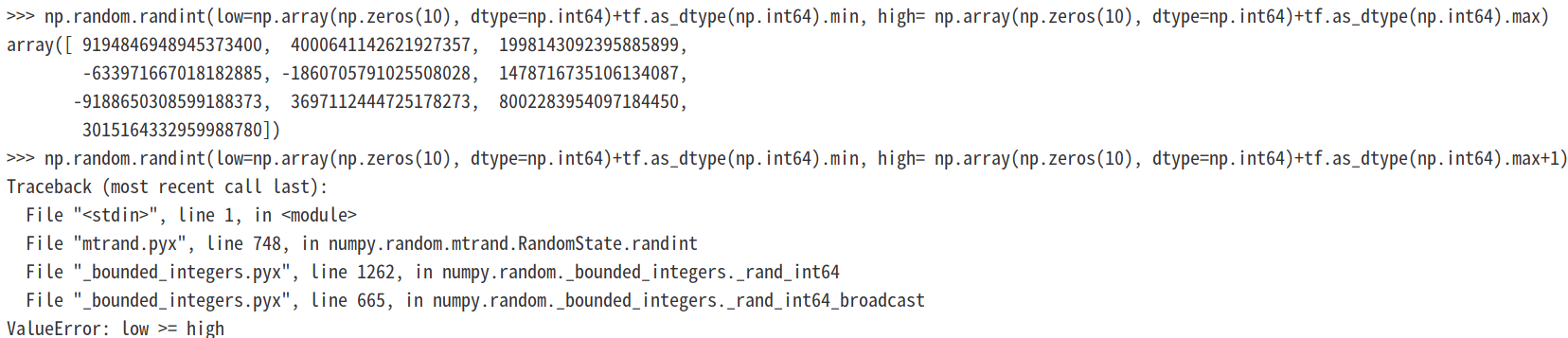
可以看到在使用numpy.random.randint时对上下限还是要注意的,虽然numpy.random.randint对上限是开区间,但是+1操作是很可能引起溢出错误的。
这也就是为什么 high+1操作之前要做判断了,如下:

不过如果数据类型不为np.int64,并且也不为np.uint64,那么我们依然可以把high值转为np.int64后在+1 ,但是上面的逻辑判断是有一定问题的,这些修正后如下:

总的修改后的代码为:
def sample_bounded_spec(spec, rng):
"""Samples the given bounded spec. Args:
spec: A BoundedSpec to sample.
rng: A numpy RandomState to use for the sampling. Returns:
An np.array sample of the requested spec.
"""
tf_dtype = tf.as_dtype(spec.dtype)
low = spec.minimum
high = spec.maximum if tf_dtype.is_floating:
if spec.dtype == np.float64 and np.any(np.isinf(high - low)):
# The min-max interval cannot be represented by the np.float64. This is a
# problem only for np.float64, np.float32 works as expected.
# Spec bounds are set to read only so we can't use argumented assignment.
low = low / 2
high = high / 2
return rng.uniform(
low,
high,
size=spec.shape,
).astype(spec.dtype) else:
if spec.dtype == np.int64 and np.any(high - low < 0):
# The min-max interval cannot be represented by the tf_dtype. This is a
# problem only for int64.
low = low / 2
high = high / 2 if np.any(high < tf_dtype.max):
high = np.where(high < tf_dtype.max, high + 1, high)
elif spec.dtype != np.int64 and spec.dtype != np.uint64:
# We can still +1 the high if we cast it to the larger dtype.
high = high.astype(np.int64) + 1 if low.size == 1 and high.size == 1:
return rng.randint(
low,
high,
size=spec.shape,
dtype=spec.dtype,
)
else:
return np.reshape(
np.array([
rng.randint(low, high, size=1, dtype=spec.dtype)
for low, high in zip(low.flatten(), high.flatten())
]), spec.shape)
加入对np.uint64类型的判断:
def sample_bounded_spec(spec, rng):
"""Samples the given bounded spec. Args:
spec: A BoundedSpec to sample.
rng: A numpy RandomState to use for the sampling. Returns:
An np.array sample of the requested spec.
"""
tf_dtype = tf.as_dtype(spec.dtype)
low = spec.minimum
high = spec.maximum if tf_dtype.is_floating:
if spec.dtype == np.float64 and np.any(np.isinf(high - low)):
# The min-max interval cannot be represented by the np.float64. This is a
# problem only for np.float64, np.float32 works as expected.
# Spec bounds are set to read only so we can't use argumented assignment.
low = low / 2
high = high / 2
return rng.uniform(
low,
high,
size=spec.shape,
).astype(spec.dtype) else:
if spec.dtype == np.int64 and np.any(high - low < 0):
# The min-max interval cannot be represented by the tf_dtype. This is a
# problem only for int64.
low = low / 2
high = high / 2 if spec.dtype == np.uint64 and np.any(high >= np.iinfo(np.int64).max):
low = low / 2
high = high / 2 if np.any(high < tf_dtype.max):
high = np.where(high < tf_dtype.max, high + 1, high)
elif spec.dtype != np.int64 and spec.dtype != np.uint64:
# We can still +1 the high if we cast it to the larger dtype.
high = high.astype(np.int64) + 1 if low.size == 1 and high.size == 1:
return rng.randint(
low,
high,
size=spec.shape,
dtype=spec.dtype,
)
else:
return np.reshape(
np.array([
rng.randint(low, high, size=1, dtype=spec.dtype)
for low, high in zip(low.flatten(), high.flatten())
]), spec.shape)
===========================================
tf-agents框架的交互逻辑代码:
===========================================
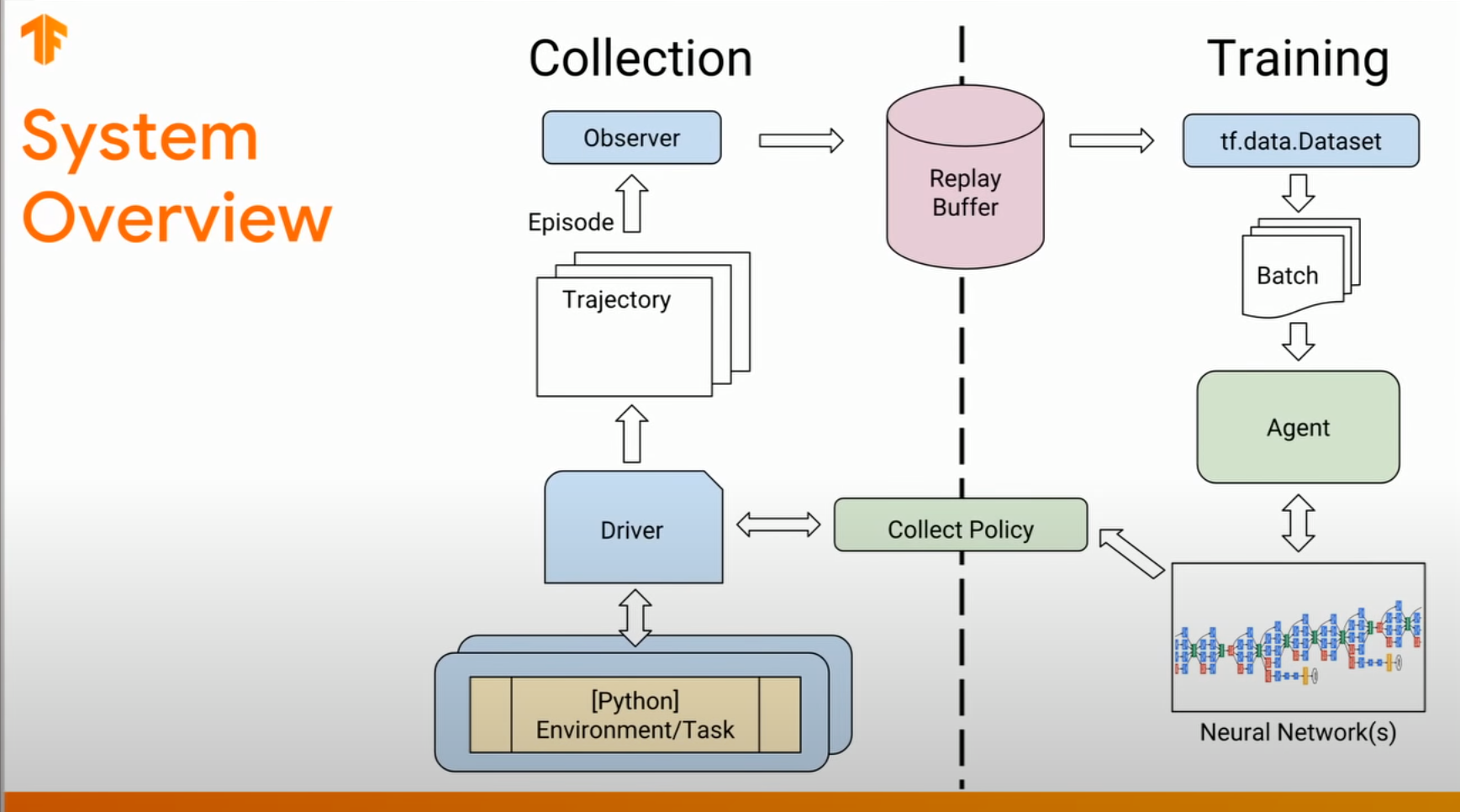






tensorflow的官方强化学习库agents的相关内容及一些注意事项的更多相关文章
- 学习笔记之html5相关内容
写一下昨天学习的html5的相关内容,首先谈下初次接触html5的感受.以前总是听说html5是如何的强大,如何的将要改变世界.总是充满了神秘感.首先来谈一下我接触的第一个属性是 input的里面的 ...
- 强化学习之四:基于策略的Agents (Policy-based Agents)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习之三:双臂赌博机(Two-armed Bandit)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- DQN 强化学习
pytorch比tenserflow简单. 所以我们模仿用tensorflow写的强化学习. 学习资料: 本节的全部代码 Tensorflow 的 100行 DQN 代码 我制作的 DQN 动画简介 ...
- 强化学习之七:Visualizing an Agent’s Thoughts and Actions
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习之六:Deep Q-Network and Beyond
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习之五:基于模型的强化学习(Model-based RL)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习之三点五:上下文赌博机(Contextual Bandits)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习之二:Q-Learning原理及表与神经网络的实现(Q-Learning with Tables and Neural Networks)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译.(This article is my personal translation for the tutor ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
随机推荐
- MySQL条件判断IF,CASE,IFNULL语句详解
MySQL条件判断IF,CASE,IFNULL语句详解 1.IF语句的基本用法IF(condition, true_statement, false_statement);condition: 条件表 ...
- Libgdx游戏开发(5)——碰撞反弹的简单实践
原文: Libgdx游戏开发(5)--碰撞反弹的简单实践-Stars-One的杂货小窝 本篇简单以一个小球运动,一步步实现碰撞反弹的效果 本文代码示例以kotlin为主,且需要有一定的Libgdx入门 ...
- Python优雅遍历字典删除元素的方法
在Python中,直接遍历字典并在遍历过程中删除元素可能会导致运行时错误,因为字典在迭代时并不支持修改其大小.但是,我们可以通过一些方法间接地达到这个目的. 1.方法一:字典推导式创建新字典(推荐) ...
- Nginx配置以及热升级
目录 Nginx详解 1. Nginx关键特性 2. Nginx配置 2.1 event 2.2 http 2.2.1 log_format 2.2.2 sendfile 2.2.3 tcp_nopu ...
- 2.SpringBoot快速上手
2.SpringBoot快速上手 SpringBoot介绍 javaEE的开发经常会涉及到3个框架Spring ,SpringMVC,MyBatis.但是这三个框架配置极其繁琐,有大量的xml文件,s ...
- 推荐常用的Idea插件
Idea常用快捷键 删除所有空行 使用替换 Ctrl + R 点亮后面的魔法图标启用正则表达式,输入:^\s*\n,然后选择替换全部 查询指定类或方法在哪里被引用 光标点中需要查找的类名和方法名,然后 ...
- 洛谷P1020
又是一道做的很麻的题,准确来说感觉这不是一道很好的dfs题,没有体现dfs的一些特点 反而感觉是在考察dp,刚开始也是按照我的思路交了3次都没过 原本以为所选的数应该都是由上一次的最大值推出来的,后面 ...
- 可视化—AntV G6实现节点连线及展开收缩分组
AntV 是蚂蚁金服全新一代数据可视化解决方案,主要包含数据驱动的高交互可视化图形语法G2,专注解决流程与关系分析的图表库 G6.适于对性能.体积.扩展性要求严苛的场景. demo使用数字模拟真实的节 ...
- [oeasy]python0111_字型码_字符字型编码_点阵字库_ascii演化
编码进化 回忆上次内容 上次回顾了 早期的英文字符点阵 最小的 3*5 通用的 5*7 点阵字库逐渐规范化 添加图片注释,不超过 140 字(可选) 这些点阵字符的字型 究竟是 ...
- PHP 程序员为什么依然是外包公司的香饽饽?
大家好,我是码农先森. PHP 唯一的爽点就是开发起来「哇真快」这刚好和外包公司的需求相契合,在 Web 领域的芒荒年代 PHP 以王者姿态傲视群雄.如果 PHP 敢说第二,就没有哪门子语言敢称第一, ...