tensorflow的官方强化学习库agents的相关内容及一些注意事项
源代码地址:
https://github.com/tensorflow/agents
TensorFlow给出的官方文档说明:
https://tensorflow.google.cn/agents
相关视频:
https://www.youtube.com/watch?v=U7g7-Jzj9qo
https://www.youtube.com/watch?v=tAOApRQAgpc
https://www.youtube.com/watch?v=52DTXidSVWc&list=PLQY2H8rRoyvxWE6bWx8XiMvyZFgg_25Q_&index=2
-----------------------------------------------------------
框架实现的算法:
论文1:
论文3:
论文4:
论文5:
论文6:
论文7:
论文8:
论文9:
论文10:
====================================
1. gym的环境版本有要求,给出具体安装及Atari的安装:
pip install gym[atari]==0.23.0
pip install gym[accept-rom-license]
=====================================
2. 代码的逻辑bug
tf_agents/specs/array_spec.py 代码bug:
def sample_bounded_spec(spec, rng):
"""Samples the given bounded spec. Args:
spec: A BoundedSpec to sample.
rng: A numpy RandomState to use for the sampling. Returns:
An np.array sample of the requested spec.
"""
tf_dtype = tf.as_dtype(spec.dtype)
low = spec.minimum
high = spec.maximum if tf_dtype.is_floating:
if spec.dtype == np.float64 and np.any(np.isinf(high - low)):
# The min-max interval cannot be represented by the np.float64. This is a
# problem only for np.float64, np.float32 works as expected.
# Spec bounds are set to read only so we can't use argumented assignment.
low = low / 2
high = high / 2
return rng.uniform(
low,
high,
size=spec.shape,
).astype(spec.dtype) else:
if spec.dtype == np.int64 and np.any(high - low < 0):
# The min-max interval cannot be represented by the tf_dtype. This is a
# problem only for int64.
low = low / 2
high = high / 2 if np.any(high < tf_dtype.max):
high = np.where(high < tf_dtype.max, high + 1, high)
elif spec.dtype != np.int64 or spec.dtype != np.uint64:
# We can still +1 the high if we cast it to the larger dtype.
high = high.astype(np.int64) + 1 if low.size == 1 and high.size == 1:
return rng.randint(
low,
high,
size=spec.shape,
dtype=spec.dtype,
)
else:
return np.reshape(
np.array([
rng.randint(low, high, size=1, dtype=spec.dtype)
for low, high in zip(low.flatten(), high.flatten())
]), spec.shape)
这个代码的意思就是在给定区间能进行均匀抽样,但是由于区间可能过大因此导致无法使用库函数抽样,因此需要对区间进行压缩。
当抽样的数据类型为np.float64时,由代码:
np.array(np.zeros(10), dtype=np.float64)+np.finfo(np.float64).max-np.finfo(np.float64).min

np.random.uniform(size=10, low=np.finfo(np.float64).min, high=np.finfo(np.float64).max)

可以知道,当类型为np.float64时,如果抽样区间过大会(超出数值表示范围)导致无法抽样,因此进行压缩区间:
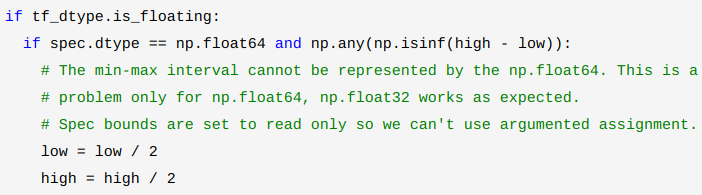
当数据类型为np.float32时,虽然也会存在超出表示范围的问题:
np.array(np.zeros(10), dtype=np.float32)+np.finfo(np.float32).max-np.finfo(np.float32).min

但是由于函数 np.random.uniform 的计算中会把np.float32转为np.float64,因此不会出现报错,如下:
np.random.uniform(size=10, low=np.finfo(np.float32).min, high=np.finfo(np.float32).max)

---------------------------------------------------
当数值类型为int时,区间访问过大的检测代码为:
np.any(high - low < 0)
原因在意np.float类型数值超出表示范围会表示为infi变量,但是int类型则会以溢出形式表现,如:

但是在使用numpy.random.randint 函数时,即使范围为最大范围也没有报错:
np.random.randint(size=10000, low=tf.as_dtype(np.int64).min, high=tf.as_dtype(np.int64).max)

np.random.randint(size=10000, low=np.iinfo(np.int64).min, high=np.iinfo(np.int64).max)

而且即使由于high值是取开区间的,我们对high值加1以后也没有报错:
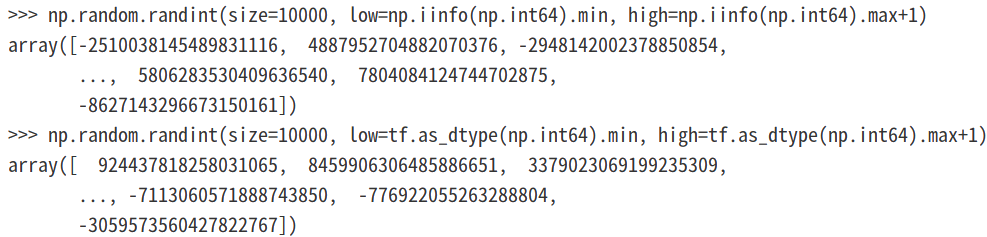
但是需要注意,此时传给np.random.randint函数中的low和high数值都为python数据类型int而不是numpy中的np.int64,下面我们看下numpy.float64类型是否会溢出:
当以数组形式传递最高high值并使其保持np.float64类型,发现使用high+1就会溢出:
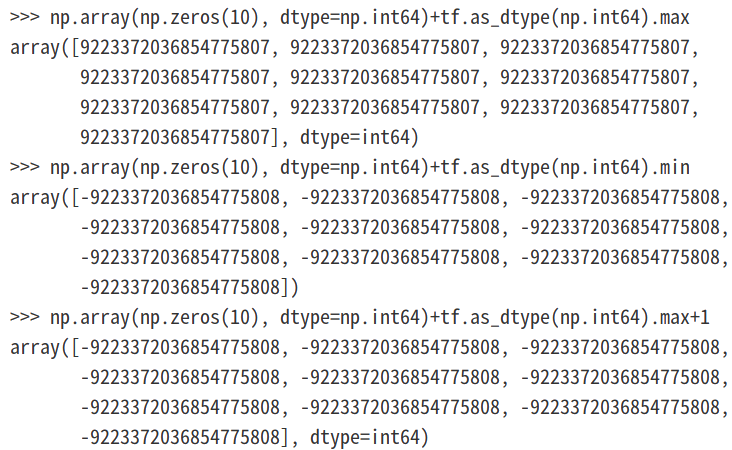
可以看到使用最大范围+1作为high值会导致报错:
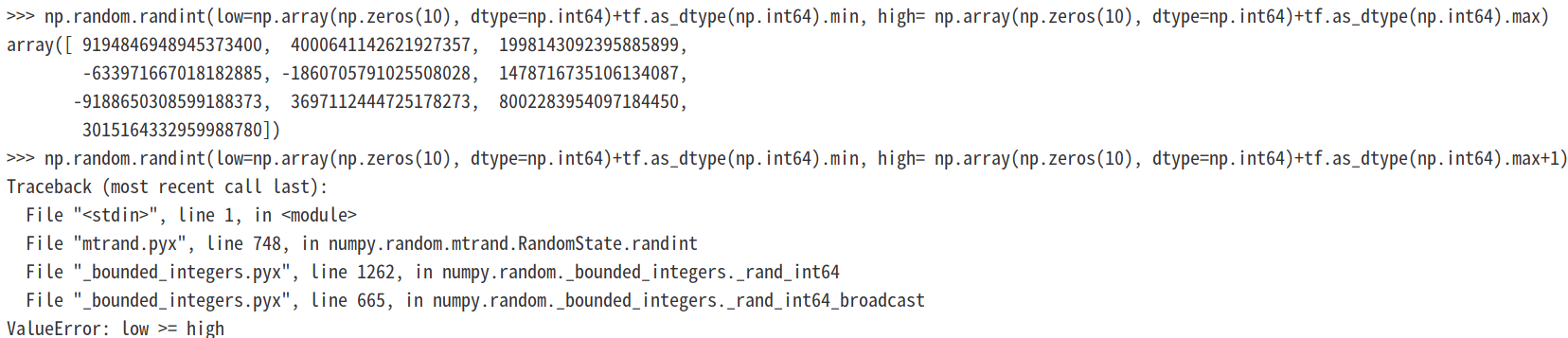
可以看到在使用numpy.random.randint时对上下限还是要注意的,虽然numpy.random.randint对上限是开区间,但是+1操作是很可能引起溢出错误的。
这也就是为什么 high+1操作之前要做判断了,如下:

不过如果数据类型不为np.int64,并且也不为np.uint64,那么我们依然可以把high值转为np.int64后在+1 ,但是上面的逻辑判断是有一定问题的,这些修正后如下:

总的修改后的代码为:
def sample_bounded_spec(spec, rng):
"""Samples the given bounded spec. Args:
spec: A BoundedSpec to sample.
rng: A numpy RandomState to use for the sampling. Returns:
An np.array sample of the requested spec.
"""
tf_dtype = tf.as_dtype(spec.dtype)
low = spec.minimum
high = spec.maximum if tf_dtype.is_floating:
if spec.dtype == np.float64 and np.any(np.isinf(high - low)):
# The min-max interval cannot be represented by the np.float64. This is a
# problem only for np.float64, np.float32 works as expected.
# Spec bounds are set to read only so we can't use argumented assignment.
low = low / 2
high = high / 2
return rng.uniform(
low,
high,
size=spec.shape,
).astype(spec.dtype) else:
if spec.dtype == np.int64 and np.any(high - low < 0):
# The min-max interval cannot be represented by the tf_dtype. This is a
# problem only for int64.
low = low / 2
high = high / 2 if np.any(high < tf_dtype.max):
high = np.where(high < tf_dtype.max, high + 1, high)
elif spec.dtype != np.int64 and spec.dtype != np.uint64:
# We can still +1 the high if we cast it to the larger dtype.
high = high.astype(np.int64) + 1 if low.size == 1 and high.size == 1:
return rng.randint(
low,
high,
size=spec.shape,
dtype=spec.dtype,
)
else:
return np.reshape(
np.array([
rng.randint(low, high, size=1, dtype=spec.dtype)
for low, high in zip(low.flatten(), high.flatten())
]), spec.shape)
加入对np.uint64类型的判断:
def sample_bounded_spec(spec, rng):
"""Samples the given bounded spec. Args:
spec: A BoundedSpec to sample.
rng: A numpy RandomState to use for the sampling. Returns:
An np.array sample of the requested spec.
"""
tf_dtype = tf.as_dtype(spec.dtype)
low = spec.minimum
high = spec.maximum if tf_dtype.is_floating:
if spec.dtype == np.float64 and np.any(np.isinf(high - low)):
# The min-max interval cannot be represented by the np.float64. This is a
# problem only for np.float64, np.float32 works as expected.
# Spec bounds are set to read only so we can't use argumented assignment.
low = low / 2
high = high / 2
return rng.uniform(
low,
high,
size=spec.shape,
).astype(spec.dtype) else:
if spec.dtype == np.int64 and np.any(high - low < 0):
# The min-max interval cannot be represented by the tf_dtype. This is a
# problem only for int64.
low = low / 2
high = high / 2 if spec.dtype == np.uint64 and np.any(high >= np.iinfo(np.int64).max):
low = low / 2
high = high / 2 if np.any(high < tf_dtype.max):
high = np.where(high < tf_dtype.max, high + 1, high)
elif spec.dtype != np.int64 and spec.dtype != np.uint64:
# We can still +1 the high if we cast it to the larger dtype.
high = high.astype(np.int64) + 1 if low.size == 1 and high.size == 1:
return rng.randint(
low,
high,
size=spec.shape,
dtype=spec.dtype,
)
else:
return np.reshape(
np.array([
rng.randint(low, high, size=1, dtype=spec.dtype)
for low, high in zip(low.flatten(), high.flatten())
]), spec.shape)
===========================================
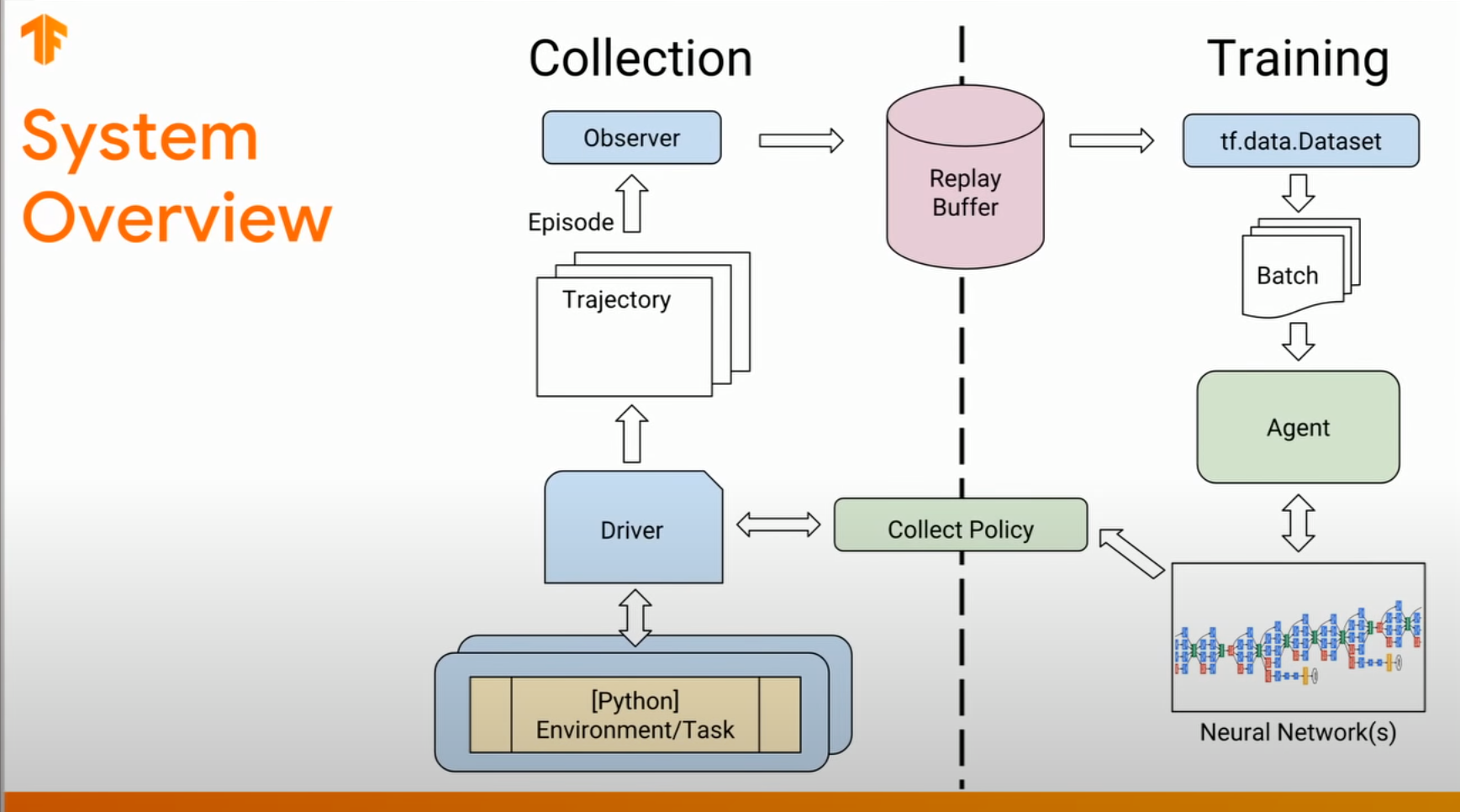
tf-agents框架的交互逻辑代码:
===========================================






tensorflow的官方强化学习库agents的相关内容及一些注意事项的更多相关文章
- 学习笔记之html5相关内容
写一下昨天学习的html5的相关内容,首先谈下初次接触html5的感受.以前总是听说html5是如何的强大,如何的将要改变世界.总是充满了神秘感.首先来谈一下我接触的第一个属性是 input的里面的 ...
- 强化学习之四:基于策略的Agents (Policy-based Agents)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习之三:双臂赌博机(Two-armed Bandit)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- DQN 强化学习
pytorch比tenserflow简单. 所以我们模仿用tensorflow写的强化学习. 学习资料: 本节的全部代码 Tensorflow 的 100行 DQN 代码 我制作的 DQN 动画简介 ...
- 强化学习之七:Visualizing an Agent’s Thoughts and Actions
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习之六:Deep Q-Network and Beyond
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习之五:基于模型的强化学习(Model-based RL)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习之三点五:上下文赌博机(Contextual Bandits)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习之二:Q-Learning原理及表与神经网络的实现(Q-Learning with Tables and Neural Networks)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译.(This article is my personal translation for the tutor ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
随机推荐
- work04
第一题: 分析以下需求,并用代码实现(每个小需求都需要封装成方法) 1.求两个数据之和(整数 小数),在main方法中打印出来 2.判断两个数据是否相等(整数 小数),在控制台上打印出来 3.获取两个 ...
- 以 ZGC 为例,谈一谈 JVM 是如何实现 Reference 语义的
本文基于 OpenJDK17 进行讨论 1. Reference 相关概念及其应用场景总览 Reference(引用)是 JVM 中非常核心且重要的一个概念,垃圾回收器判断一个对象存活与否都是围绕着这 ...
- 【译】向您介绍改版的 Visual Studio 资源管理器
随着最近 Visual Studio 的资源管理器的改进,开发人员将得到一种全新的享受!我们非常激动地宣布重新设计的 Visual Studio 资源管理器,相信我们,它将改变游戏规则. 在 Visu ...
- 【已结束】阿珏Blog三周年特别纪念活动
Tips:当你看到这个提示的时候,说明当前的文章是由原emlog博客系统搬迁至此的,文章发布时间已过于久远,编排和内容不一定完整,还请谅解` [已结束]阿珏Blog三周年特别纪念活动 日期:2019- ...
- Python中multiprocessing.Pool进程池实现守护进程的方法
前言 在multiprocessing.Process中可以使用p.daemon=True将子进程p设置为守护进程. 那么在multiprocessing.Pool进程池中怎么实现这个功能呢? 什么是 ...
- dotnet 融合 Avalonia 和 UNO 框架
现在在 .NET 系列里面,势头比较猛的 UI 框架中,就包括了 Avalonia 和 UNO 框架.本文将告诉大家如何尝试在一个解决方案里面融合 Avalonia 和 UNO 两个框架,即在一个进程 ...
- Nuxt3 的生命周期和钩子函数(五)
title: Nuxt3 的生命周期和钩子函数(五) date: 2024/6/29 updated: 2024/6/29 author: cmdragon excerpt: 摘要:本文详细介绍了Nu ...
- LaTeX 编辑协作平台 Overleaf 安装和使用教程
在学术界和科技行业,LaTeX 已成为撰写高质量文档的标准工具.然而,传统的 LaTeX 使用体验常常伴随着以下挑战: 学习曲线陡峭 环境配置复杂 多人协作困难 实时预览不便 当然,市面上不乏很多在线 ...
- python3 socket 获取域名信息
可以当ping用,应用场景可以在一些没有安装ping工具的镜像容器中,诊断dns或域名的可用性. #-*- coding:utf-8 -*- import socket import tracebac ...
- windows下使用dockerdesktop进行部署
Docker部署springboot项目 环境准备 要在windows上使用docker需要确认系统的需求 需要启用虚拟化支持的CPU 启用适用于windows的Linux子系统功能 保证足够的内存 ...