Transformers 中原生支持的量化方案概述
本文旨在对 transformers 支持的各种量化方案及其优缺点作一个清晰的概述,以助于读者进行方案选择。
目前,量化模型有两个主要的用途:
- 在较小的设备上进行大模型推理
- 对量化模型进行适配器微调
到目前为止,transformers 已经集成并 原生 支持了 bitsandbytes 和 auto-gptq 这两个量化库。请注意,optimum 还支持更多的量化方案,但本文不会涉及这一块内容。
要详细了解每种方案的更多信息,可查看下文列出的相关资源,或者阅读相应的 transformers 文档。
另请注意,下文内容仅适用于 PyTorch 模型, Tensorflow 和 Flax/JAX 模型不在讨论范围之内。
目录
资源
- GPTQ 博文 – 概述什么是 GPTQ 量化方法以及如何使用它。
- bistandbytes 4 比特量化博文 - 本文介绍了 4 比特量化和 QLoRa,QLoRa 是一种高效的微调方法。
- bistandbytes 8 比特量化博文 - 本文解释了如何与 bitsandbytes 配合使用 8 比特量化。
- 有关 GPTQ 基础用法的 Google Colab 笔记本 - 本笔记本展示了如何使用 GPTQ 方法量化你自己的 transformer 模型,如何用量化模型进行推理,以及如何对量化模型进行微调。
- 有关 bitsandbytes 基础用法的 Google Colab 笔记本 - 该笔记本展示了如何在推理中使用 4 比特模型及其所有变体,以及如何在免费的 Google Colab 实例上运行 GPT-neo-X (20B 模型)。
- Merve 撰写的关于量化的博文 - 本文简要介绍了量化以及 transformers 中原生支持的量化方法。
bitsandbytes 与 auto-gptq 之比较
本节我们将讨论 bitsandbytes 和 gptq 量化各自的优缺点。请注意,这些比较主要基于社区的反馈,它们具有一定的时效性,会随着时间的推移而变化,比如说其中一些功能缺失已被纳入相应库的路线图中了。
bitsandbytes 有什么好处?
简单: bitsandbytes 依旧是量化任何模型的最简单方法,因为它不需要量化校准数据及校准过程 (即零样本量化)。任何模型只要含有 torch.nn.Linear 模块,就可以对其进行开箱即用的量化。每当在 transformers 中添加新架构时,只要其可以用 accelerate 库的 device_map="auto" 加载,用户就可以直接受益于开箱即用的 bitsandbytes 量化,同时该方法对性能的影响也是最小的。量化是在模型加载时执行的,无需运行任何后处理或准备步骤。
跨模态互操作性: 由于量化模型的唯一条件是包含 torch.nn.Linear 层,因此量化对于任何模态都可以实现开箱即用。用户可以开箱即用地加载诸如 Whisper、ViT、Blip2 之类的 8 比特或 4 比特模型。
合并适配器 (adapter) 时性能下降为 0: (如果你对此不熟悉,请参阅 此文 以获得有关适配器和 PEFT 的更多信息)。如果你在量化基础模型之上训练适配器,则可以将适配器合并在基础模型之上进行部署,而不会降低推理性能。你甚至还可以在反量化模型之上 合并 适配器!GPTQ 不支持此功能。
autoGPTQ 有什么好处?
文本生成速度快: 对 文本生成 任务而言,GPTQ 量化模型的速度比 bitsandbytes 量化模型的速度更快,下文我们会详细比较。
n 比特支持: GPTQ 算法可以将模型量化至 2 比特!但这可能会导致严重的质量下降。我们建议使用 4 比特,这个值对 GPTQ 而言是个很好的折衷。
易于序列化: GPTQ 模型支持任意比特的序列化。只要安装了所需的软件包,就支持开箱即用地从 TheBloke 空间 中加载后缀为 -GPTQ 的模型。 bitsandbytes 支持 8 比特序列化,但尚不支持 4 比特序列化。
AMD 支持: 开箱即用支持 AMD GPU!
bitsandbytes 还有哪些潜在的改进空间?
文本生成速度比 GPTQ 慢: 使用 generate 接口时,bitsandbytes 4 比特模型比 GPTQ 慢。
4 比特权重不可序列化: 目前,4 比特模型无法序列化。社区用户经常提出这样的请求,我们相信 bitsandbytes 维护者应该很快就能解决这个问题,因为这已经在其路线图中了!
autoGPTQ 还有哪些潜在的改进空间?
校准数据集: 对校准数据集的需求可能会让一些用户难以用上 GPTQ。此外,模型量化可能需要几个小时 (例如,根据 该论文第 2 节,175B 的模型需要 4 个 GPU 时)。
目前仅可用于语言模型: 截至目前,用 autoGPTQ 对模型进行量化的 API 仅支持语言模型。使用 GPTQ 算法量化非文本 (或多模态) 模型应该是可行的,但原始论文或 auto-gptq 代码库中尚未对此有详细说明。如果社区对这方面很有兴趣,将来可能会考虑这一点。
深入研究速度基准
我们决定在不同硬件上使用 bitsandbytes 和 auto-gptq 在推理和适配器微调这两大场景上进行一系列广泛的基准测试。推理基准测试应该让用户了解不同推理方法之间可能存在的速度差异,而适配器微调基准测试应该让用户在需要决定选择 bitsandbytes 还是 GPTQ 基础模型进行适配器微调时有一个清晰的判断。
基本设置如下:
- bitsandbytes: 使用
bnb_4bit_compute_dtype=torch.float16进行 4 比特量化。确保使用bitsandbytes>=0.41.1,以用上 4 比特加速核函数。 - auto-gptq: 确保
auto-gptq>=0.4.0以用上exllama加速核函数进行 4 比特量化。
推理速度 (仅前向)
该基准测试仅测量预填充 (prefill) 步骤,该步骤对应于训练期间的前向传递。测试基于单张英伟达 A100-SXM4-80GB GPU,提示长度为 512,模型为 meta-llama/Llama-2-13b-hf 。
batch size = 1 时:
| 量化方法 | act_order | 比特数 | group_size | 加速核 | 加载时间 (秒) | 每词元延迟 (毫秒) | 吞吐 (词元/秒) | 峰值显存 (MB) |
|---|---|---|---|---|---|---|---|---|
| fp16 | None | None | None | None | 26.0 | 36.958 | 27.058 | 29152.98 |
| gptq | False | 4 | 128 | exllama | 36.2 | 33.711 | 29.663 | 10484.34 |
| bitsandbytes | None | 4 | None | None | 37.64 | 52.00 | 19.23 | 11018.36 |
batch size = 16 时:
| 量化方法 | act_order | 比特数 | group_size | 加速核 | 加载时间 (秒) | 每词元延迟 (毫秒) | 吞吐 (词元/秒) | 峰值显存 (MB) |
|---|---|---|---|---|---|---|---|---|
| fp16 | None | None | None | None | 26.0 | 69.94 | 228.76 | 53986.51 |
| gptq | False | 4 | 128 | exllama | 36.2 | 95.41 | 167.68 | 34777.04 |
| bitsandbytes | None | 4 | None | None | 37.64 | 113.98 | 140.38 | 35532.37 |
我们可以看到,bitsandbyes 和 GPTQ 的预填充速度相当,batch size 比较大时 GPTQ 稍快一些。欲了解有关该基准测试的更多详细信息,请参阅此 链接。
生成速度
下面测试推理过程中模型的生成速度,你可以在 此处 找到基准测试脚本,用于重现我们的结果。
use_cache
我们先测试 use_cache 参数的影响,以更好地了解在生成过程中键值缓存对速度的影响。
该基准测试在 A100 上运行,提示长度为 30,生成词元数也为 30,模型为 meta-llama/Llama-2-7b-hf 。
use_cache=True 时:
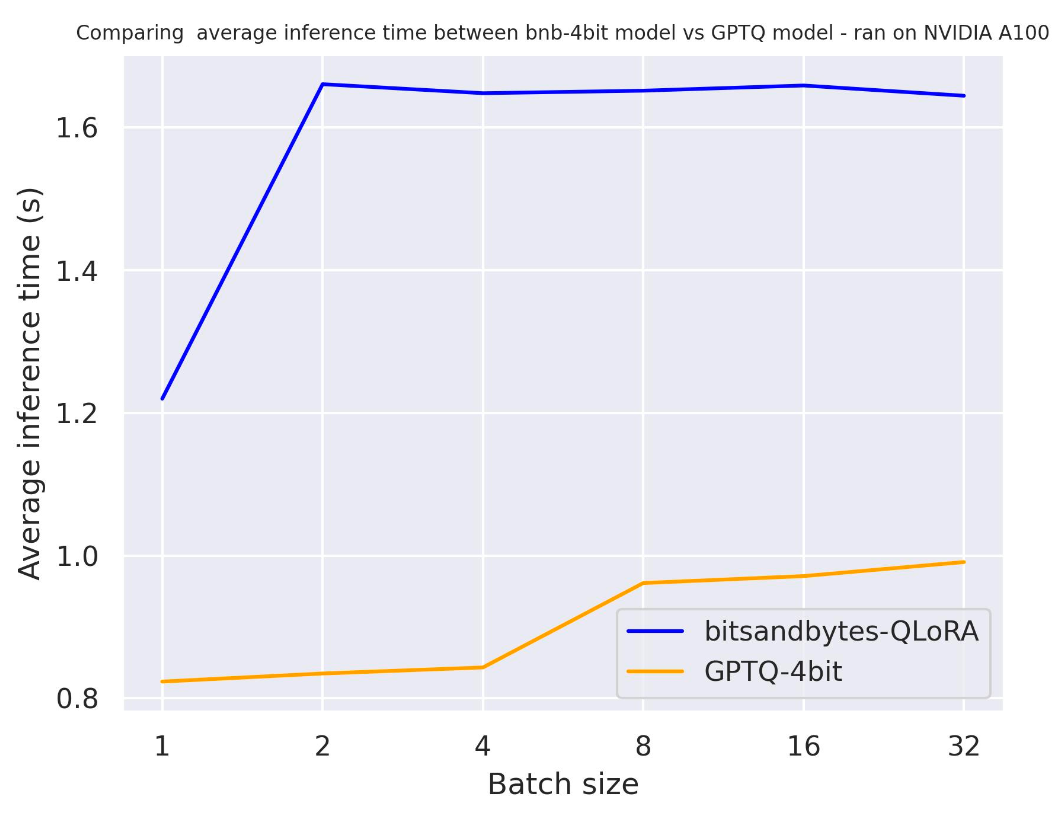
use_cache=False 时:
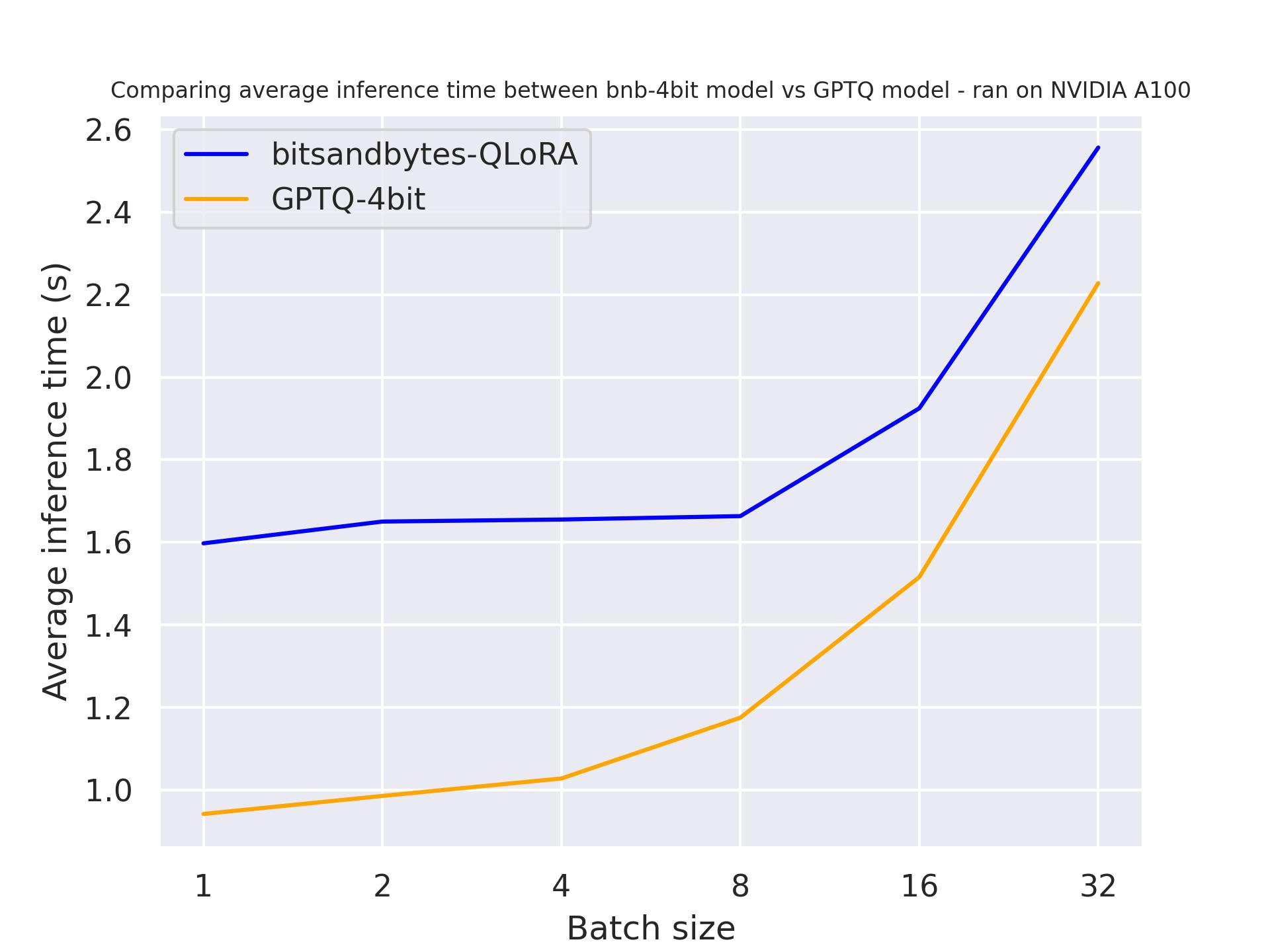
通过这两个基准测试,可以得出结论,使用注意力缓存时,生成速度会更快,该结论符合预期。此外,一般来说,GPTQ 比 bitsandbytes 更快。例如, batch_size=4 且 use_cache=True 时,GPTQ 速度快了一倍!因此,我们下一个基准测试中会直接使用 use_cache=True 。请注意, use_cache=True 会消耗更多显存。
硬件
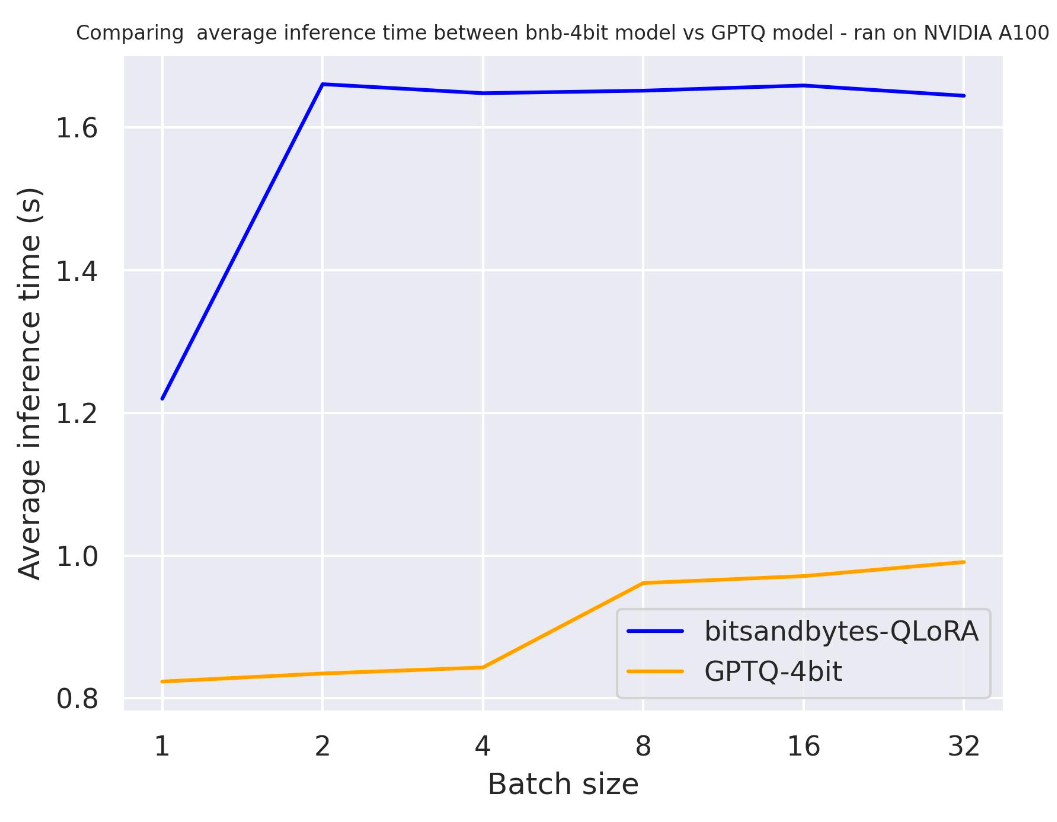
下面,我们看看量化模型在不同的硬件上的表现。我们使用的提示长度为 30,生成 30 个词元,使用的模型是 meta-llama/Llama-2-7b-hf 。
单张 A100:
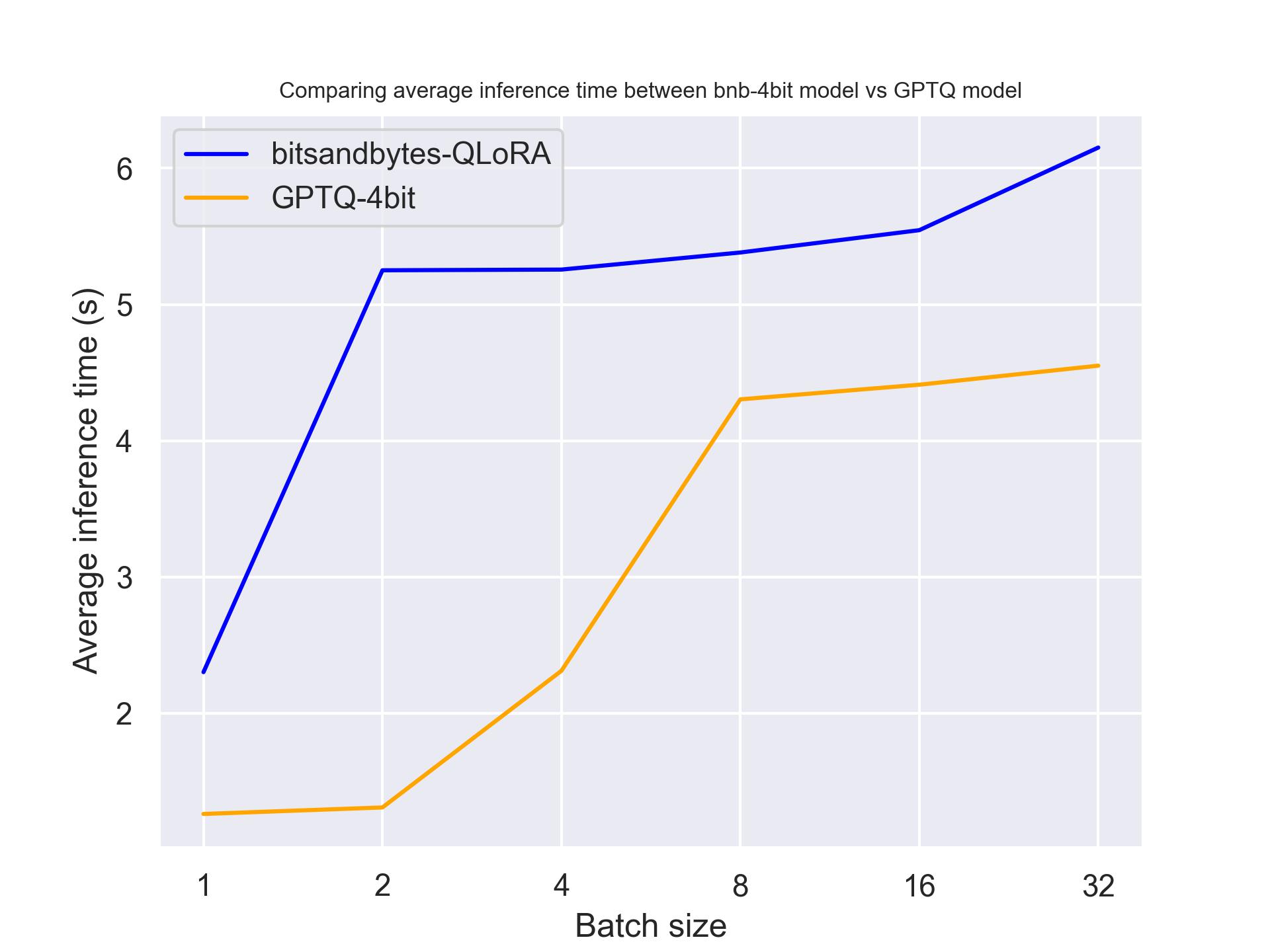
单张 T4:
单张 Titan RTX:
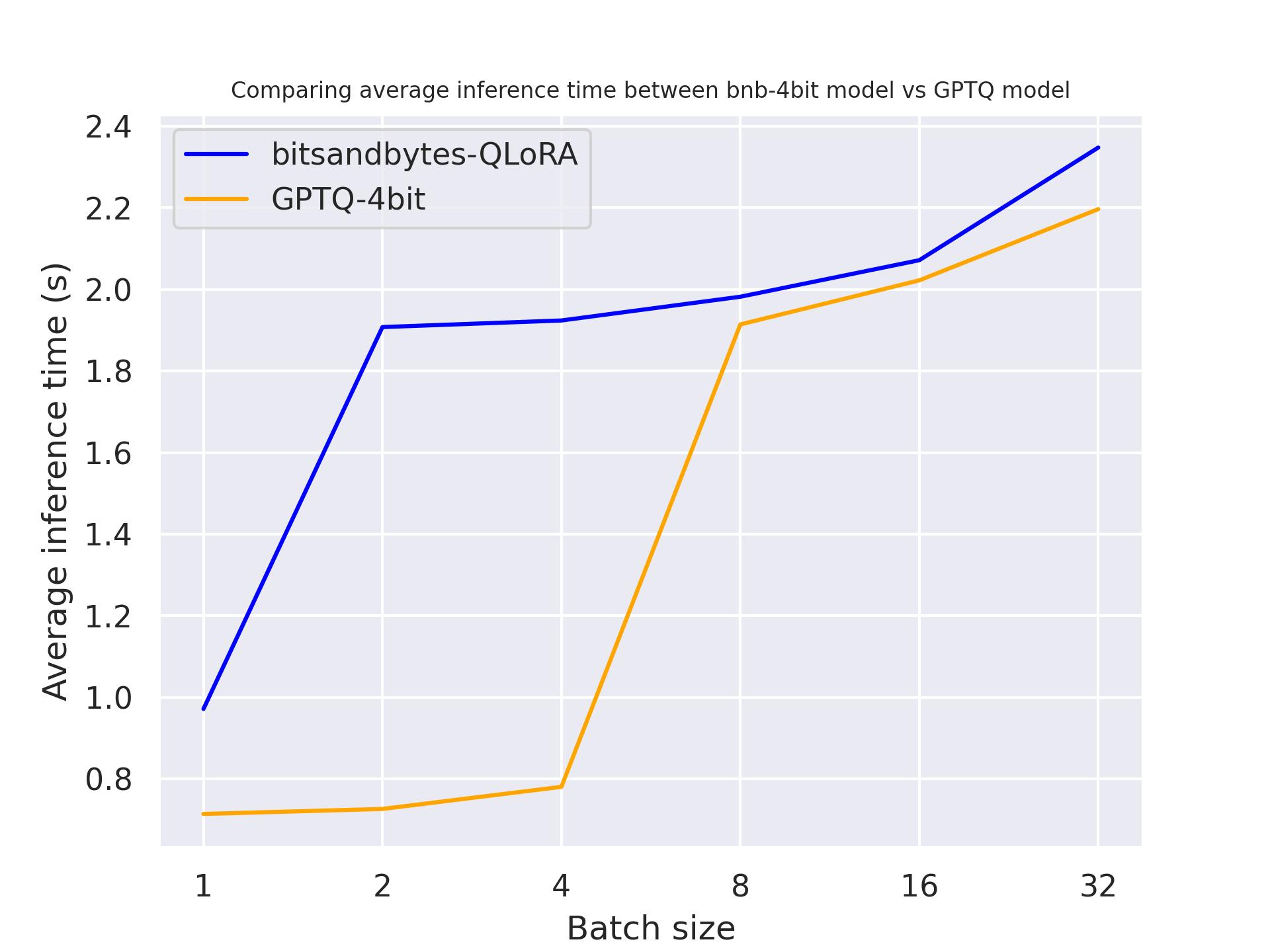
从上面的基准测试中,我们可以得出结论,对于这三款 GPU,GPTQ 都比 bitsandbytes 更快。
生成长度
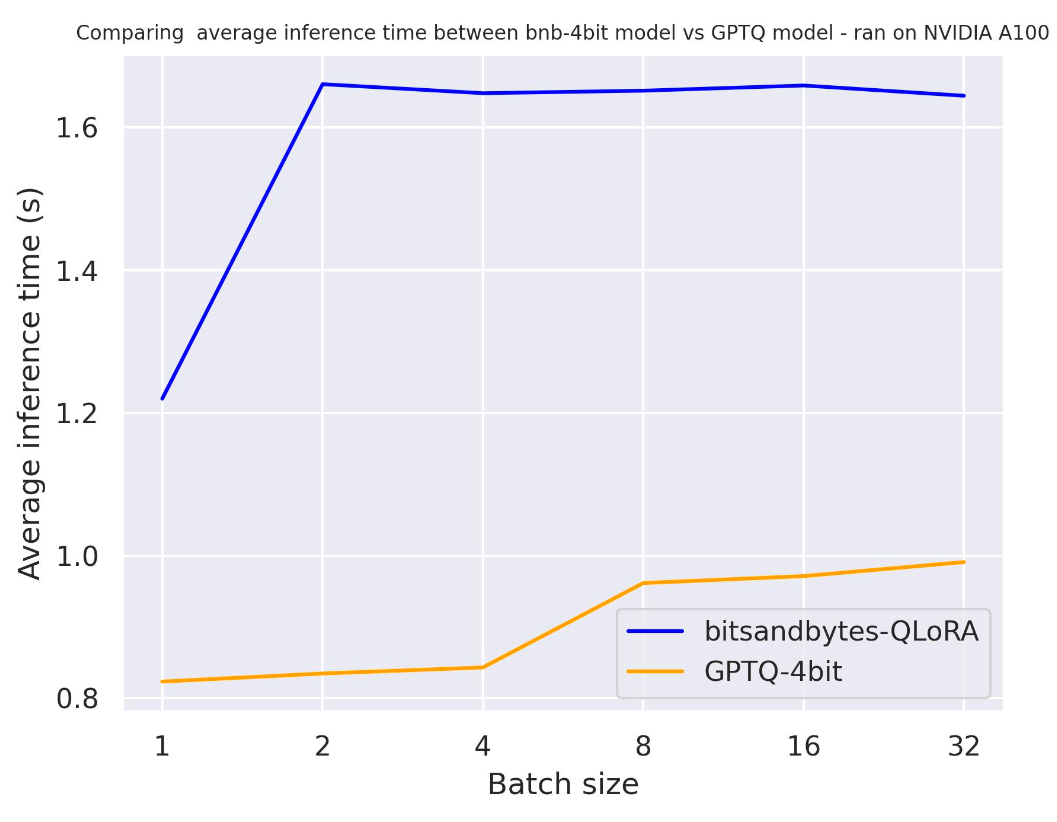
在下面的基准测试中,我们将尝试不同的生成长度,看看它们对量化模型速度的影响。实验基于 A100,我们使用的提示长度为 30,并改变生成词元的长度。使用的模型是 meta-llama/Llama-2-7b-hf 。
生成 30 个词元:
生成 512 个词元:
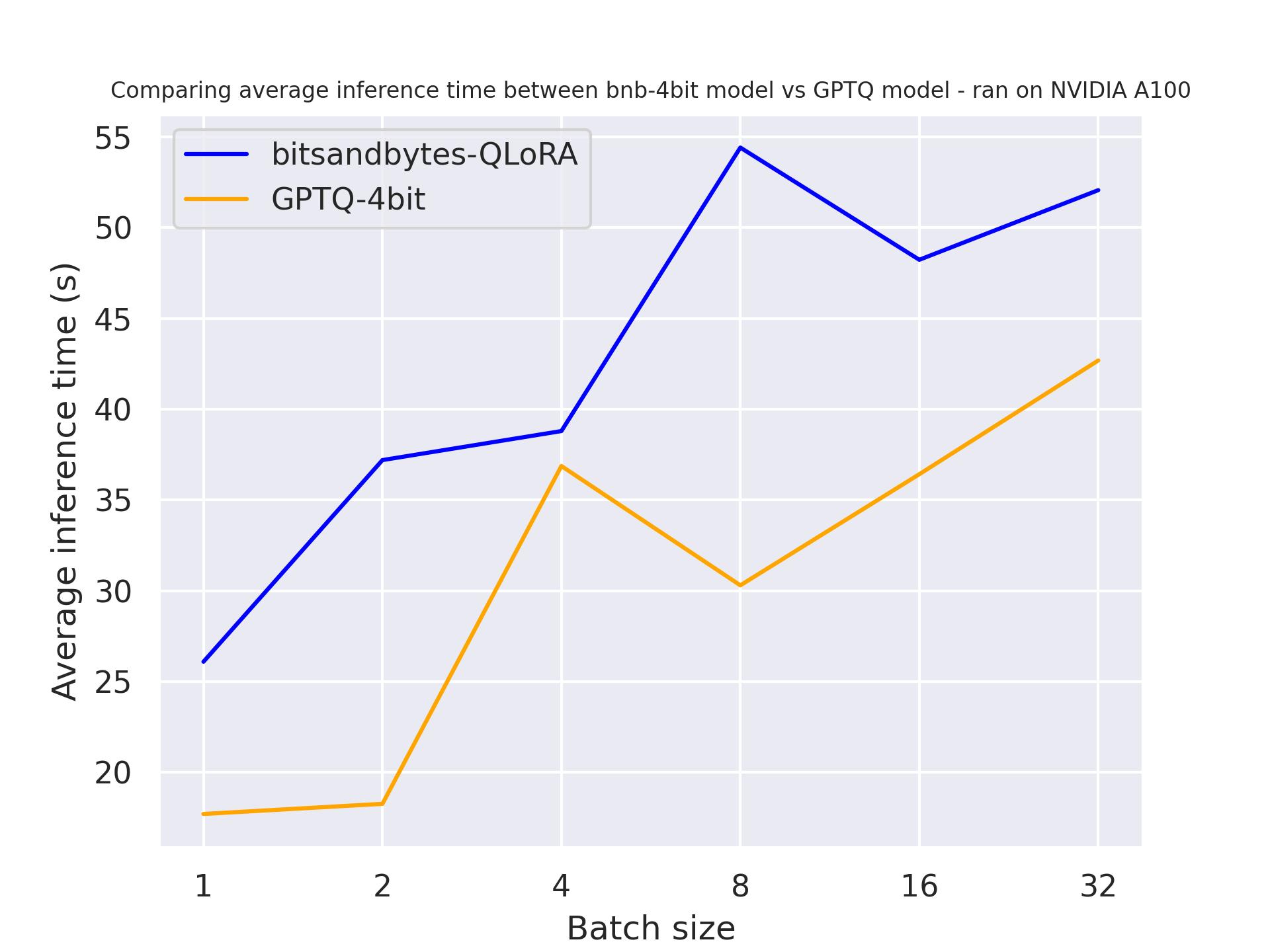
从以上基准测试中,我们可以得出结论,无论生成长度如何,GPTQ 都比 bitsandbytes 更快。
适配器微调 (前向 + 后向)
对量化模型进行全模型微调是不可能的。但是,你可以利用参数高效微调 (PEFT) 来微调量化模型,在其之上训练新的适配器。我们使用一种名为“低秩适配器 (LoRA)”的微调方法: 无需微调整个模型,仅需微调这些适配器并将它们正确加载到模型中。我们来对比一下微调速度吧!
该基准测试基于英伟达 A100 GPU,我们使用 Hub 中的 meta-llama/Llama-2-7b-hf 模型。请注意,对于 GPTQ 模型,我们必须禁用 exllama 加速核,因为它不支持微调。
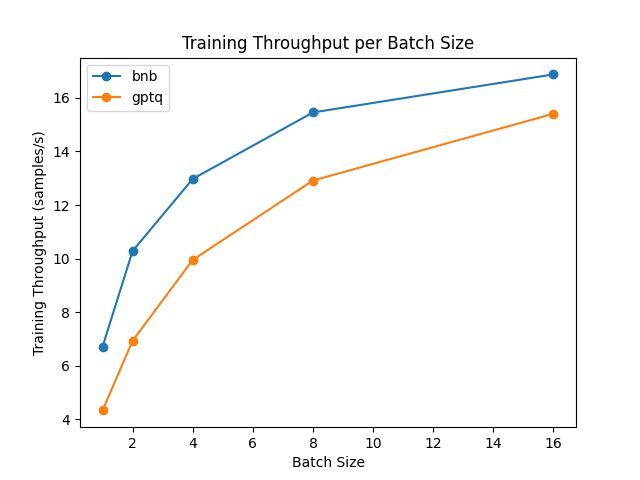
从结果中,我们可以得出结论,bitsandbytes 的微调速度比 GPTQ 更快。
性能退化
量化对于减少内存消耗非常有用。然而,它也会带来性能退化。我们使用 Open-LLM 排行榜 来比较性能!
对于 7B 模型:
| 模型 | 均值 | ARC | Hellaswag | MMLU | TruthfulQA |
|---|---|---|---|---|---|
| meta-llama/llama-2-7b-hf | 54.32 | 53.07 | 78.59 | 46.87 | 38.76 |
| meta-llama/llama-2-7b-hf-bnb-4bit | 53.4 | 53.07 | 77.74 | 43.8 | 38.98 |
| TheBloke/Llama-2-7B-GPTQ | 53.23 | 52.05 | 77.59 | 43.99 | 39.32 |
对于 13B 模型:
| 模型 | 均值 | ARC | Hellaswag | MMLU | TruthfulQA |
|---|---|---|---|---|---|
| meta-llama/llama-2-13b-hf | 58.66 | 59.39 | 82.13 | 55.74 | 37.38 |
| TheBloke/Llama-2-13B-GPTQ (revision = 'gptq-4bit-128g-actorder_True') | 58.03 | 59.13 | 81.48 | 54.45 | 37.07 |
| TheBloke/Llama-2-13B-GPTQ | 57.56 | 57.25 | 81.66 | 54.81 | 36.56 |
| meta-llama/llama-2-13b-hf-bnb-4bit | 56.9 | 58.11 | 80.97 | 54.34 | 34.17 |
从上面的结果中,我们可以得出结论,模型越大,退化越少。更有意思的是,所有的退化都很小!
总结与最后的话
通过本文,我们比较了多种设置下的 bitsandbytes 和 GPTQ 量化。我们发现,bitsandbytes 更适合微调,而 GPTQ 更适合生成。根据这一观察,获得最佳合并模型的一种方法是:
- (1) 使用 bitsandbytes 量化基础模型 (零样本量化)
- (2) 添加并微调适配器
- (3) 将训练后的适配器合并到基础模型或 反量化模型 之中!
- (4) 使用 GPTQ 量化合并后的模型并将其用于部署
我们希望这个概述让每个人都能更轻松地将 LLM 应用至各自的应用场景中,我们期待看到大家用它构建自己的有趣应用!
致谢
我们要感谢 Ilyas、Clémentine 和 Felix 在基准测试上的帮助。
我们还要感谢 Pedro Cuenca 对本文撰写的帮助。
英文原文: https://hf.co/blog/overview-quantization-transformers
原文作者: Younes Belkada,Marc Sun,Ilyas Moutawwakil,Clémentine Fourrier,Félix Marty
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理
审校/排版: zhongdongy (阿东)
Transformers 中原生支持的量化方案概述的更多相关文章
- 在Azure DevOps Server(TFS系统)中部署回退/回滚方案(Rollback)
概述 Azure DevOps Server(之前名TFS)是微软公司实现软件研发.测试和部署一体化的全流程解决方案.在近几年的研发过程中,Azure DevOps Server 大幅增强了软件部署过 ...
- (5.1)mysql高可用系列——高可用架构方案概述
关键词:mysql高可用概述,mysql高可用架构 常用高可用方案 20190918 现在业内常用的MySQL高可用方案有哪些?目前来说,用的比较多的开源方案分内置高可用与外部实现,内置高可用有如下: ...
- SQL Server 2016 JSON原生支持实例说明
背景 Microsoft SQL Server 对于数据平台的开发者来说越来越友好.比如已经原生支持XML很多年了,在这个趋势下,如今也能在SQLServer2016中使用内置的JSON.尤其对于一些 ...
- nginx配置pathinfo支持,最佳方案 - chunyu
〇. 前言 pathinfo有两个,1 pathinfo()函数,2 $_SERVER['PATH_INFO'].pathinfo()是php的库函数,原生支持不需要nginx配置,$_SERVER[ ...
- SQL Server 2016原生支持JSON
转载原地址: http://www.cnblogs.com/lyhabc/p/4747694.html SQL Server 2005 开始支持 XML 数据类型,提供原生的 XML数据类型.XML ...
- 刨根究底字符编码之八——Unicode编码方案概述
Unicode编码方案概述 1. 前面讲过,随着计算机发展到世界各地,于是各个国家和地区各自为政,搞出了很多既兼容ASCII但又互相不兼容的各种编码方案.这样一来同一个二进制编码就有可能被解释成不 ...
- [转帖]银河麒麟Kydroid 2.0全新发布:原生支持海量安卓APP
银河麒麟Kydroid 2.0全新发布:原生支持海量安卓APP https://news.cnblogs.com/n/652299/将手机操作系统 转移到 桌面 跟chromebook 类似的策略吧 ...
- Hybrid App中原生页面 VS H5页面
Hybrid App中原生页面 VS H5页面 现有3类主流APP,分别为:Web App.Hybrid App(混合模式移动应用,Hybrid有"混合的"意思). Nativ ...
- 根据JavaScript中原生的XMLHttpRequest实现jQuery的Ajax
基本介绍 XmlHttpRequest XmlHttpRequest是JavaScript中原生的,历史悠久的一种发送网络请求的方案. 基本上所有前端框架对于网络请求的部分都是基于它来完成的. 在本章 ...
- SQL Server2016 原生支持JSON
SQL Server2016 原生支持JSON SQL Server 2005 开始支持 XML 数据类型,提供原生的 XML数据类型.XML 索引以及各种管理 XML 或输出 XML 格式的函数. ...
随机推荐
- 如何配置Linux的互信
如何配置Linux的互信? 这里针对的是root用户的,普通用户家目录/home/test/.ssh. 1.在客户端生成公钥私钥对 [root@auto1 ~]# ssh-keygen -t rsa ...
- AcWing 4797. 移动棋子题解
算出数值为 \(1\) 的点离 \((3, 3)\) 的距离即可. #include <iostream> #include <cstring> #include <al ...
- 华为ensp配置静态路由,三路由,三pc
华为ensp配置静态路由 目的:使pc1,pc2,pc3能相互ping通 1,tuop图的搭建 1,如图所示:先搭建好设备的通讯关系,在标记好每台设备对应的,ip地址和网关. 2,pc的网关,与ip地 ...
- iostat命令安装及详解
iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视.它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况.同vmstat一样,i ...
- Day11:KMP、字典树、AC自动机、后缀数组、manacher
KMP算法 前言 KMP算法是一个著名的字符串匹配算法,效率很高,但是确实有点复杂. 简介 KMP 算法是 D.E.Knuth.J,H,Morris 和 V.R.Pratt 三位神人共同提出的,称之为 ...
- 记一次Android项目升级Kotlin版本(1.5 -> 1.7)
原文地址: 记一次Android项目升级Kotlin版本(1.5 -> 1.7) - Stars-One的杂货小窝 由于自己的历史项目Kotlin版本比较老了,之前已经升级过一次了(1.4-&g ...
- [PWN之路]堆攻击那些事儿
原文:https://www.freebuf.com/articles/endpoint/371095.html 0x00 前言 根据某大佬所说,pwn之路分为栈,堆,和内核.当前,如果你看到这个文章 ...
- 三维模型OSGB格式轻量化压缩点云处理技术探讨
三维模型OSGB格式轻量化压缩点云处理技术探讨 点云是一种常用的三维模型表示方法,由于其具有高精度.高保真度.易处理等优点,因此在很多领域都得到了广泛应用.但是,点云数据的存储量通常比较大,为了使点云 ...
- 算法笔记_python
目录 算法 概念 时间复杂度 空间复杂度 递归原理 顺序查找 二分查找 列表排序 LowB 三人组 冒泡排序 选择排序 插入排序 NB三人组 快速排序 堆排序 归并排序 NB三人组小结 总结 其他排序 ...
- MATLAB入门小操作(数据类型)
这是一篇有助于快速上手MATLAB软件的文章(新手向).(学习过其他的语言更容易看懂) 数据类型 这篇文章我想从MATLAB中的数据类型出发去列举一些经常使用的操作.MATLAB中的数据类型包括其他语 ...