spark 中怎么像 pandas 里面对时间数据做 resample
1. 笨办法
pandas Dataframe 可以很容易做时序数据的 resample,按照一定的frequency 聚合数据. 但是spark 中因为没有顺序的概念就不太好做,下面是怎么在spark中做resample 的例子.
def resample(column, agg_interval=900, time_format='yyyy-MM-dd HH:mm:ss'):
if type(column)==str:
column = F.col(column) # Convert the timestamp to unix timestamp format.
# Unix timestamp = number of seconds since 00:00:00 UTC, 1 January 1970.
col_ut = F.unix_timestamp(column, format=time_format) # Divide the time into dicrete intervals, by rounding.
col_ut_agg = F.floor(col_ut / agg_interval) * agg_interval # Convert to and return a human readable timestamp
return F.from_unixtime(col_ut_agg) df = df.withColumn('dt_resampled', resample(df.dt, agg_interval=3600)) # 1h resample
df.show()
2. 新办法
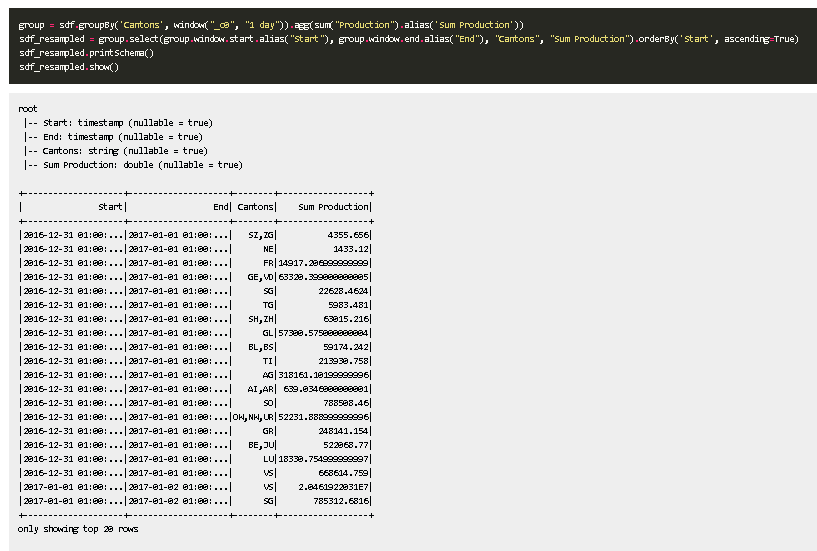
使用 groupby + window
Ref:
https://mihevc.org/2016/09/28/spark-resampling.html 笨办法但是容易理解
https://rsandstroem.github.io/sparkdataframes.html#Resampling-time-series-with-Spark 新办法
spark 中怎么像 pandas 里面对时间数据做 resample的更多相关文章
- pandas将字段中的字符类型转化为时间类型,并设置为索引
假设目前已经引入了 pandas,同时也拥有 pandas 的 DataFrame 类型数据. import pandas as pd 数据集如下 df.head(3) date open close ...
- SPARK 中 DriverMemory和ExecutorMemory
spark中,不论spark-shell还是spark-submit,都可以设置memory大小,但是有的同学会发现有两个memory可以设置.分别是driver memory 和executor m ...
- 【原】Spark中Master源码分析(二)
继续上一篇的内容.上一篇的内容为: Spark中Master源码分析(一) http://www.cnblogs.com/yourarebest/p/5312965.html 4.receive方法, ...
- Spark中的Scheduler
Spark中的Scheduler scheduler分成两个类型.一个是TaskScheduler与事实上现,一个是DAGScheduler. TaskScheduler:主要负责各stage中传入的 ...
- Spark中的键值对操作-scala
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- Spark中的键值对操作
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- spark 中的RDD编程 -以下基于Java api
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- 【Spark篇】---Spark中控制算子
一.前述 Spark中控制算子也是懒执行的,需要Action算子触发才能执行,主要是为了对数据进行缓存. 控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化 ...
- 【原创】大叔问题定位分享(11)Spark中对大表子查询加limit为什么会报Broadcast超时错误
当两个表需要join时,如果一个是大表,一个是小表,正常的map-reduce流程需要shuffle,这会导致大表数据在节点间网络传输,常见的优化方式是将小表读到内存中并广播到大表处理,避免shuff ...
- Hanlp分词1.7版本在Spark中分布式使用记录
新发布1.7.0版本的hanlp自然语言处理工具包差不多已经有半年时间了,最近也是一直在整理这个新版本hanlp分词工具的相关内容.不过按照当前的整理进度,还需要一段时间再给大家详细分享整理的内容.昨 ...
随机推荐
- DarkHole_1靶机渗透流程
VulnHub_DarkHole1靶机渗透流程 注意:部署时,靶机的网络连接模式必须和kali一致,让靶机跟kali处于同一网段,这用kali才能扫出靶机的主机 1. 信息收集 1.1 探测IP 使用 ...
- AOP面向切面编程@Aspect 注解用法
AOP简介 AOP为Aspect Oriented Programming 的缩写,意为"面向切面编程",通过预编译方式和运行预期动态代理实现程序功能的统一维护的一种技术.AOP是 ...
- Profibus_DP转ModbusTCP网关模块接马保通讯案例
某工业企业为了提高生产效率和管理水平,决定对其生产线进行智能化改造.在该项目中,利用巴图自动化Profibus_DP转ModbusTCP网关模块(BT-ETHPB20)连接了不同生产设备,实现了设备之 ...
- [rCore学习笔记 02]Ubuntu 22虚拟机安装
写在前面 本随笔是非常菜的菜鸡写的.如有问题请及时提出. 可以联系:1160712160@qq.com GitHhub:https://github.com/WindDevil (目前啥也没有 Ubu ...
- lvs的nat和dr模式混合用
机器部署信息 lvs : 10.0.0.200 vip 10.0.0.19 外网IP , 172.168.1.19 内网IP dr rs: 10.0.0.200 vip 10.0.0.18 rip ...
- P10245 Swimming Pool题解
P10245 Swimming Pool 题意 给你四条边 \(abcd\),求这四条边是否可以组成梯形. 思路 这显然是一道简单的普通数学题. 判断是否能构成梯形只需看四条边是否能满足,上底减下底的 ...
- 从DDPM到DDIM(三) DDPM的训练与推理
从DDPM到DDIM(三) DDPM的训练与推理 前情回顾 首先还是回顾一下之前讨论的成果. 扩散模型的结构和各个概率模型的意义.下图展示了DDPM的双向马尔可夫模型. 其中\(\mathbf{x}_ ...
- 【NodeJS】操作MySQL
1.在连接的数据库中准备测试操作的表: CREATE TABLE `user` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID', `name` ...
- 【perl】01
1.环境搭建 -- 解释器 / 编译器 Perl 在 Window 平台上有 ActiveStatePerl 和 Strawberry Perl 编译器. ActiveState Perl和 Stra ...
- 【Zookeeper】01 概述 & 基础部署
背景: 随着互联网技术的发展,企业对计算机系统的计算,存储能力要求越来越高,各大IT企业都在追求高并发,海量存储的极致, 在这样的背景下,单纯依靠少量高性能单机来完成计算机,云计算的任务已经无法满足需 ...