【DL.AI】《Structuring Machine Learning Projects》笔记
一、改进模型的几个方法
- Collect more data
- Collect more diverse training set
- Train algorithm longer with gradient descent
- Try Adam instead of gradient descent
- Try bigger network
- Try dropout
- Add \(L_2\) regularization
- Network architecture
- Activation functions
- hidden units
二、Orthogonalization
定义:尽量使得因素之间正交,不互相影响,从而在对模型的某个方面进行优化时,不会影响到模型在其他方面的表现能力。
当你发现一个模型在dev数据集表现不好的时候,你可能会采取某些方法改进模型,但是采取的方法可能会同时影响到模型在其他数据集的表现。例如在dev数据集的表现变好了,但是却造成在test集的表现变差了,改变一个因素可能会同时影响到多个方面。因此,Orthogonalization便是想要使得每一个方法尽可能只影响到一个因素。
三、模型的评价指标
模型评价的标准有很多,例如accuracy、precision、recall等,但是这些标准往往是互相影响的,例如在precision的表现很好,但是在recall上的表现却一般般,因此很能通过这两个指标去评判哪一个模型才是更好的。因此在评价模型的时候,尽量采用单一的统一标准,例如F1 Score。在模型在多个维度的误差时,也尽量使用平均误差。当然,根据现实需求不同,每一个标准对模型的影响权重也不一样。因此,我们也可以根据实际需求,选择权重大的作为评判标准。例如,模型的预测精度和所需运行时间之间的权衡。
假如针对猫的分类器A和B的分类误差分别是3%和5%,但是分类器A可能会把色情内容为猫误分类然后推送给用户,而分类器B却不会。因此在这种情况下,分类器B是一个更好的选择。针对这种情况,我们可以在误差项的计算里加入色情图片的权重,如果输入x是色情图片,那么相对应的误差惩罚会大得多,以此来使得色情图片不被误分类为猫而推送给用户。

当模型在所定义的指标以及dev/test set上表现很好,但是在实际的应用中表现却一般般,此时应该修改模型的评价指标或则修改dev/test set。
四、train/dev/test sets的选择
- dev集和test集必需来自同样的分布,且最好能反映在未来的数据分布。而train集的分布可以允许和dev集、test集的分布不同(当然,分布能相同就尽可能得相同);
- 当数据集较小时(例如100、1000、10000),train集和test集的比例可以为7:3,或则train集与dev集、test集的比例为6:2:2;当数据集很大时(例如1000000),则train集:dev集:test集=9.8:0.1:0.1 。当然,在满足上述条件的前提下,应使得测试集尽可能得大以给与模型的表现能力更高的置信度。
五、human-level performance
- 当模型的表现超过human-level performance的时候,表现力的上升会慢慢减缓,但是决不可能超过Bayes optimal error。
- 人类在许多任务上已经可以达到很好的效果, 例如图片识别、语音识别等,如果模型的表现能力人类差时,可以考虑以下方法:
- Get labeled data from humans;
- Gain insight from manual error analysisi: Why did a persion get this right?
- Better analysis of bias / variance.
- 假设Training error为8%,Dev error为10%。当human-level performance(近似于Bayes error)为1%时,明显Training error距离human error还有着7%的差距,而距离Dev error只有2%的差距,因此在这种情况下,我们应该把模型的改进方案聚焦在偏差上,而不是方差;而当hu man-level performance为7.5%的时候,Training error距离human error只有0.5%的差距,而距离Dev error有2%的差距,因此此时我们应该聚焦在方差的改进,而不是偏差。

六、Error Analysis
- 检查在DEV集里被误分类的类别是什么、被误分类的原因是燊,并分析各自所占比重,再决定把精力花在解决哪个问题上面;
- 在数据集中,可能存在有一些数据集的标签是错误的。因此我们应该查看DEV集,确定是分类器的预测错误,还是由于数据集的标签错误;
- 当然被模型正确分类的数据集,也可能存在标签是错误的情况,但是此时你的模型却“正确分类”,这种情况也要考虑。但是一般情况所花费的精力会很多,所以对这种情况进行处理的一般较少;
- 在修正错误的标签集时,确保对dev集和test集同时操作,以保证数据分布的一致性;
七. 训练集和测试集的分布不一致
1. 分布不一致的来源以及数据集划分方法
例:在猫分类器中,所用的训练数据来自于网上,这些图片的质量很非常好,但是这个分类器实际应用是在移动App上,而在移动App上,用户所拍摄的猫的图片往往质量没那么好,因此在训练集上表现很好的分类器,在实际应用中可能就表现很一般。且来自于网上的图片集量级A往往很大,例如1000000,而来自于用户所拍摄的图片集B可能只有10000。针对这种情况,有以下几种可能的解决方案:
- 将10000的数据集B加入1000000的数据集A中,然后打乱再重新按照98:1:1的比例分为train/dev/test,但是在这种处理下,很大可能dev和test所包含的数据集大部分来自于A,只有少部分来自于B,这跟设置dev集合的目的是相违背的。dev集和test集的数据分布应当与实际应用中的数据分布尽可能得一致——即与数据集B的分布一致,这样训练出来的模型才能在实际应用中表现很好。
- 训练集包含所有的数据集A和部分的数据集B,然后将剩下的数据集B划分为dev集和test集。虽然在这种情况下训练集和dev集、测试集的数据不一致,但是实际的表现效果会优于方案1。
2. 如何判定dev集合误差过高的原因
当训练集和验证机/测试集的分布不一致时,可以将训练集的一小部分抽取出来作为train-dev set,至此,整个数据集包含train、train-dev、dev、test四个集合,作用如下:
train set:用于模型训练
train-dev set:具有和train set相同的数据分布,但不用于模型训练,只用于误差测定
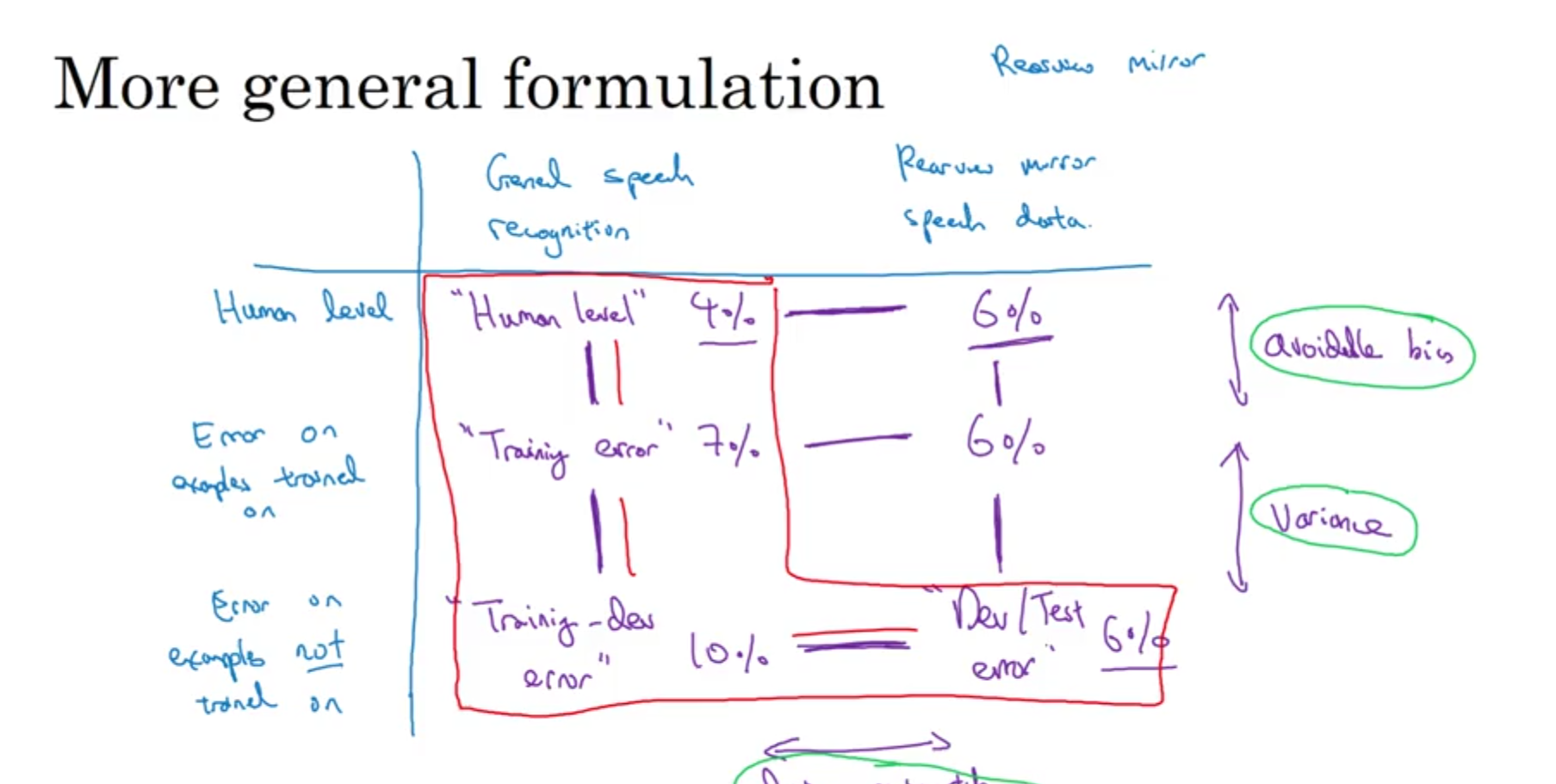
若train-dev set的误差与dev set的误差相近,但比train set的误差高许多时,说明这是一个偏差问题;若若train-dev set的误差与train set的误差相近,但dev set的误差却比train-dev set的误差高许多时,说明这是一个由于训练集和验证集的数据分布不一致所造成的问题。

3. 通过数据集之间的误差关系分析问题
假设训练误差为1%,验证误差为10%,如果训练集和验证机/测试集的数据分布一致,则说明这是一个高方差问题;但如果和上述例子类似,训练集和测试集的分布不一致的话,误差产生的原因可能只是因为训练集的图片质量较好分类器容易分辨,而验证集的图片质量普通从而导致分类器无法正确分类,造成了较大的验证误差。

4. 解决数据不匹配的方法
- 进行人工错误分析,发掘数据不匹配的缘由。通过分析train集和dev集之间的区别,尝试得到更多和dev集分布累计的train集;
- 采用人工数据合成的方法。比如在汽车内的语音识别系统,训练集为在安静环境下录制的10000小时的语音数据,但是实际的应用中,汽车内的语音识别系统的输入语音数据是包含的噪音的,比如汽车发送声、周围车辆的喇叭声、汽车内的回响等等。因此,假如你的拥有一小时的汽车噪音数据,为了train集和dev集尽可能得一致,可以通过人工数据合成的方法,把这一小时的噪音数据和10000小时的在安静环境下录制的语音数据进行合成,当然这有可能使得系统对这一小时的噪音数据过拟合。另外一个解决方法是录制10000小时的噪音数据,当然这个方法所耗费的精力会比较大。
八、Learning from multiple tasks
1. Transfer learning
- pre-training和fine tune: 在深度神经网络训练中,使用先前已经训练好的模型的参数来作为初始化的模型参数,这便是pre-training;在之后的训练中更新模型的参数,这便是fine tuning;
- 迁移学习即把从一个数据集A学到的知识应用到另一个数据集B中。但是假如数据集A的量级比数据集B小,此时对B应用迁移学习并不是一个明智的做法,因为数据集A能给数据集B所提供的信息是很少的。此时应当对数据集B重新训练一个模型。
2. Muti-task learning
- 定义:给定一个输入,可以同时对输入进行多个方面的判断。例如给定在自动驾驶中,给定一个图像,然后同时判断这个图像里是否有人行道、停止标志、骑车、红绿灯等。Y标签通常为[0, 1, 1, 0,......, 1],其中 1 表示这副图像用于这个属性。
- 多分类学习与Muti-task learning的概念有点类似,但是多分类学习(如softmax、SVM)是指对一个输入,判定属于多个分类中的其中一个类别,例如给定一个动物图像,判定属于猫/狗/猪。在多分类学习下,Y标签通常为[0, 1, 2, 3, .....m],其中m - 1为类别数。
- 在Muti-task learning中,训练集的Y标签是否存在某个属性有时是不确定的。例如给定一副图像,Y标签只告诉你这副图像有红绿灯和汽车,但对于是否有人行道、停止标志是不确定的,这些属性在Y标签被对应打上 ? 号。因此,在计算损失函数时,这些属性未确定的损失是不计算进去的,只计算Y标签中已经指明为 0 或 1 的位置。
- Muti-task learning只有在网络深度较大时的表现情况才比较好。因为深度神经网络可以学习到图像的某些低维特征,这些特征可以用来共享以同时进行多任务的学习。
- 对于需要对一个输入同时进行判定的问题,一个做法就是Muti-task learning,另一个就是针对每一个类别学习一个分类器。在每个类别的样本数据较少时,采用Muti-task learning是比较明智的做法,这样可以更好得学习到图像的特征;而当每个类别的样本数据都很多时,可以采用多分类模型,这样模型预测的准确度一般会较高;
3. End-to-end learning
- 当数据集足够大的时候,end-to-end leraning才适用。
Pros:
- Let the data speak. 在非End-to-end的模型中,常常人为得为模型定义一系列的网络层,这些网络层可以提取输入数据的某些特征,例如图像结构或则语音数据的发音等,但是这些提取出来的信息都是人为给定的,而在end-to-end模型中,直接学习从输入到输出的映射,可能可以发现数据里面更深层次潜在的特征信息;
- Less hand-designing of components needed.
Cons:
- May need large amount of data;
- Excludes potentially useful hand-designed compoents.
【DL.AI】《Structuring Machine Learning Projects》笔记的更多相关文章
- Structuring Machine Learning Projects 笔记
1 Machine Learning strategy 1.1 为什么有机器学习调节策略 当你的机器学习系统的性能不佳时,你会想到许多改进的方法.但是选择错误的方向进行改进,会使你花费大量的时间,但是 ...
- 《Structuring Machine Learning Projects》课堂笔记
Lesson 3 Structuring Machine Learning Projects 这篇文章其实是 Coursera 上吴恩达老师的深度学习专业课程的第三门课程的课程笔记. 参考了其他人的笔 ...
- [C5] Andrew Ng - Structuring Machine Learning Projects
About this Course You will learn how to build a successful machine learning project. If you aspire t ...
- 课程三(Structuring Machine Learning Projects),第一周(ML strategy(1)) —— 0.Learning Goals
Learning Goals Understand why Machine Learning strategy is important Apply satisficing and optimizin ...
- 课程三(Structuring Machine Learning Projects),第一周(ML strategy(1)) —— 1.Machine learning Flight simulator:Bird recognition in the city of Peacetopia (case study)
[]To help you practice strategies for machine learning, the following exercise will present an in-de ...
- 吴恩达《深度学习》-课后测验-第三门课 结构化机器学习项目(Structuring Machine Learning Projects)-Week1 Bird recognition in the city of Peacetopia (case study)( 和平之城中的鸟类识别(案例研究))
Week1 Bird recognition in the city of Peacetopia (case study)( 和平之城中的鸟类识别(案例研究)) 1.Problem Statement ...
- 吴恩达《深度学习》-第三门课 结构化机器学习项目(Structuring Machine Learning Projects)-第一周 机器学习(ML)策略(1)(ML strategy(1))-课程笔记
第一周 机器学习(ML)策略(1)(ML strategy(1)) 1.1 为什么是 ML 策略?(Why ML Strategy?) 希望在这门课程中,可以教给一些策略,一些分析机器学习问题的方法, ...
- 课程回顾-Structuring Machine Learning Projects
正交化 Orthogonalization单一评价指标保证训练.验证.测试的数据分布一致不同的错误错误分析数据分布不一致迁移学习 transfer learning多任务学习 Multi-task l ...
- [C3W2] Structuring Machine Learning Projects - ML Strategy 2
第二周:机器学习策略(2)(ML Strategy(2)) 误差分析(Carrying out error analysis) 你好,欢迎回来,如果你希望让学习算法能够胜任人类能做的任务,但你的学习算 ...
随机推荐
- centos配置静态ip地址
1.输入以下命令: vim /etc/sysconfig/network-scripts/ifcfg-eth0 2.注释掉BOOTPROTO=dhcp 3.添加如下内容: ONBOOT=yes 表示开 ...
- GoldData学习实例-采集官网新闻数据
概述 在本节中,我们将讲述抓取政府官网地方新闻.并将抓取的新闻数据融入到以下两张数据表news_site和news中. news_site(新闻来源) 字段 类型 说明 id bigint 主键,自动 ...
- re 模块错误 error: bad character range
下午,看到堆栈的内容.于是上机实验了一番 >>> bds = '10+6/5-4*2' # 数学运算表达式 想用 findall 把运算符号提取出来 >>> imp ...
- 【转载】COM 组件设计与应用(五)——用 ATL 写第一个组件
原文:http://vckbase.com/index.php/wv/1215.html 一.前言 1.如果你在使用 vc5.0 及以前的版本,请你升级为 vc6.0 或 vc.net 2003: 2 ...
- Linux常用文件权限控制命令
一,查看文件属主属组ls -l [root@localhost app]# ls -l total 302832 drwxr-xr-x. 4 lhc lhc 4096 Nov 18 16:05 apa ...
- 3-1 实现简单的shell sed替换功能
1.需求 程序1: 实现简单的shell sed替换功能 file1 的内容copy到file2 输入参数./sed.py $1 $2 $1替换成$2 (把a替换成% ) 2.个人思路 open ...
- doc2vec使用笔记
#!/usr/bin/env Python # coding:utf-8 #improt依赖包 # import sys # reload(sys) # sys.setdefaultencoding( ...
- Wannafly挑战赛25C 期望操作数
Wannafly挑战赛25C 期望操作数 简单题啦 \(f[i]=\frac{\sum_{j<=i}f[j]}{i}+1\) \(f[i]=\frac{f[i]}{i}+\frac{\sum_{ ...
- jstl c:if 不能判断成功的问题
这是因为test里不能直接用 ${value}=='字符串' 的方式来进行判断比较,所以只能这样写 ${value == '字符串'} ,这样就能判断了
- HTML3/CSS基础
1. HTML 1.1 什么是HTML HTML是用来制作网页的标记语言 HTML是Hypertext Markup Language的英文缩写,即超文本标记语言 HTML语言是一种标记语言,不需要编 ...