java基础43 IO流技术(输入字节流/缓冲输入字节流)
通过File对象可以读取文件或者文件夹的属性数据,如果要读取文件的内容数据,那么我们就要使用IO技术。
一、输入字节流
输入字节流的体系:
-------| InputStream:所有输入字节流的基类(抽象类)
-----------| FileInputStream:向指定文件读取数据的输入字节流
-----------| BufferedInputStream:缓冲输入字节流 注意:凡是缓冲流都不具备读写文件的能力
注意:所有缓冲流都不具备读写文件的能力(比如BufferedInputStream,他要借助FileInputStream的读功能来读文件)
1.1、IO流分类
按照数据的流向划分:
输入流:把硬盘(或内存)中的数据读到程序中。
输出流:把程序中的数据写到硬盘(或内存)中。
按照处理的单位划分:
字节流:字节流读取都是文件中的二进制数据,读取到的二进制数据不会经过任何的处理.
字符流:字符流读取的数据是以字符为单位的;字符流也是读取的是二进制数据,不过会把这些二进制数据转换为我们认识的字符.(字符流=字节流+解码)
1.2、输入流演示例子
步骤:
1、找到目标文件
2、建立数据的输入通道
3、读取文件中的数据(把硬盘中的数据读取到程序中)
4、关闭资源(注意:如果不关闭资源,该资源会一直占用CPU,且 当你要删除该文件时,将无法删除)
package com.dhb.file; import java.io.File;
import java.io.FileInputStream;
import java.io.IOException; /**
* @author DSHORE / 2018-7-2
*
*/
public class Demo9 {
public static void main(String[] args) throws IOException {
readTest3();
} //方式一: 缺陷:无法读取完整的一个文件的数据
public static void readTest1() throws IOException{
//找到目标文件
File f=new File("F:\\a.txt");
//建立数据的输入通道
FileInputStream fis=new FileInputStream(f);
//读取文件中的数据
int count=fis.read();//read():读取一个字节的数据,并返回读取到的数据
System.out.println("读取到的内容:"+(char)count);
fis.close();//关闭资源
} //方式二:使用循环读取文件的数据
public static void readTest2() throws IOException{
long start=System.currentTimeMillis();//计时(开始点),返回以毫秒为单位的当前时间
//找到目标文件
File file=new File("F:\\a.txt");
//建立数据输入通道
FileInputStream fis=new FileInputStream(file);
//读取文件中的数据
int countent=;//声明该变量用于存储读取到的数据
while((countent = fis.read()) != -){//-1表示:已经读到文件的末尾了,即:已读完所有数据
System.out.print((char)countent);
}
fis.close();//关闭资源
long end=System.currentTimeMillis();//计时(结束点),返回以毫秒为单位的当前时间
System.out.println();
System.out.println(end-start);//
} //方式三: 使用缓冲数组读取。 缺点:无法完整读取一个文件
public static void readTest3() throws IOException{
//找到目标文件
File f=new File("F:\\a.txt");
//建立数据的输入通道
FileInputStream fis=new FileInputStream(f);
//读取文件
byte[] buf=new byte[];
int length=fis.read(buf);
System.out.println("length:"+length);
//使用字符数组构建字符串
String s=new String(buf,,length);
System.out.println("文件中的内容:"+s);
fis.close();//关闭资源
} //方式四: 推荐使用(效率比方式二高)
public static void readTest4() throws IOException{
long start=System.currentTimeMillis();//计时(开始点),返回以毫秒为单位的当前时间
//找到目标文件
File f = new File("F:\\a.txt");
//建立数据输入通道
FileInputStream fis = new FileInputStream(f);
//读取文件
int length=;
byte[] buf=new byte[*];//存储读取到的数据 缓冲数组是1024的倍数,因为与计算机处理单位是一样的。//理论上缓冲数组越大,效率越高
while ((length = fis.read(buf)) != -) { //read()方法:如果读取到了文件的末尾,那么返回-1
System.out.println(new String(buf,,length));
}
//关闭资源
fis.close();
long end=System.currentTimeMillis(); //计时(结束点),返回以毫秒为单位的当前时间
System.out.println();
System.out.println(end-start);//67秒
}
}
1.3、实例
package com.dhb.file; import java.io.File;
import java.io.FileInputStream;
import java.io.IOException; /**
* @author DSHORE / 2018-7-2
*
*/
//需求:读取一张图片所需的时间
public class Demo8 {
public static void main(String[] args) throws IOException {
oppo();
} public static void oppo() throws IOException{
long start=System.currentTimeMillis();//开始(运行)时间;返回以毫秒为单位的当前时间
File file = new File("F:\\MyJavaCode\\20180702.jpg");
FileInputStream fir=new FileInputStream(file);//读取指定文件中的数据内容
int length = ;
byte[] buf = new byte[];
while((length=fir.read(buf)) != -){//read()方法:如果读取到了文件的末尾,那么返回-1
System.out.println(new String (buf,,length));//从0开始读,到length的最大长度结束
}
fir.close();//关闭资源
long end=System.currentTimeMillis();//结束(运行)时间;返回以毫秒为单位的当前时间
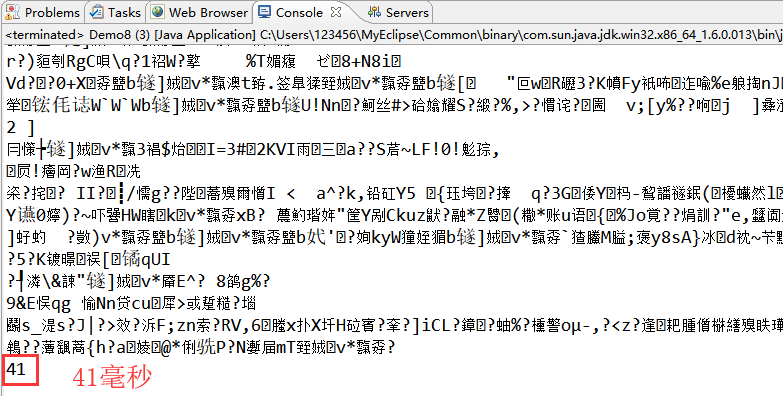
System.out.println(end-start);//返回值:41毫秒
}
}
运行结果图:
二、缓冲输入字节流
2.1、概述
我们清楚读取文件数据使用缓冲数组读取效率更高,sun公司给我们提供了一个缓冲输入字节流对象,让我们可以更高效率读取文件
注意:凡是缓冲流都不具备读写文件的能力,BufferedInputStream是借助FileInputStream的功能来进行读写操作的
2.2、使用BufferedInputStream的步骤
1.找到目标文件
2.建立数据的输入通道
3.建立缓冲输入字节流
4.读取数据(把硬盘中的数据读取到程序中)
5.关闭资源
2.3、实例
package com.dhb.file; import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException; /**
* @author DSHORE / 2018-7-4
*
*/
public class Demo1 {
public static void main(String[] args) throws IOException {
readTest();
}
public static void readTest() throws IOException{
//找到目标文件
File file=new File("F:\\a.txt");
FileInputStream fis=new FileInputStream(file);
BufferedInputStream bis=new BufferedInputStream(fis);
int length=;
//疑问:BufferInputStream出现的目的:提供读取文件的效率,但是BufferedInputStream和FileInputStream的read()方法每次读取一个字节的数据,那么BufferInputStream效率高从何而来?
//答:因为BufferInputStream内部维护了一个8kb的字节数组而已。(其实用 FileInputStream 的方式4和 BufferInputStream 的效率一样高,都差不多,自己喜欢哪种就用哪种)
while((length=bis.read())!=-){
System.out.print((char)length);
}
bis.close();//间接把fis关闭了
//fis.close();
}
}
|
原创作者:DSHORE 作者主页:http://www.cnblogs.com/dshore123/ 原文出自:https://www.cnblogs.com/dshore123/p/9253440.html 欢迎转载,转载务必说明出处。(如果本文对您有帮助,可以点击一下右下角的 推荐,或评论,谢谢!) |
java基础43 IO流技术(输入字节流/缓冲输入字节流)的更多相关文章
- java基础46 IO流技术(输出字符流/缓冲输出字符流)
一.输出字符流 1.1.输出字符流体系 --------| Writer:输出字符流的基类(抽象类) ----------| FileWriter:向文件输出数据输出字符流(把程序中的数据写到硬盘中 ...
- java基础44 IO流技术(输出字节流/缓冲输出字节流)和异常处理
一.输出字节流 输出字节流的体系: -------| OutputStream:所有输出字节流的基类(抽象类) ----------| FileOutputStream:向文件输出数据的输出字节流(把 ...
- java基础45 IO流技术(输入字符流/缓冲输入字符流)
一.输入字符流 1.1.输入字符流体系 ------| Reader:输入字符流的基类(抽象类) ----------| FileReader:向指定文件读取数据的输入字符流(把硬盘上的数据读取到程 ...
- java基础53 IO流技术(转换流)
1.转换流 1.输入字节的转换流:InputStreamReader是字节流转为字符流的桥梁,可以把输入字节流转换为输入字符流 2.输出字节流的转换流:OutputStreamWriter是字符 ...
- java基础48 IO流技术(序列流)
本文知识点目录: 1.SequenceInputStream序列流的步骤 2.实例 3.附录(音乐的切割与合并) 1.SequenceInputStream序列流的步骤 1.找到目标文件 ...
- java基础51 IO流技术(打印流)
1.打印流(printStream)的概念 打印流可以打印任意的数据类型 2.printStream的步骤 1.找到目标文件 2.创建一个打印流 3.打印信息 4.关闭资源 3.实例 ...
- java基础49 IO流技术(对象输入流/对象输出流)
1.对象输入输出流 对象注意作用是用于写对象信息与读取对象信息 1.对象输出流:ObjectOutputStream 2.对象输入流:ObjectInputStream 2.对象输入输出流的步骤 ...
- java基础之IO流(一)字节流
java基础之IO流(一)之字节流 IO流体系太大,涉及到的各种流对象,我觉得很有必要总结一下. 那什么是IO流,IO代表Input.Output,而流就是原始数据源与目标媒介的数据传输的一种抽象.典 ...
- java基础之IO流(二)之字符流
java基础之IO流(二)之字符流 字符流,顾名思义,它是以字符为数据处理单元的流对象,那么字符流和字节流之间的关系又是如何呢? 字符流可以理解为是字节流+字符编码集额一种封装与抽象,专门设计用来读写 ...
随机推荐
- Java EE之JSTL(下)
3.使用国际化和格式化标签库(FMT命名空间) 如果你希望创建部署在Web上,并面向庞大的国际化用户的企业级Java应用程序,那么你最终需要为世界的特定区域进行应用程序本地化.这将通过国际化实现(通常 ...
- 解题:ZJOI 2015 幻想乡战略游戏
题面 神**所有点都爆int,我还以为我写出什么大锅了,不开long long见祖宗... 动态点分治利用点分树树高不超过log的性质,我们对每个点维护一个子树和,一个点分树子树和,一个点分树上父亲的 ...
- 2017 3 8 练习赛 t3 路径规划
题目大意是让你在一棵树上找到一条路径使得(路径边权和*路径最小值) 最大. 这道题有两种方法. 1.点分治,考虑过重心的每条路径是否可能成为答案,枚举从根出发的每一条路径中的最小值等于总路径的最小值, ...
- fzyzojP3580 -- [校内训练-互测20180315]小基的高智商测试
题目还有一个条件是,x>y的y只会出现一次(每个数直接大于它的只有一个) n<=5000 是[HNOI2015]实验比较 的加强版 g(i,j,k)其实可以递推:g(i,j,k)=g(i- ...
- SenseTime Ace Coder Challenge 暨 商汤在线编程挑战赛 D. 白色相簿
从某一点开始,以层次遍历的方式建树若三点a.b.c互相连接,首先必先经过其中一点a,然后a可以拓展b.c两点,b.c两点的高度是相同的,若b(c)拓展时找到高度与之相同的点,则存在三点互相连接 //等 ...
- centos install python3 pip3
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-dev ...
- python学习(21) smtp发送邮件
原文链接: https://www.jianshu.com/p/369ec15bfe22 本文介绍python发送邮件模块smtplib以及相关MIME模块.smtplib用于生成邮件发送的代理,发送 ...
- 火狐,discuz同步登录问题解决
<script type="text/javascript" src="http://******/uc/api/uc.php?time=1503386589&am ...
- 科学计算三维可视化---Traits属性的监听
Traits属性的监听 HasTraits对象所有Traits属性都自动支持监听功能,当每个Traits属性发生变化时,HasTraits对象会通知监听此属性的函数 两种监听模式 静态监听 动态监听 ...
- 51 nod 1105 第K大的数
1105 第K大的数 基准时间限制:1 秒 空间限制:131072 KB 分值: 40 难度:4级算法题 收藏 关注 数组A和数组B,里面都有n个整数.数组C共有n^2个整数,分别是A[0] * ...