hadoop安装入门
1.jdk安装和配置
1.1下载最新jdk文件
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
1.2配置环境变量
vi /etc/profile
在文件末尾加入如下内容
JAVA_HOME=/usr/local/jdk
JAVA_CLASSPATH=$JAVA_HOME/lib
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME JAVA_CLASSPATH PATH
并使上面文件生效
source /etc/profile
java -version
2.hadoop安装
首先需要配置运行环境,在etc/hadoop/hadoop-env.sh文件中增加
export JAVA_HOME=/usr/local/hadoop
一、配置core-site.xml
/usr/local/hadoop/etc/hadoop/core-site.xml 包含了hadoop启动时的配置信息。
编辑器中打开此文件
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml

在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
保存、关闭编辑窗口。
最终修改后的文件内容如下:
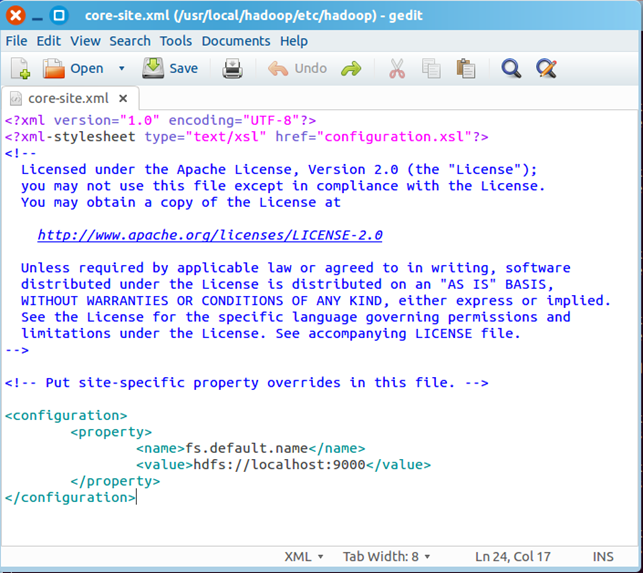
二、配置yarn-site.xml
/usr/local/hadoop/etc/hadoop/yarn-site.xml包含了MapReduce启动时的配置信息。
编辑器中打开此文件
sudo gedit yarn-site.xml

在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下
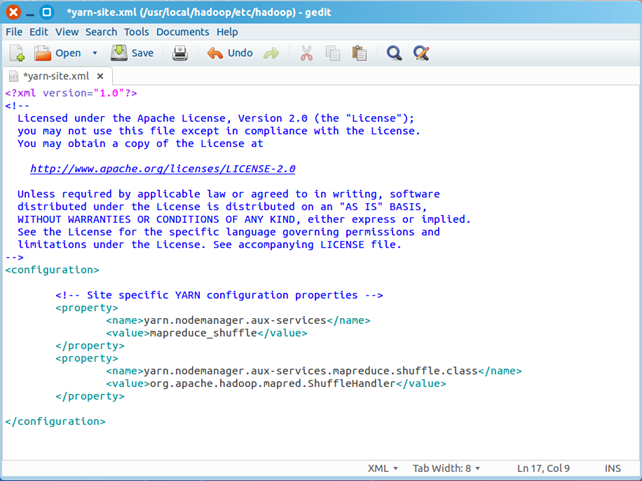
三、创建和配置mapred-site.xml
默认情况下,/usr/local/hadoop/etc/hadoop/文件夹下有mapred.xml.template文件,我们要复制该文件,并命名为mapred.xml,该文件用于指定MapReduce使用的框架。
复制并重命名
cp mapred-site.xml.template mapred-site.xml
编辑器打开此新建文件
sudo gedit mapred-site.xml

在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下
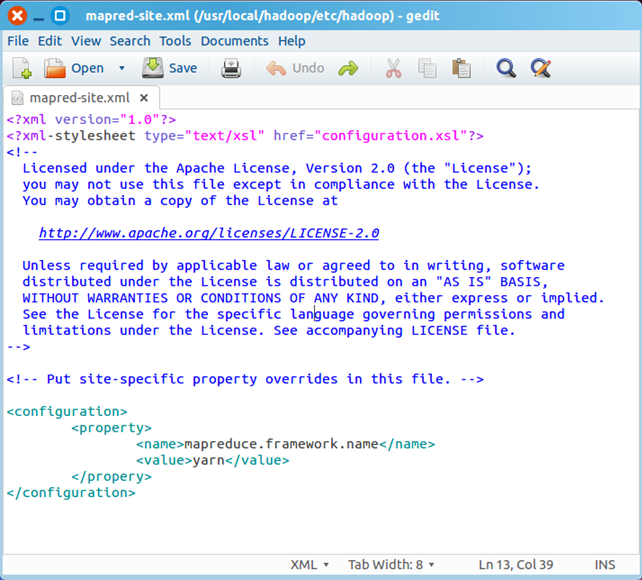
四、配置hdfs-site.xml
/usr/local/hadoop/etc/hadoop/hdfs-site.xml用来配置集群中每台主机都可用,指定主机上作为namenode和datanode的目录。
创建文件夹,如下图所示
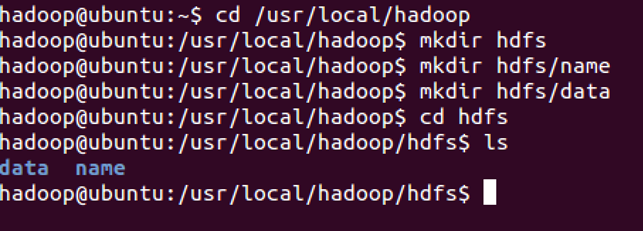
你也可以在别的路径下创建上图的文件夹,名称也可以与上图不同,但是需要和hdfs-site.xml中的配置一致。
编辑器打开hdfs-site.xml
在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下:
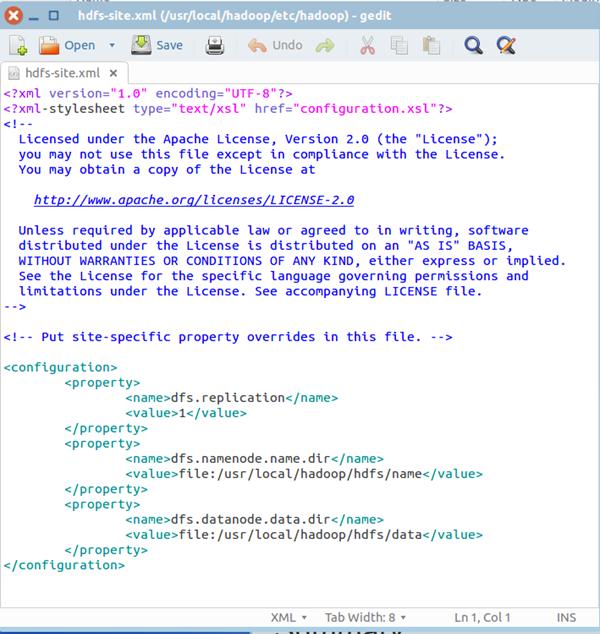
五、格式化hdfs
hdfs namenode -format
只需要执行一次即可,如果在hadoop已经使用后再次执行,会清除掉hdfs上的所有数据。
六、启动Hadoop
经过上文所描述配置和操作后,下面就可以启动这个单节点的集群
执行启动命令:
sbin/start-dfs.sh
执行该命令时,如果有yes /no提示,输入yes,回车即可。
接下来,执行:
sbin/start-yarn.sh
执行完这两个命令后,Hadoop会启动并运行
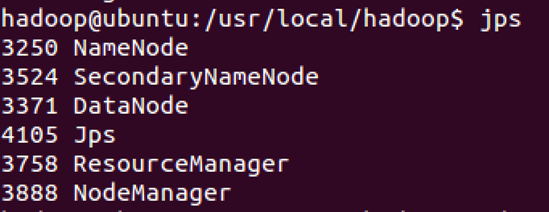
执行 jps命令,会看到Hadoop相关的进程,如下图:
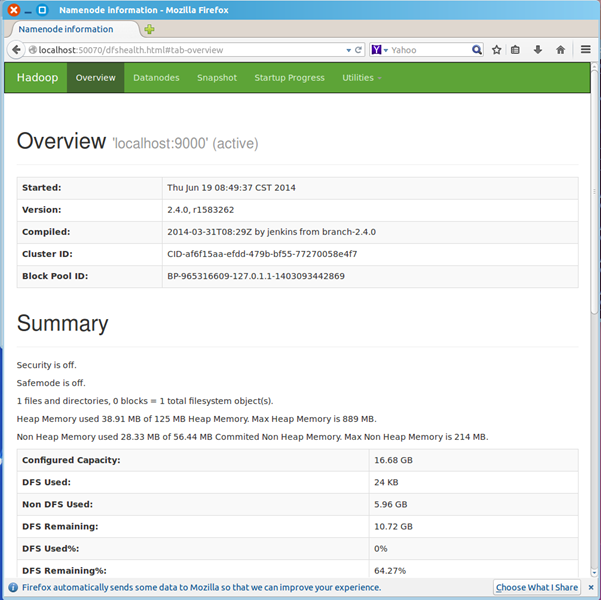
浏览器打开 http://localhost:50070/,会看到hdfs管理页面
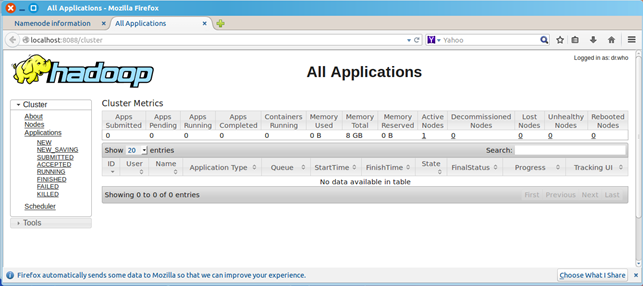
浏览器打开http://localhost:8088,会看到hadoop进程管理页面
七、WordCount验证
dfs上创建input目录
bin/hadoop fs -mkdir -p input

把hadoop目录下的README.txt拷贝到dfs新建的input里
hadoop fs -copyFromLocal README.txt input

运行WordCount
hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.4.0-sources.jar org.apache.hadoop.examples.WordCount input output

可以看到执行过程
运行完毕后,查看单词统计结果
hadoop fs -cat output/*

hadoop安装入门的更多相关文章
- 大数据入门:Hadoop安装、环境配置及检测
目录 1.导包Hadoop包 2.配置环境变量 3.把winutil包拷贝到Hadoop bin目录下 4.把Hadoop.dll放到system32下 5.检测Hadoop是否正常安装 5.1在ma ...
- [Hadoop入门] - 2 ubuntu安装与配置 hadoop安装与配置
ubuntu安装(这里我就不一一捉图了,只引用一个网址, 相信大家能力) ubuntu安装参考教程: http://jingyan.baidu.com/article/14bd256e0ca52eb ...
- Hadoop快速入门
目的 这篇文档的目的是帮助你快速完成单机上的Hadoop安装与使用以便你对Hadoop分布式文件系统(HDFS)和Map-Reduce框架有所体会,比如在HDFS上运行示例程序或简单作业等. 先决条件 ...
- Hadoop高速入门
Hadoop高速入门 先决条件 支持平台 GNU/Linux是产品开发和执行的平台. Hadoop已在有2000个节点的GNU/Linux主机组成的集群系统上得到验证. Win32平台是作为开发平台支 ...
- linux hadoop安装
linux hadoop安装 本文介绍如何在Linux下安装伪分布式的hadoop开发环境. 在一开始想利用cgywin在 windows下在哪, 但是一直卡在ssh的安装上.所以最后换位虚拟机+ub ...
- 转载:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文 http://www.powerxing.com/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单,书上有写到, ...
- hadoop安装遇到的各种异常及解决办法
hadoop安装遇到的各种异常及解决办法 异常一: 2014-03-13 11:10:23,665 INFO org.apache.hadoop.ipc.Client: Retrying connec ...
- hadoop安装实战(mac实操)
集群环境配置参考(http://blog.csdn.net/zcf1002797280/article/details/49500027) 参考:http://www.cnblogs.com/liul ...
- Solr安装入门、查询详解
Solr安装入门:http://www.importnew.com/12607.html 查询详解:http://www.360doc.com/content/14/0306/18/203871_35 ...
随机推荐
- Java集合类 课后练习
1.Pg235--2分别向Set集合以及List集合中添加“A”,“a” , "c" , "C" , "a" 5个元素,观察重复值“a”能 ...
- ASP.NET WebAPI 04 Model绑定
在前面的几篇文章中我们都是采用在URI中元数据类型进行传参,实际上ASP.NET Web API也提供了对URI进行复杂参数的绑定方式--Model绑定.这里的Model可以简单的理解为目标Ancti ...
- thinkphp3.2中开启静态缓存后对404页面的处理方法
静态缓存很实用但是有时有些不需要静态缓存,如404页面,第一次访问返回404页面并缓存,第二次换回的状态就是200,属于正常访问,虽然人眼可以看出是404页面,但是搜索引擎不会的,而是把这个页面当成正 ...
- Flutter的原理及美团的实践
导读 Flutter是Google开发的一套全新的跨平台.开源UI框架,支持iOS.Android系统开发,并且是未来新操作系统Fuchsia的默认开发套件.自从2017年5月发布第一个版本以来,目前 ...
- iOS 11开发教程(六)iOS11Main.storyboard文件编辑界面
iOS 11开发教程(六)iOS11Main.storyboard文件编辑界面 在1.2.2小节中提到过编辑界面(Interface builder),编辑界面是用来设计用户界面的,单击打开Main. ...
- 复杂密码生成工具apg
复杂密码生成工具apg 密码是身份认证的重要方式.由于密码爆破方式的存在,弱密码非常不安全.为了构建复杂密码,Kali Linux预置了一个复杂密码生成工具apg.该工具可以提供可读密码和随机字符 ...
- [BZOJ 4591] 超能粒子炮-改
Link: 传送门 Solution: 记录一下推$\sum_{i=0}^k C_n^i$的过程: 其实就是将相同的$i/p$合起来算,这样每个里面都是一个可以预处理的子问题 接下来递归下去算即可 T ...
- hdu 4462 第37届ACM/ICPC 杭州赛区 J题
题意:有一块n*n的田,田上有一些点可以放置稻草人,再给出一些稻草人,每个稻草人有其覆盖的距离ri,距离为曼哈顿距离,求要覆盖到所有的格子最少需要放置几个稻草人 由于稻草人数量很少,所以状态压缩枚举, ...
- SGU 405 Totalizator
405. Totalizator Time limit per test: 0.25 second(s)Memory limit: 65536 kilobytes input: standardout ...
- Solution for sending Whatsapp via sqlite "INSERT INTO"
I use something similar but thought I'd mention this 'bug' that can happen:when you INSERT '%wa_mess ...