Oracle案例10——HWM(高水位线)性能优化
最近BI同事反馈说一张表的数据查询非常慢,这个表数据总共不到1W行数据,这么一说我们首先想到的是高水位带来的性能问题,即高水位线下占用过多数据块,而这些数据块其实是部分数据占用,大多数是空闲的数据块。
我们知道高水位线下的数据块在全表扫描时都要做,所以扫描的数据块可能远远多于实际的存数据的数据块。
一、表统计信息收集
要想得到准确的高水位信息,必须先收集统计信息,这样得到的才相对比较准确。
ANALYZE TABLE table_name ESTIMATE STATISTICS; ANALYZE TABLE table_name COMPUTE STATISTICS FOR TABLE FOR ALL INDEXES FOR ALL INDEXED COLUMNS; execute dbms_stats.gather_table_stats(ownname => 'OWNER', tabname => 'TABLE_NAME' , estimate_percent => null ,method_opt => 'for all indexed columns' ,cascade => true);
二、表信息查看
查看表的块、行信息
select t.TABLE_NAME,t.NUM_ROWS,t.BLOCKS,t.empty_blocks,t.LAST_ANALYZED from dba_tables t where table_name in ('TABLE_NAME');
SELECT COUNT(DISTINCT DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID)) USED_BLOCK FROM TABLE_NAME;


上述查询结果显示,当前表行数是9651行,有716119个数据块被使用(HWM下的数据块),有0个未使用的数据块(HWM上的数据块)
实际数据占用的数据块数量为:152
综合可以看出,高水位线下其实有716119-152个数据块可以释放,这样每次全表扫描只需要扫描152个数据块即可。
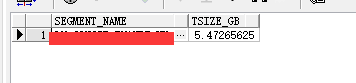
通过查看段大小佐证记录数和表大小关系是否一致,通过下面的查看段大小为5.5G,记录9651行几乎不可能达到这个大小,所以基本可以断定个里面有很多空闲的块。
select segment_name,bytes/1024/1024/1024 TSize_GB from dba_segments where segment_name='table_name' ---5876219904
三、问题原因
什么情况会导致上面的问题呢,即高水位下存在很多未使用的数据块?一般是大表(插入很多记录后),经过批量删除delete操作,未释放高水位导致的。
1.全表扫描要读取高水位线下的所有数据块,无论是否含有数据。
2.如果在插入数据的时候使用了append关键字,即使高水位线下有空闲的数据库,也会从高水位线上面的数据库做分配,也就是高水位线会上升。
四、降低高水位方法
1. alter table table_name move;
此方法可释放高水位,但需要重建索引
2.alter table table_name shrink space;
此方法可释放高水位,但执行前需要开启行移动,alter table table_name enable row movement;
3.emp/imp的方式重建表数据
4.drop/create方式重建表
5.truncate表
6.alter table table_name deallocate unused
DEALLOCATE UNUSED为释放HWM上面的未使用空间,但是并不会释放HWM下面的自由空间,也不会移动HWM的位置.
五、高水位调整实施
1.统计信息收集(如上)
2.执行计划查看
SQL> set autotrace trace ;
SQL> set timing on;
SQL> SELECT count(*) FROM TABLE_NAME;

3.表移动
alter table table_name move;
报错:ORA-00054: resource busy and acquire with NOWAIT specified or timeout expired
查看被锁对象:
select object_name,machine,s.sid,s.serial#
from v$locked_object l,dba_objects o ,v$session s
where l.object_id = o.object_id and l.session_id=s.sid;
执行后再查看执行计划统计信息
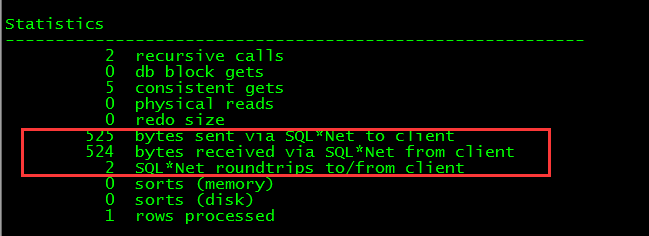
看到统计信息访问的数据块已经降下来了,然后执行全表扫描,速度也是飞快。
4.索引重建
alter index index_name rebuild online;
六、库高水位对象统计
①比较表的行数和表的大小关系。如果行数为0,而表的当前占用大小减去初始化时的大小(INITIAL_EXTENT)后依然很大,那么说明该表有高水位。
②行数和块数的比率,即查看一个块可以存储多少行数据。如果一个块存储的行数少于5行甚至更少,那么说明有高水位。注意,这两种方法都不是十分准确,需要再对查询结果进行筛选。需要注意的是,在查询表的高水位时,首先需要分析表,以得到最准确的统计信息。
SELECT D.OWNER,
ROUND(D.NUM_ROWS / D.BLOCKS, 2),
D.NUM_ROWS,
D.BLOCKS,
D.TABLE_NAME,
ROUND((d.BLOCKS*8-D.INITIAL_EXTENT/1024)/1024) t_size
FROM DBA_TABLES D
WHERE D.BLOCKS > 10
AND ROUND(D.NUM_ROWS / D.BLOCKS, 2) < 5
AND d.OWNER NOT LIKE '%SYS%' ;
或:
SELECT OWNER,
SEGMENT_NAME TABLE_NAME,
SEGMENT_TYPE,
GREATEST(ROUND(100 * (NVL(HWM - AVG_USED_BLOCKS, 0) /
GREATEST(NVL(HWM, 1), 1)),
2),
0) WASTE_PER
FROM (SELECT A.OWNER OWNER,
A.SEGMENT_NAME,
A.SEGMENT_TYPE,
B.LAST_ANALYZED,
A.BYTES,
B.NUM_ROWS,
A.BLOCKS BLOCKS,
B.EMPTY_BLOCKS EMPTY_BLOCKS,
A.BLOCKS - B.EMPTY_BLOCKS - 1 HWM,
DECODE(ROUND((B.AVG_ROW_LEN * NUM_ROWS *
(1 + (PCT_FREE / 100))) / C.BLOCKSIZE,
0),
0,
1,
ROUND((B.AVG_ROW_LEN * NUM_ROWS *
(1 + (PCT_FREE / 100))) / C.BLOCKSIZE,
0)) + 2 AVG_USED_BLOCKS,
ROUND(100 *
(NVL(B.CHAIN_CNT, 0) / GREATEST(NVL(B.NUM_ROWS, 1), 1)),
2) CHAIN_PER,
B.TABLESPACE_NAME O_TABLESPACE_NAME
FROM SYS.DBA_SEGMENTS A, SYS.DBA_TABLES B, SYS.TS$ C
WHERE A.OWNER = B.OWNER
AND SEGMENT_NAME = TABLE_NAME
AND SEGMENT_TYPE = 'TABLE'
AND B.TABLESPACE_NAME = C.NAME)
WHERE GREATEST(ROUND(100 * (NVL(HWM - AVG_USED_BLOCKS, 0) /
GREATEST(NVL(HWM, 1), 1)),
2),
0) > 50
AND OWNER NOT LIKE '%SYS%'
AND BLOCKS > 100
ORDER BY WASTE_PER DESC;
Oracle案例10——HWM(高水位线)性能优化的更多相关文章
- 【转】Oracle Freelist和HWM原理及性能优化
文章转自:http://www.wzsky.net/html/Program/DataBase/74799.html 近期来,FreeList的重要作用逐渐为Oracle DBA所认识,网上也出现一些 ...
- ORACLE 11g 生产中高水位线(HWM)处理
数据库中表不断的insert,delete,update,导致表和索引出现碎片.这会导致HWM之前有很多的空闲空间,而oracle在做全表扫描的时候会读取HWM一下的所有块,这样会产生更多的IO,影响 ...
- 第 10 章 MySQL Server 性能优化
前言: 本章主要通过针对MySQL Server(mysqld)相关实现机制的分析,得到一些相应的优化建议.主要涉及MySQL的安装以及相关参数设置的优化,但不包括mysqld之外的比如存储引擎相关的 ...
- Oracle多表连接效率,性能优化
Oracle多表连接,提高效率,性能优化 (转) 执行路径:ORACLE的这个功能大大地提高了SQL的执行性能并节省了内存的使用:我们发现,单表数据的统计比多表统计的速度完全是两个概念.单表统计可能只 ...
- Window 10 :我的性能优化:那效果,杠杠的!
微软的 windows 10,不错! 当全新安装后,性能总觉得别别扭扭,不那么干净利落. 下面就是我的个人优化措施,期间有很多技术性的操作,如果你没有动手能力,或者是技术小白,可以不用再看了! (1) ...
- Oracle中索引的使用 索引性能优化调整
索引是由Oracle维护的可选结构,为数据提供快速的访问.准确地判断在什么地方需要使用索引是困难的,使用索引有利于调节检索速度. 当建立一个索引时,必须指定用于跟踪的表名以及一个或多个表列.一旦建立了 ...
- MySQL性能调优与架构设计——第10章 MySQL数据库Schema设计的性能优化
第10章 MySQL Server性能优化 前言: 本章主要通过针对MySQL Server(mysqld)相关实现机制的分析,得到一些相应的优化建议.主要涉及MySQL的安装以及相关参数设置的优化, ...
- Linux性能优化实战学习笔记:第十二讲
一.性能优化方法论 不可中断进程案例 二.怎么评估性能优化的效果? 1.评估思路 2.几个为什么 1.为什么要选择不同维度的指标? 应用程序和系统资源是相辅相成的关系 2.性能优化的最终目的和结果? ...
- Oracle高水位线(HWM)及性能优化
说到HWM,我们首先要简要的谈谈ORACLE的逻辑存储管理.我们知道,ORACLE在逻辑存储上分4个粒度:表空间,段,区和块. (1)块:是粒度最小的存储单位,现在标准的块大小是8K,ORACL ...
随机推荐
- Fiddler Web Debugger的下载和安装(图文详解)
不多说,直接上干货! Fiddler是一个http协议调试代理工具,它能够记录客户端和服务器之间的所有 HTTP请求,可以针对特定的HTTP请求,分析请求数据.设置断点.调试web应用.修改请求的数据 ...
- 【转】Spark:一个高效的分布式计算系统
原文地址:http://tech.uc.cn/?p=2116 概述 什么是Spark Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架, ...
- java学习--Reflection反射机制
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意方法和属性:这种动态获取信息以及动态调用对象方法的功能称为java语言的反射机制. ...
- springboot-25-springboot 集成 ActiveMq
消息的发布有2种形式, 队列式(点对点) 和主题式(pub/sub) 模式, 队列式发布后, 接收者从队列中获取消息后, 消息就会消失, 但任意消费者都可以从队列中接受消息, 消息只能被接受一次 主题 ...
- Struts ongl 集合伪属性
首先了解下OGNL的概念: OGNL是Object-Graph Navigation Language的缩写,全称为对象图导航语言,是一种功能强大的表达式语言,它通过简单一致的语法,可以任意存取对象的 ...
- centos install 命令安装 mysql数据库
命令安装mysql就不需要自己去下载解压,超级方便 下载: wget http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm ...
- hadoop学习笔记(九):MapReduce程序的编写
一.MapReduce主要继承两个父类: Map protected void map(KEY key,VALUE value,Context context) throws IOException, ...
- 使用Python学习RabbitMQ消息队列
rabbitmq基本管理命令: 一步启动Erlang node和Rabbit应用:sudo rabbitmq-server 在后台启动Rabbit node:sudo rabbitmq-server ...
- 如何使用 Telegram
Telegram是一款加密的实时通讯软件,本文告诉大家如何使用 这个软件. 在使用之前,需要保证自己已经开了梯子,如果没有梯子,那么就无法使用这个工具. 假如梯子是 127.0.0.1 端口 1080 ...
- Apache Spark Exception in thread “main” java.lang.NoClassDefFoundError: scala/collection/GenTraversableOnce$class
问题: 今天用Maven搭建了一个Spark的Scala项目,运行后遇到下面异常: Apache Spark Exception in thread “main” java.lang.NoClassD ...