图片文字OCR识别-tesseract-ocr
帮助文件:https://github.com/tesseract-ocr/tesseract/blob/master/doc/tesseract.1.asc
下载地址:https://github.com/tesseract-ocr/tesseract/wiki
如何使用提供的工具来训练Tesseract 4.00:https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract-4.00
1、介绍
图片文字的OCR识别有一款开源原件tesseract-ocr,最初是在linux上,当然现在也有windows版本,现在发展到4.0版本。
2、下载tesseract-ocr
下载地址:https://github.com/tesseract-ocr/tesseract/wiki
里面有linux版本、macOS版本还有windows版本
下面下载windows版本,如下图:

点击上面的链接,进入
下载完成
3、安装,设置环境变量
双击上的exe,进行安装
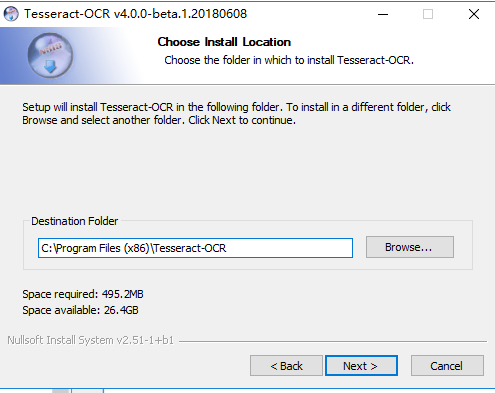
安装完后打开软件坐在目录,这里我选择的是默认目录C:\Program Files (x86)\Tesseract-OCR
安装目录C:\Program Files (x86)\Tesseract-OCR,安装完成后,设置环境变量
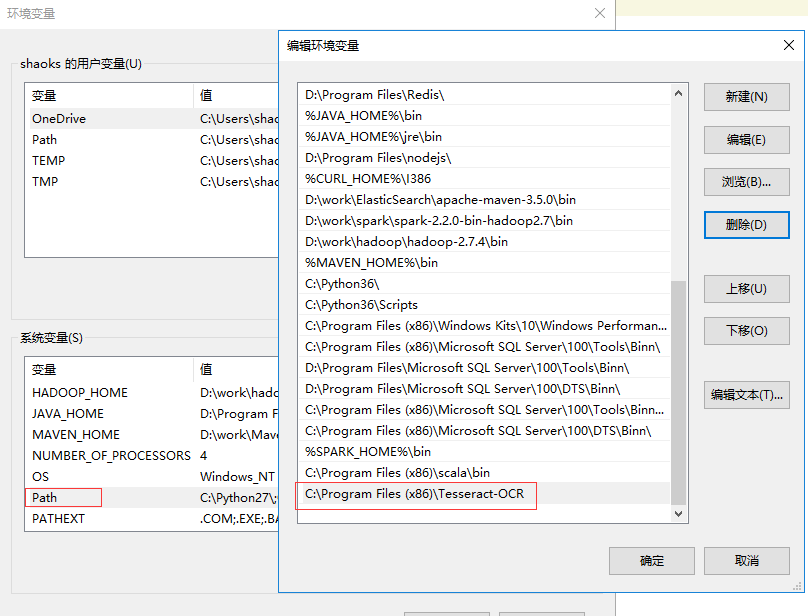
在系统变量下面点击新建,按照如图建一个变量如图
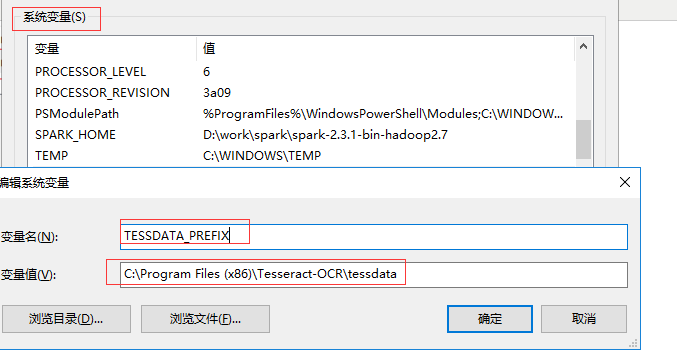
变量名TESSDATA_PREFIX,变量值:C:\Program Files (x86)\Tesseract-OCR\tessdata
4、应用
经过上面的调整tesseract命令可以在任意目录调用了,下面是tessract应用实例
4.1、识别中文图片

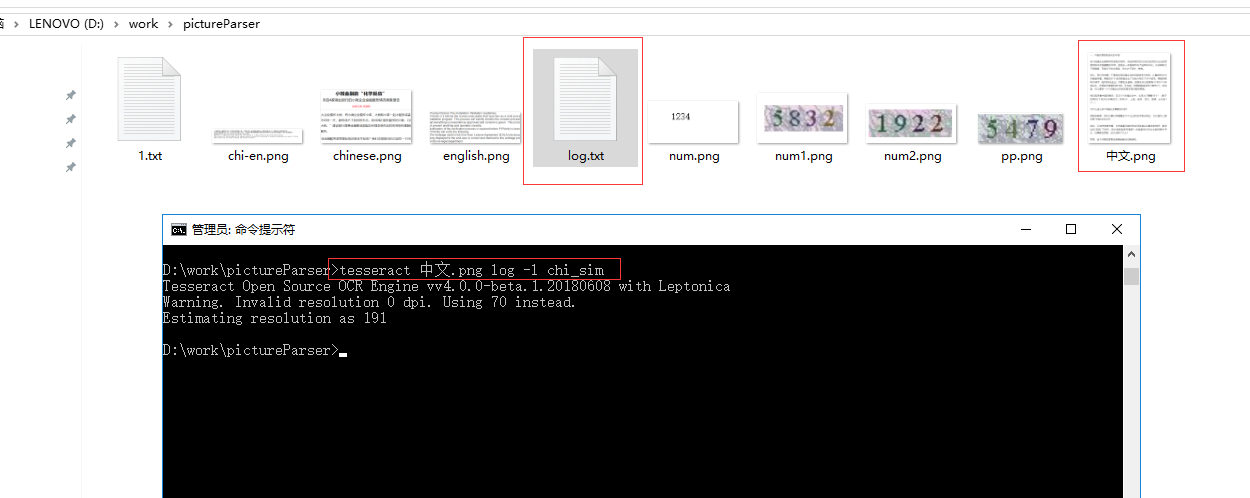
识别结果:

命令:tesseract 中文.png log -l chi_sim
把图片文件上的中文字符识别出来,写到log文本文件里面
4.2、识别英文图片
tesseract.exe 英文.png log -l eng

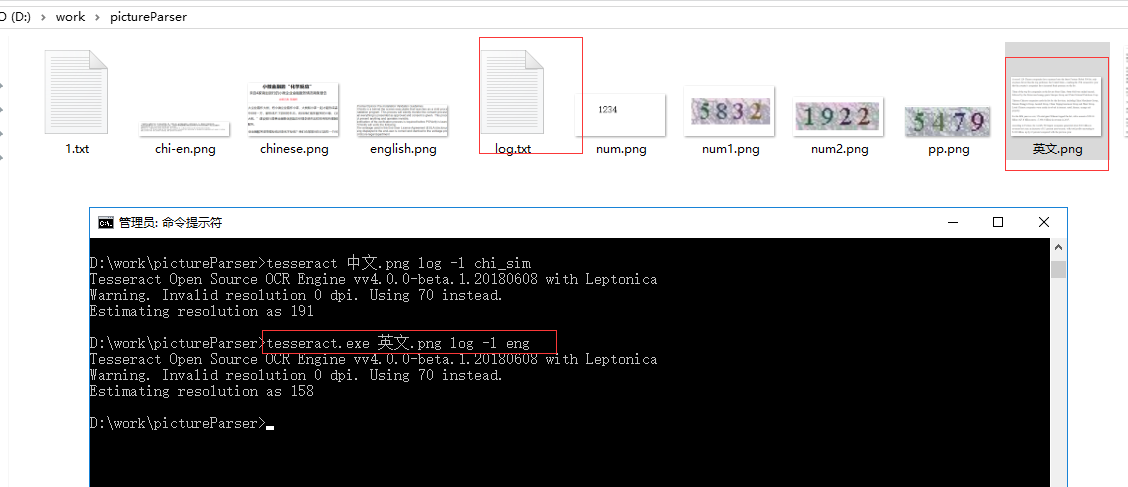
识别结果:

4.3、识别中英文混合
tesseract.exe 中文-英文-混合.png log -l chi_sim+eng

识别结果效果,中文部分不好

如果用 tesseract 中文-英文-混合.png log -l chi_sim
识别结果:显示中文识别比较好,但是因为有出息识别成中文的情况

4.4、识别简单数字
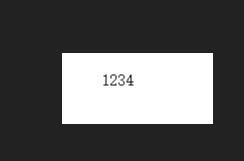
tesseract num.png log -l chi_sim
tesseract num.png log -l eng
都可以正常识别
如下面复杂的识别码就识别不了

总结:在识别只包含英文和数字的图片可以用简单的命令:
tesseract num.png log
如果包含中文的必须指定中文库:chi_sim
tesseract num1.png log -l chi_sim
附录:
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名
图片文字OCR识别-tesseract-ocr的更多相关文章
- 使用AI技术获取图片文字与识别图像内容
获取图片文字 如何使用python获取图片文字呢? 关注公众号[轻松学编程]了解更多- 1.通过python的第三方库pytesseract获取 通过pip install pytesseract导入 ...
- 发票OCR识别/票据OCR自动识别
对于一些大的集团公司来说,分散式财务管理模式管理效率不高,管理成本相对较高,同时也制约了集团企业发展战略的实施,因而需要建设财务共享中心.一个企业想建造财务共享中心,面临的难题是大量的数据采集和信息处 ...
- 使用Python进行OCR -- 识别图片中的文字
工具 Tesseract pytesseract tesserocr 朋友需要一个工具,将图片中的文字提取出来.我帮他在网上找了一些OCR的应用,都不好用.所以准备自己研究,写一个Web APP供他使 ...
- Tesseract——OCR图像识别 入门篇
Tesseract——OCR图像识别 入门篇 最近给了我一个任务,让我研究图像识别,从我们项目的screenshot中识别文字信息,so我开始了学习,与大家分享下. 我看到目前OCR技术有很多,最主要 ...
- 孤荷凌寒自学python第八十三天初次接触ocr配置tesseract环境
孤荷凌寒自学python第八十三天初次接触ocr配置tesseract环境 (完整学习过程屏幕记录视频地址在文末) 学习Python我肯定不会错过图片文字的识别,当然更重要的是简单的验证码识别了,今天 ...
- RPA中房产证的 OCR 识别
客户需求,识别一些证件内容,包括身份证.户口本.营业执照.银行卡以及房产证,前四个比较容易实现,不管是艺赛旗的 RPA 还是百度的 OCR 都有接口,直接调用即可,但是都没有房产证的 OCR 识别,只 ...
- 行驶证识别/行驶证OCR识别全方位解析
本文全面解析行驶证OCR识别,包括什么是行驶证OCR识别.如何选择行驶证识别软件.如何操作行驶证识别软件,以及该软件应用的领域等. 一.了解行驶证识别/行驶证OCR识别 行驶证OCR识别技术,也叫行驶 ...
- 开源图片文字识别引擎——Tesseract OCR
Tessseract为一款开源.免费的OCR引擎,能够支持中文十分难得.虽然其识别效果不是很理想,但是对于要求不高的中小型项目来说,已经足够用了. 文字识别可应用于许多领域,如阅读.翻译.文献资料的检 ...
- Python图像处理之图片文字识别(OCR)
OCR与Tesseract介绍 将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition,OCR).可以实现OCR 的底层库并不多,目前很多库都是使用共同 ...
- 【图片识别】java 图片文字识别 ocr (转)
http://www.cnblogs.com/inkflower/p/6642264.html 最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为 ...
随机推荐
- OpenGL 笔记<3> 数据传递 一
Sending data to a shader using vertex attributes and vertex buffer object 上次我们说到着色器的编译和连接,后面的事情没有做过多 ...
- Node.js CVE-2017-14849复现(详细步骤)
0x00 前言 早上看Sec-news安全文摘的时候,发现腾讯安全应急响应中心发表了一篇文章,Node.js CVE-2017-14849 漏洞分析(https://security.tencent. ...
- 【WIN10】程序內文件讀取與保存
DEMO下載:http://yunpan.cn/cFHIZNmAy4ZtH 访问密码 cf79 1.讀取與保存文件 Assets一般被認為是保存用戶文件數據的地方.同時,微軟還支持用戶自己創建文件夾 ...
- [UOJ422]小Z的礼物
设要取的物品集合为$S$,$E=n(m-1)+(n-1)m$,$x_T$为覆盖了$T$中至少一个元素的$1\times2$数量 $$\begin{aligned}\sum\limits_{i=1}^\ ...
- [POI2012]Salaries
题目大意: 给定一棵n带权树,每个点的权值在[1,n]范围内且互不相等,并满足子结点的权值一定小于父结点. 现在已知一个包含根结点的联通块中个点的权值,求剩下哪些点的权值能够被求出,并求出这些权值. ...
- nodejs环境使用jshint
一.概述jshint是检测JavaScript语法问题的工具,可以根据自己的需要配置检测规则. 二.安装npm install jshint -g一般全局安装就可以了,可以在任何目录下使用jshint ...
- mysql关联查询和联合查询
一.内联方式 1.传统关联查询 "select * from students,transcript where students.sid=transcript.sid and transc ...
- 使用python解决烦人的每周邮件汇总!
最近开始接手BI工作,其中又一个繁琐又不得不做的事,就是每周五都得汇总上个财务周的数据给运营人员! 作为一个懒人,只能把这件事交由电脑去处理了. 初步的idea:周五11点前mac自动执行汇总程序-& ...
- HP Microserver Gen8 Processor FAQ
http://homeservershow.com/forums/index.php?/topic/6596-hp-microserver-gen8-processor-faq/ This guide ...
- oracle systemtap tracing
https://github.com/LucaCanali?tab=repositories https://github.com/LucaCanali/Linux_tracing_scripts/t ...