SKLearn数据集API(二)
注:本文是人工智能研究网的学习笔记
计算机生成的数据集
用于分类任务和聚类任务,这些函数产生样本特征向量矩阵以及对应的类别标签集合。
| 数据集 | 简介 |
|---|---|
| make_blobs | 多类单标签数据集,为每个类分配一个或者多个正态分布的点集,提供了控制每个数据点的参数:中心点(均值),标准差,常用于聚类算法。 |
| make_classification | 多类单标签数据集,为每个类分配了一个或者多个正态分布的点集。提供了为数据集添加噪声的方式,包括维度相性,无效特征和冗余特征等。 |
| make_gaussian_quantiles | 将一个单高斯分布的点集活粉为两个数量均等的点集,作为两类。 |
| make_hastie_10_2 | 产生一个相似的二元分类器数据集,有10个维度。 |
| make_circles/make_moons | 产生二维分类数据集来测试某些算法(e.g.centroid-based clustering或linear classfication)的性能。可以为数据集添加噪声,可以为二元分类器产生一些球形判决表面的数据。 |
用于多标签分类任务
| 数据集 | 简介 |
|---|---|
| make_multilabel_classification | 产生多类多标签随机样本,这些样本模拟了从很多话题的混合分布中抽取的词袋模型,每个文档的话题数量符合泊松分布,话题本身则从一个固定的随机分布中抽取出来,同样的,单词数量也是泊松分布抽取,句子则是从多项式抽取。 |
用于回归任务的
| 数据集 | 简介 |
|---|---|
| make_regression | 产生回归任务的数据集,期望目标输出是随机特征的稀疏随机线性组合,并且附带有噪声,它的有用的特征可能是不相关的,或者低秩的(引起目标值的变动的只有少量的集合特征) |
| make_sparse_uncorrelated | 产生四个特征的线性组合(固定参数)作为期望目标输出 |
| make_friedman1 | 采用了多项式和正弦变换 |
| make_friedman2 | 包含了特征的乘积和互换操作 |
| make_friedman3 | 类似于arctan变换 |
用于流行学习的
| 数据集 | 简介 |
|---|---|
| make_s_curve | 生成S型曲线数据集 |
| make_swiss_roll | 生成瑞士卷曲线数据集 |
用于因子分解的
| 数据集 | 简介 |
|---|---|
| make_low_rank_matrix | |
| make_sparse_coded_signal | |
| nake_spd_matrix | 产生的是随机的堆成的正定矩阵 |
| make_sparse_spd_matrix | 产生的是稀疏的堆成正定矩阵 |
make_blobs()
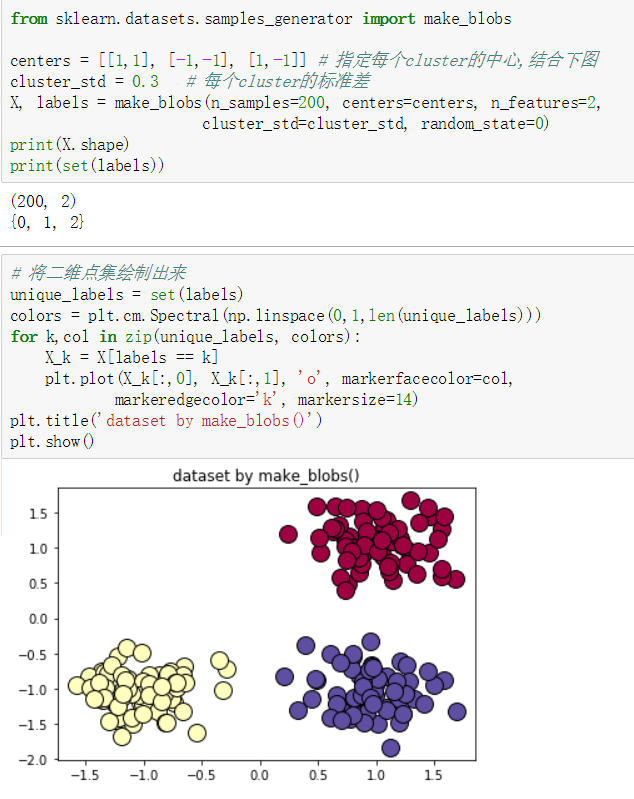
make_classification()
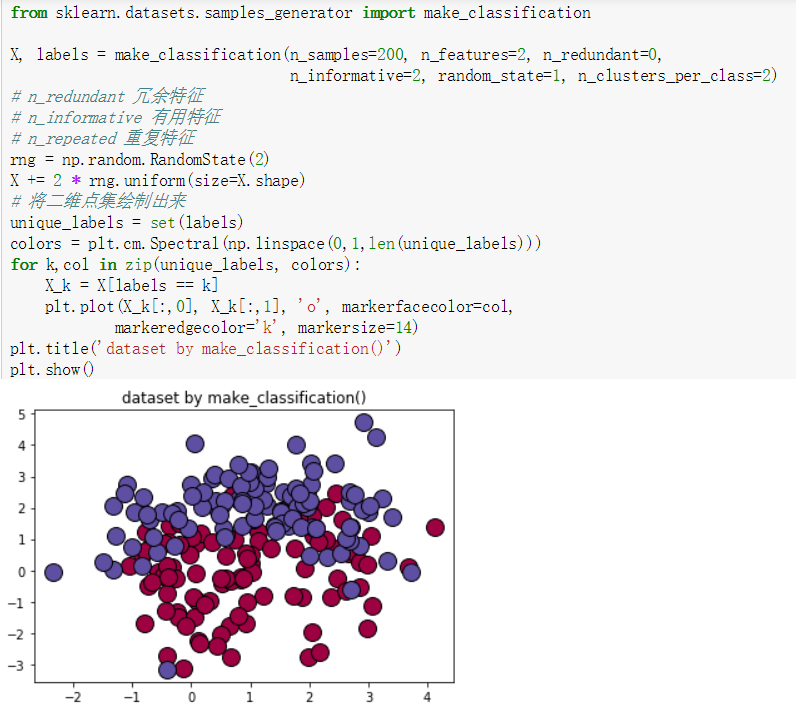
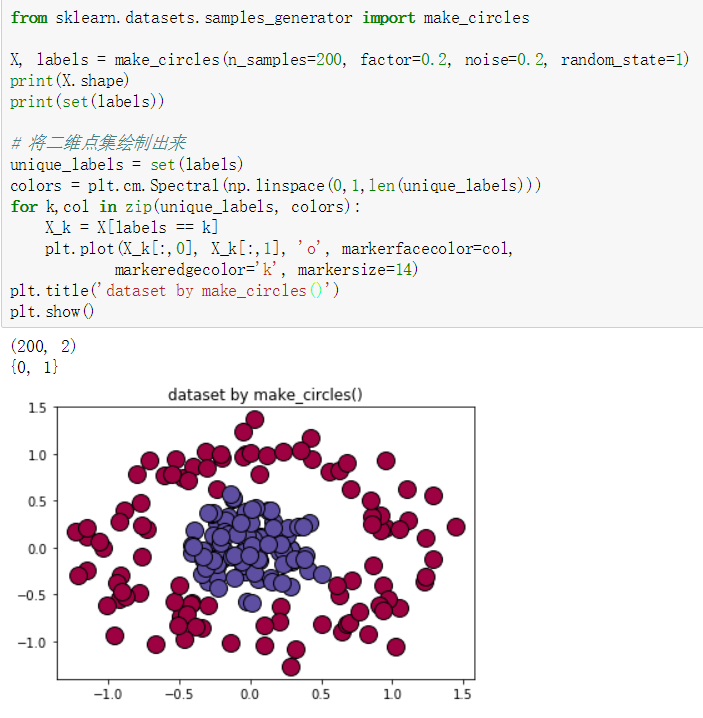
make_moons()

make_circles()
svmlight/libsvm格式的数据集
svmlight/libsvm的每一行样本的存放格式
<label> <feature-id>:<feature-value> <feature-id>:<feature-value>...
使用下面的方式导入该格式的数据集
X_train, y_train = sklearn.datasets.load_svmlight_file('train.txt')
还可以使用下面的方式将训练集和测试集一起导入,可以保证X_train和X_test有同样数目的特征
X_train, y_train, X_test, y_test = sklearn.datasets.load_svmlight_file(('train.txt', 'test.txt'))
SKLearn数据集API(二)的更多相关文章
- SKLearn数据集API(一)
注:本文是人工智能研究网的学习笔记 数据集一览 类型 获取方式 自带的小数据集 sklearn.datasets.load_ 在线下载的数据集 sklearn.datasets.fetch_ 计算机生 ...
- 【学习笔记】sklearn数据集与估计器
数据集划分 机器学习一般的数据集会划分为两个部分: 训练数据:用于训练,构建模型 测试数据:在模型检验时使用,用于评估模型是否有效 训练数据和测试数据常用的比例一般为:70%: 30%, 80%: 2 ...
- 机器学习笔记(四)--sklearn数据集
sklearn数据集 (一)机器学习的一般数据集会划分为两个部分 训练数据:用于训练,构建模型. 测试数据:在模型检验时使用,用于评估模型是否有效. 划分数据的API:sklearn.model_se ...
- sklearn——数据集调用及应用
忙了许久,总算是又想起这边还没写完呢. 那今天就写写sklearn库的一部分简单内容吧,包括数据集调用,聚类,轮廓系数等等. 自带数据集API 数据集函数 中文翻译 任务类型 数据规模 load_ ...
- Sklearn数据集与机器学习
sklearn数据集与机器学习组成 机器学习组成:模型.策略.优化 <统计机器学习>中指出:机器学习=模型+策略+算法.其实机器学习可以表示为:Learning= Representati ...
- sklearn数据集
数据集划分: 机器学习一般的数据集会划分为两个部分 训练数据: 用于训练,构建模型 测试数据: 在模型检验时使用,用于评估模型是否有效 sklearn数据集划分API: 代码示例文末! scikit- ...
- Civil 3D API二次开发学习指南
Civil 3D构建于AutoCAD 和 Map 3D之上,在学习Civil 3D API二次开发之前,您至少需要了解AutoCAD API的二次开发,你可以参考AutoCAD .NET API二次开 ...
- 用JSON-server模拟REST API(二) 动态数据
用JSON-server模拟REST API(二) 动态数据 上一篇演示了如何安装并运行 json server , 在这里将使用第三方库让模拟的数据更加丰满和实用. 目录: 使用动态数据 为什么选择 ...
- Express4.x API (二):Request (译)
写在前面 最近学习express想要系统的过一遍API,www.expressjs.com是express英文官网(进入www.epxressjs.com.cn发现也是只有前几句话是中文呀~~),所以 ...
随机推荐
- spring断言使用
断言就是断定某一个实际的值为自己预期想得到的,如果不一样就抛出异常. Assert经常用于: 1.判断method的参数是否属于正常值.2.juit中使用. import org.springfram ...
- margin-bottom无效问题以及div里内容动态居中样式!
最近调前端样式时候,遇到一个需求,在中间文字不对等的情况下想让下面的操作文字距离底部对齐,如图: , 刚开始觉得使用margin-bottom就可以,后来发现只有margin-top是管用的,查了资料 ...
- vue系列之项目优化
webpack中的Code Splitting Code Splitting是什么以及为什么 在以前,为了减少HTTP请求,通常地,我们会把所有的代码都打包成一个单独的JS文件,但是,如果这个文件体积 ...
- robotframework-ride多次运行,有时候不显示日志信息
解决方法: 修改"C:\Python27\lib\site-packages\robotide\contrib\testrunner\testrunner.py"文件pop方法中 ...
- 网络协议之NAT穿透
NAT IPv4地址只有32位,最多只能提供大致42.9亿个唯一IP地址,当设备越来越多时,IP地址变得越来越稀缺,不能为每个设备都分配一个IP地址.于是,作为NAT规范就出现了.NAT(Networ ...
- mysql慢sql报警系统
前言:最近有同事反应有的接口响应时间时快时慢,经过排查有的数据层响应时间过长,为了加快定位定位慢sql的准确性,决定简单地搭建一个慢sql报警系统 具体流程如下架构图 第一步:记录日志 每个业务系统都 ...
- Unix IPC之Posix消息队列(2)
/* Query status and attributes of message queue MQDES. */ extern int mq_getattr (mqd_t __mqdes, stru ...
- MySQL学习笔记:时间差
1.MySQL计算同一张表中同一列的时间差,同一个id,有多个时间,求出每个id最早时间和最晚时间之间的差值. 原始表如下: 查询语句: SELECT id, MAX(TIME), MIN(TIME) ...
- CentOS7的firewall和安装iptables
前言:CentOS7 的防火墙默认使用是firewall,而我们通常使用iptables: 本文记录了firewall基础的命令和iptables的安装和使用. firewall部分: part1 : ...
- Dev控件删除按钮的两种方式
测试版本15.2.10:在Dev控件中删除按钮空间有两种方式:1.鼠标右键出现Delete选项,这种删除是不完全的删除,只是删除了按钮的显示,实际上按钮还是存在于代码中的.2.用键盘上的Delete键 ...