Apache Storm使用
Apache Storm 是 Apache 基金会的开源的分布式实时计算系统。与 Hadoop 的批处理相类似,Storm 可以对大量的数据流进行可靠的实时处理,这一过程也称为“流式处理”,是分布式大数据处理的一个重要方向。Storm 支持多种类型的应用,包括:实时分析、在线机器学习、连续计算、分布式RPC(DRPC)、ETL等。Strom 的一个重要特点就是“快速”的数据处理,有 benchmark 显示 Storm 能够达到单个节点每秒百万级 tuple 处理(tuple 是 Storm 的最小数据单元)的速度。快速的数据处理、优秀的可扩展性与容错性、便捷的可操作性与维护性、活跃的社区技术支持,这就是 Storm。
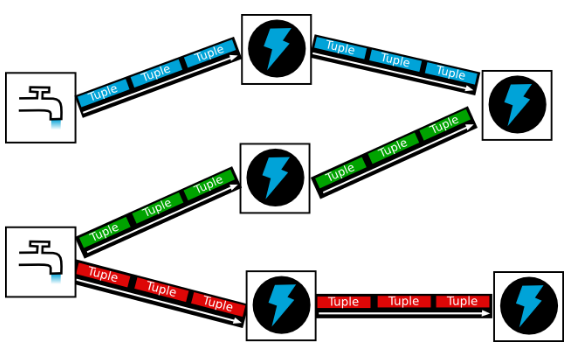
Storm 集群组件

Storm 集群中包含两类节点:主控节点(Master Node)和工作节点(Work Node)。其分别对应的角色如下:
- 主控节点(Master Node)上运行一个被称为Nimbus的后台程序,它负责在Storm集群内分发代码,分配任务给工作机器,并且负责监控集群运行状态。Nimbus的作用类似于Hadoop中JobTracker的角色
- 每个工作节点(Work Node)上运行一个被称为Supervisor的后台程序。Supervisor负责监听从Nimbus分配给它执行的任务,据此启动或停止执行任务的工作进程。每一个工作进程执行一个Topology的子集;一个运行中的Topology由分布在不同工作节点上的多个工作进程组成
Nimbus 和 Supervisor 节点之间所有的协调工作是通过 Zookeeper 集群来实现的。此外,Nimbus 和 Supervisor 进程都是快速失败(fail-fast)和无状态(stateless)的;Storm 集群所有的状态要么在 Zookeeper 集群中,要么存储在本地磁盘上。这意味着你可以用 kill -9 来杀死 Nimbus 和 Supervisor 进程,它们在重启后可以继续工作。这个设计使得Storm集群拥有不可思议的稳定性。
Storm 部署步骤
搭建一个Storm集群需要依次完成的安装步骤:
- 搭建Zookeeper集群
- 安装Storm依赖库(Java、Python)
- 下载并解压Storm发布版本
- 修改storm.yaml配置文件
- 启动Storm各个后台进程
Storm.yaml 配置
Storm发行版本解压目录下有一个conf/storm.yaml文件,用于配置Storm。默认配置可以在这里查看。conf/storm.yaml中的配置选项将覆盖defaults.yaml中的默认配置。以下配置选项是必须在conf/storm.yaml中进行配置的:
- storm.zookeeper.servers: Storm集群使用的Zookeeper集群地址,其格式如下: storm.zookeeper.servers: - "111.222.333.444" - "555.666.777.888" 如果Zookeeper集群使用的不是默认端口,那么还需要storm.zookeeper.port选项
- storm.local.dir: Nimbus和Supervisor进程用于存储少量状态,如jars、confs等的本地磁盘目录,需要提前创建该目录并给以足够的访问权限。然后在storm.yaml中配置该目录,如: storm.local.dir: "/home/admin/storm/workdir"
- java.library.path: Storm使用的本地库加载路径,默认为"/usr/local/lib:/opt/local/lib:/usr/lib",一般不需要配置
- nimbus.host: Storm集群Nimbus机器地址,各个Supervisor工作节点需要知道哪个机器是Nimbus,以便下载Topologies的jars、confs等文件,如: nimbus.host: "111.222.333.444"
- supervisor.slots.ports: 对于每个Supervisor工作节点,需要配置该工作节点可以运行的worker数量。每个worker占用一个单独的端口用于接收消息,该配置选项即用于定义哪些端口是可被worker使用的。如果需要在每个节点上运行4个workers,可以分别使用6700、6701、6702和6703端口,如: supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703
- JVM options: 用于配置Storm使用JVM参数
[注] yaml 文件的配置使用“-”来表示数据的层次结构,配置项的:后必须有空格,否则该配置项无法识别
集群配置示例如下:
########### These MUST be filled in for a storm configuration
# storm.zookeeper.servers:
# - "server1"
# - "server2"
storm.zookeeper.servers:
- "192.168.9.182"
- "192.168.9.185"
- "192.168.91.128"
storm.zookeeper.port: 2181
# storm's work directory
storm.local.dir: "/home/storm/workdir"
# nimbus.host: "nimbus"
nimbus.host: "192.168.9.185"
# supervisor's work ports
supervisor.slots.ports:
-6700
-6701
-6702
-6703 # #### Netty transport configuration
# transmission protocol
storm.messaging.transport: "backtype.storm.messaging.netty.Context"
# server's work threads number
storm.messaging.netty.server_worker_threads: 1
# client's work threads number
storm.messaging.netty.client_worker_threads: 1
# buffer size
storm.messaging.netty.buffer_size: 5242880
# max retry times
storm.messaging.netty.max_retries: 100
# max waiting time(ms)
storm.messaging.netty.max_wait_ms: 1000
# min waiting time(ms)
storm.messaging.netty.min_wait_ms: 100 ## JVM parameters can be configured here
nimbus.childopts: "-Xloggc:/home/enjoyor/storm/apache-storm-0.9.3/logs/nimbusGC.log -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps"
supervisor.childopts: "-Xloggc:/home/enjoyor/storm/apache-storm-0.9.3/logs/nimbusGC.log -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps"
worker.childopts: "-Xloggc:/home/enjoyor/storm/apache-storm-0.9.3/logs/nimbusGC.log -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps"
Storm 运行
和Zookeeper一样,Storm也是快速失败(fail-fast)的系统,这样Storm才能在任意时刻被停止,并且当进程重启后被正确地恢复执行。这也是为什么Storm不在进程内保存状态的原因,即使Nimbus或Supervisors被重启,运行中的Topologies不会受到影响。以下是启动Storm各个后台进程的方式:
- Nimbus: 在Storm主控节点上运行 nohup storm nimbus & 启动Nimbus后台程序,并放到后台执行;
- Supervisor: 在Storm各个工作节点上运行nohup storm supervisor & 启动Supervisor后台程序,并放到后台执行;
- UI: 在Storm主控节点上运行nohup storm ui & 启动UI后台程序,并放到后台执行,启动后可以通过 http://{nimbus host}:8080 观察集群的worker资源使用情况、Topologies的运行状态等信息。
注意事项
- Storm后台进程被启动后,将在Storm安装部署目录下的logs/子目录下生成各个进程的日志文件。
- 经测试,Storm UI必须和Storm Nimbus 部署在同一台机器上,否则UI无法正常工作,因为UI进程会检查本机是否存在Nimbus链接。
- 为了方便使用,可以将bin/storm加入到系统环境变量中。
至此,Storm集群已经部署、配置完毕,可以向集群提交拓扑运行了。
向Storm 集群提交任务
- 启动 Storm Topology:
storm jar allmycode.jar org.me.MyTopology arg1 arg2 arg3
其中,allmycode.jar 是包含 Topology 实现代码的 jar 包,org.me.MyTopology 的 main 方法是 Topology 的入口,arg1、arg2 和 arg3 为 org.me.MyTopology 执行时需要传入的参数。
2. 停止 Storm Topology:
storm kill {toponame}
其中,{toponame} 为 Topology 提交到 Storm 集群时指定的 Topology 任务名称。
Apache Storm使用的更多相关文章
- Apache Storm 的历史及经验教训——Nathan Marz【翻译】
英文原文地址 中英文对照地址 History of Apache Storm and lessons learned --项目创建者 Nathan Marz Apache Storm 最近成为了ASF ...
- Apache Storm 与 Spark:对实时处理数据,如何选择【翻译】
原文地址 实时商务智能这一构想早已算不得什么新生事物(早在2006年维基百科中就出现了关于这一概念的页面).然而尽管人们多年来一直在对此类方案进行探讨,我却发现很多企业实际上尚未就此规划出明确发展思路 ...
- 从Apache Storm学到的经验教训 —— storm的由来(转)
阅读目录 Storm来源 初探 再探 构建第一个版本 被Twitter收购 开源的Storm 发布之后 Storm的技术演进 构建开发者社区版 离开Twitter 提交到Apache Apache孵化 ...
- Apache Storm 衍生项目之2 -- Trident-ML
欢迎转载,转载请注明出处,徽沪一郎,谢谢. 楔子 或许谈起storm是大数据实时计算框架已经让你不明觉厉,如果说storm还可以跟机器学习算法(ml)有机的结合在一起,是不是更加觉着高大尚呢.trid ...
- Apache Storm技术实战之1 -- WordCountTopology
欢迎转载,转载请注意出处,徽沪一郎. “源码走读系列”从代码层面分析了storm的具体实现,接下来通过具体的实例来说明storm的使用.因为目前storm已经正式迁移到Apache,文章系列也由twi ...
- Apache Storm简介
Apache Storm简介 Storm是一个分布式的,可靠的,容错的数据流处理系统.Storm集群的输入流由一个被称作spout的组件管理,spout把数据传递给bolt, bolt要么把数据保存到 ...
- Apache Storm 1.1.0 发布概览
写在前面的话 本人长期关注数据挖掘与机器学习相关前沿研究.欢迎和我交流,私人微信:846731084 我自己测试了一下这个版本,总的来说更加稳定,新增的特性并没有一一测试,仅凭kafk-client来 ...
- Apache Storm 1.1.0 中文文档 | ApacheCN
前言 Apache Storm 是一个免费的,开源的,分布式的实时计算系统. 官方文档: http://storm.apache.org 中文文档: http://storm.apachecn.org ...
- kerberos环境storm配置:Running Apache Storm Securely
Running Apache Storm Securely Apache Storm offers a range of configuration options when trying to se ...
- Apache Storm
作者:jiangzz 电话:15652034180 微信:jiangzz_wx 微信公众账号:jiangzz_wy 背景介绍 流计算:将大规模流动数据在不断变化的运动过程中实现数据的实时分析,捕捉到可 ...
随机推荐
- ubuntu 12.04 安装无线网卡驱动
安装ubuntu 12.04后,无线网卡不可用,采用以下方式解决: 1.在终端中运行如下命令,重新安装b43相关的全部驱动和firmware: sudo apt-get install bcmwl-k ...
- python环境搭建-Pycharm模块安装方法
不懂直接看图顺序操作: 方法一: 方法二:
- 【Hadoop】Combiner的本质是迷你的reducer,不能随意使用
问题提出: 众所周知,Hadoop框架使用Mapper将数据处理成一个<key,value>键值对,再网络节点间对其进行整理(shuffle),然后使用Reducer处理数据并进行最终输出 ...
- ubuntu添加默认路由才可以访问网络
- 体绘制(Volume Rendering)概述之4:光线投射算法(Ray Casting)实现流程和代码(基于CPU的实现)
转自:http://blog.csdn.net/liu_lin_xm/article/details/4850630 摘抄“GPU Programming And Cg Language Primer ...
- 在不重装系统的情况下撤底删除oracle数据库及oralce的相关软件
先从控制面板删除oracle的相关应用及数据库, 删除系统变量 ORACLE_OEM_CLASSPATH=%JAVA_HOME%\lib\ext\access-bridge-64.jar;%JAVA_ ...
- B. Ohana Cleans Up(Codeforces Round #309 (Div. 2))
B. Ohana Cleans Up Ohana Matsumae is trying to clean a room, which is divided up into an n by n gr ...
- 运维-JVM监控之内存泄漏
转载:https://blog.csdn.net/zdx_csdn/article/details/71214219 jmap -heap pid查看进程堆内存使用情况,包括使用的GC算法.堆配置参数 ...
- 在简化版Fedora8上安装jdk-7u25-linux-i586.rpm的过程
台式机的操作系统重新换回了Fedora8,遵从一些大牛的建议,把很多附件去了,尽量让系统保持最简化.这样能熟悉每个软件的安装配置过程,也能减少版本间的冲突. 进入控制台后,查查有没有Java存在系统中 ...
- Android 四大组件之 Activity(一)
1.Activity的定义及作用: Android系统中的四大组件之一,可以用于显示View.Activity是一个与用户交互的系统模块,几乎所有的Activity都是和用户进行交互的一个应用程序的组 ...