shell脚本之数组基本操作及排序
数组的基本操作及排序
1、数组定义方法:
( 6 7 9 4 3 2)
0 1 2 3 4 5 #下标号
方法一:
数组名=(value0 value1 value2 …)

方法二:
数组名=([0]=value [1]=value [2]=value …)

方法三:
列表名=“value0 value1 value2 …”
数组名=($列表名)

方法四:
数组名[0]=“value”
数组名[1]=“value”
数组名[2]="value"

2、数组包括的数据类型
- 数值类型
- 字符类型(字符串):使用" "或’ '定义,防止元素当中有空格,元素按空格分割
3、获取数组长度
arr_number=(1 2 3 4 5)
arr_length=${#arr_number[@]}
${#arr_number[*]}
echo $arr_length


4、获取数组列表
echo ${arr_number[*]}
echo ${arr_number[@]}

5、读取某下标赋值
arr_index2=${arr_number[2]}
echo $arr_index2

6、数组遍历
#!/bin/bash
arr_number=(0 1 2 3 4 5 6 7) for v in ${arr_number[@]}
do
echo $v
done


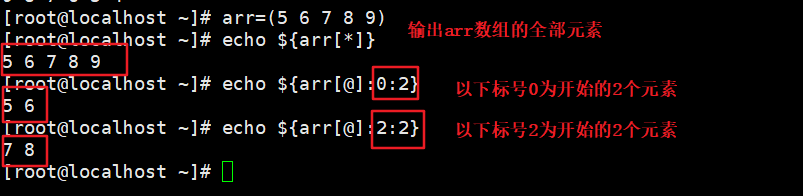
7、数组切片
arr_number=(0 1 2 3 4 5 6 )
echo ${arr[@]} #输出整个数组
echo ${arr[@]:0:2}
echo ${arr1[*]:1:3}
echo ${arr[@]:2:3}
8、数组删除
arr=(1 2 3 4 5)
unset arry #删除整个数组
echo ${arry[*]} arr=(1 2 3 4 5)
unset arr[2] #删除第三个元素
echo ${arr[*]}

9、数组追加元素
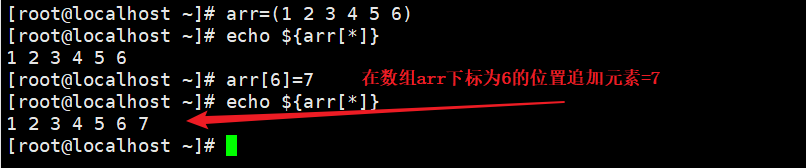
方法1:直接使用下标进行元素的追加
array_name[index]=value
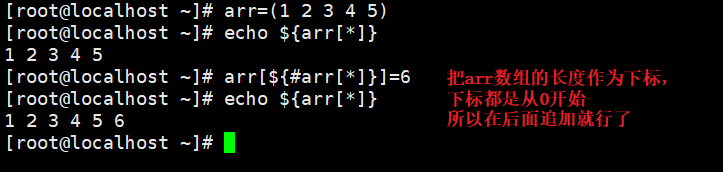
方法2:将数组的长度作为下标进行追加元素
array_name[${array_name[@]}]=value
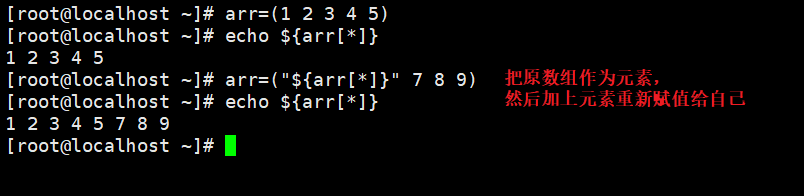
方法3:双引号不能省略,否则,当数组array name中存在包含空格的元素时会按空格将元素拆分成多个
不能将“@”替换为 “ * ”,如果替换为“ * ”,不加双引号时与"@"的表现一致,加双引号时,会将数组array name中的所有元素作为一个元素添加到数组中。
array_name=("${array_name[@]}" value1 ...valueN)
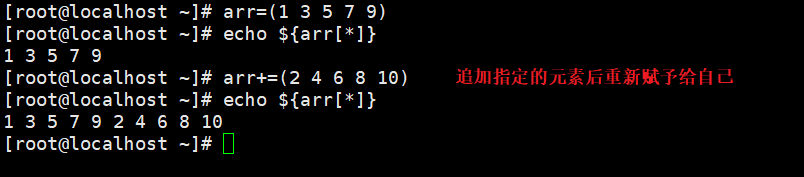
方法4:待添加元素必须用“()”包围起来,并且多个元素用空格隔开
array_name+=(value1...valueN)
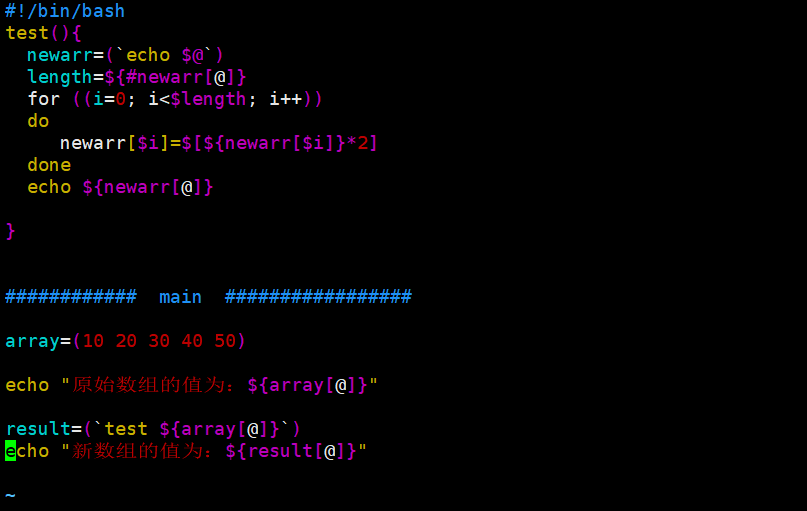
10、向函数传数组参数
test2() {
newarrary=($(echo $@))
echo "新数组的值为:${newarrary[*]}"
}
array=(3 2 1 4 5)
echo "原始数组的值为:${array[*]}"
test2 ${array[*]}

11、数组的排序
冒泡排序:
1.概述:类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断向前移动。
2.基本思想:冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一 样从底部上升到顶部。
3.算法思路:冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了。而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少。
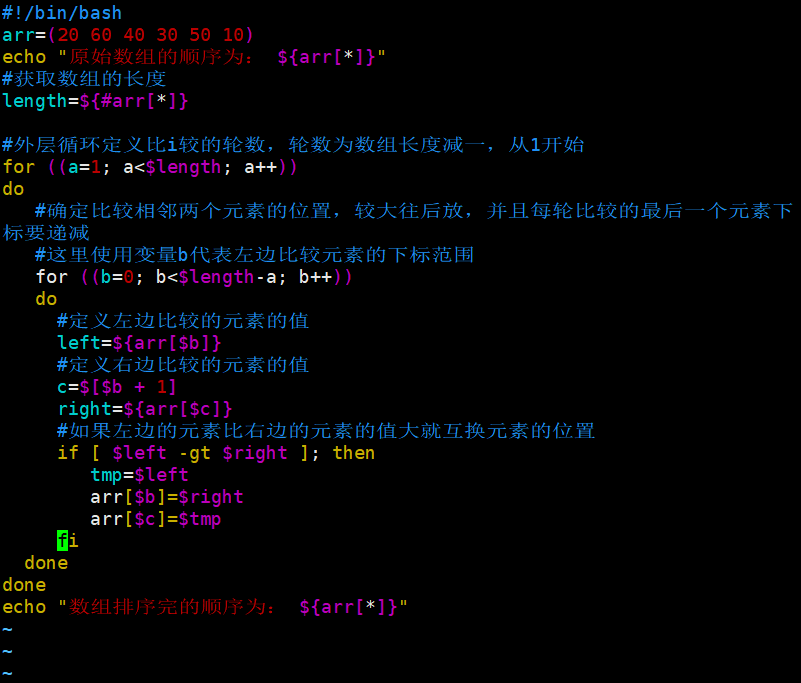
#!/bin/bash array=(60 20 30 50 10 40)
echo "原数组元素顺序为:${array[*]}" for ((i=1;i<${#array[*]};i++))
do
for ((a=0;a<${#array[*]}-i;a++))
do if [ ${array[$a]} -gt ${array[$a+1]} ]
then temp=${array[$a]} array[$a]=${array[$a+1]} array[$a+1]=$temp fi done
done
echo “数组排序完顺序为:${array[*]}"

直接选择排序:
与冒泡排序相比,直接选择排序的交换次数更少,所以速度更快。
基本思想: 将指定排序位置与其他数组元素分别对比,如果满足条件就交换元素值,注意这里区别冒泡排序,不是交换相邻元素,而是把满足条件的元素与指定的排序位置交换(如从最后一个元素开始排序),这样排序好的位置逐渐扩大,最后整个数组都成为已排序好的格式。
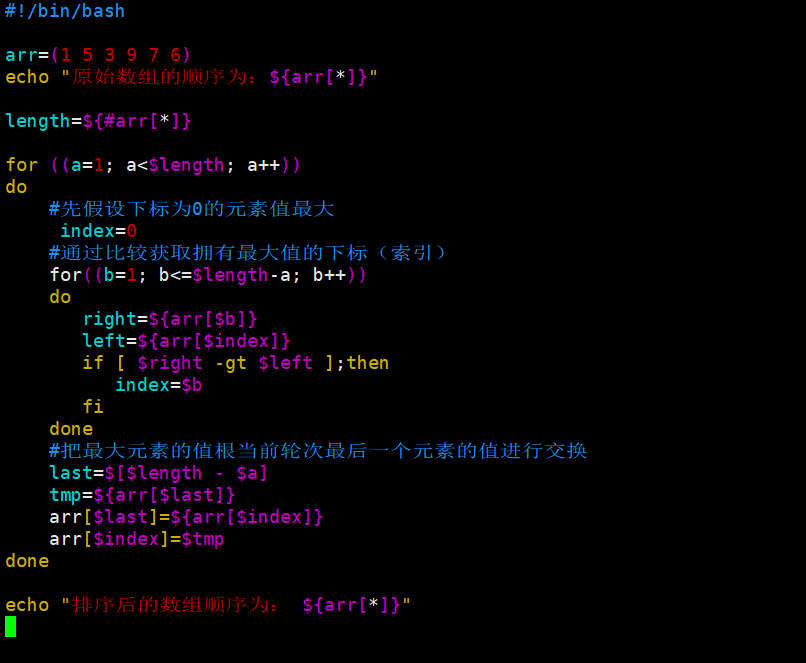
#!/bin/bash
array=(7 6 3 2 1 4)
echo "原数组元素顺序为:${array[*]}" long=${#array[*]}
for ((i=1;i<$long;i++))
do
index=0
for ((a=1;a<=$long-$i;a++))
do if [ ${array[$a]} -gt ${array[$index]} ]
then
index=$a
fi
last=$[$long-$i] temp=${array[$last]}
array[$last]=${array[$index]}
array[$index]=$temp done
done echo "经过直接排序后数组元素顺序为:${array[*]}"

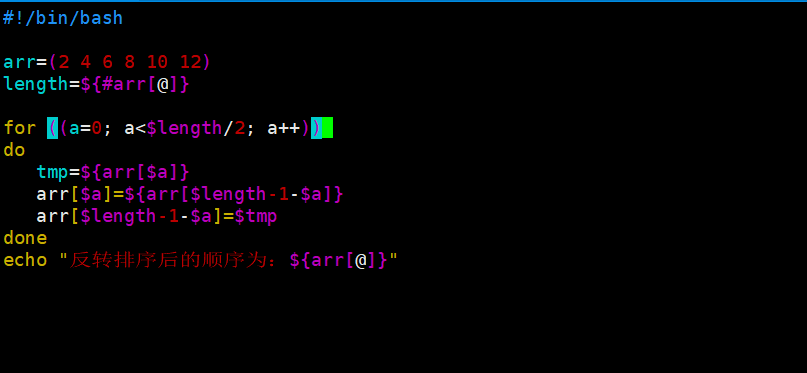
反转排序:
以相反的顺序把原有数组的内容重新排序
基本思想:
把数组最后一个元素与第一个元素替换。倒数第二个元素与第二个元素替换,以此类推,直到把所有的数组元素反转替换完

shell脚本之数组基本操作及排序的更多相关文章
- Shell脚本学习-数组
跟着RUNOOB网站的教程学习的笔记 Shell数组 数组中可以存放多个值,Bash Shell只支持一维数组(不支持多维数组),初始化时不需要定义数组大小(与PHP类似). 与大部分编程语言类似,数 ...
- shell脚本中数组array常用技巧学习实践
shell中数组的下标默认是从0开始的 1.将字符串放在数组中,获取其长度 #!/bin/bashstr="a b --n d"array=($str)length=${#arra ...
- Linux Shell脚本编程-数组和字符串处理
数组 1.数组的定义及声明 变量:存储单个元素的内存空间 数组:存储多个元素的连续的内存空间,相当于多个变量的集合 数组名:整个数组只有一个名字 索引:编号从0开始,属于数值索引:bash的数组支持 ...
- shell脚本编程数组
数组: 变量:存储单个元素的内存空间 数组:存储多个元素的连续的内存空间,相当于多个变量的集合 数组名和索引 索引:编号从0开始,属于数值索引 注意:索引可支持使用自定义的格式,而不仅是数值格式,即为 ...
- Shell脚本(四)数组
平时写脚本还没有用到过数组,暂时先记录下用法. #!/bin/bash array1=( ) array1_length=${#array1[@]} echo "array1 length: ...
- shell脚本之数组
变量:存储单个元素的内存空间. 数组:存储多个元素的连续的内存空间. 数组名:整个数组只有一个名字: 数组索引:编号从0开始: 数组名[索引]: 引用数组中的某个元素:${ ARRAY_NAME [ ...
- Linux 命令详解(十)Shell脚本的数组详解
1.数组定义 [root@bastion-IDC ~]# a=( ) [root@bastion-IDC ~]# echo $a 一对括号表示是数组,数组元素用“空格”符号分割开. 2.数组读取与赋值 ...
- Linux shell脚本中 数组的声明:
数组的声明: 1)array[key]=value # array[0]=one,array[1]=two 复制代码 2)declare -a array # array被当作数组名 复制代码 3)a ...
- shell 脚本获取数组字符串长度
#!/bin/sh source /etc/init.d/functions funOne() { array=(I am dfh kjlhfjksdf sdfj jdkfhaskl mjjoldfu ...
随机推荐
- Linux-saltstack-4 jinjia模板得基本使用
@ 目录 一.简介 二.jinja2语法 1.jinja2变量 1.1 配置文件中使用jinja变量 1.2在脚本中定义jinja变量 1.3在脚本中设置grains变量 例子1:单值 例子2:多值 ...
- react中关于create-react-app2里css相关配置
先看 webpack.config.dev.js 里的相关代码: // style files regexes const cssRegex = /\.css$/; const cssModuleRe ...
- 日志收集系统系列(三)之LogAgent
一.什么是LogAhent 类似于在linux下通过tail的方法读日志文件,将读取的内容发给kafka,这里的tailf是可以动态变化的,当配置文件发生变化时,可以通知我们程序自动增加需要增加的配置 ...
- angularJS中$digest already in progress报错解决方法
看到一个前端群里有人问,就查了下解决"$digest already in progress"最好的方式,就是不要使用$scope.$apply()或者$scope.$digest ...
- 若依(ruoyi)代码生成树表结构的那些坑
若依(RuoYI)代码生成树表结构的那些坑 相信许多做后端开发的同学,一定用过若依这款框架,这款框架易上手,适合用来做后台管理系统,但是其中也存在一些坑,稍不注意就会中招(大佬可以忽略...) 今天, ...
- IPOPT安装
1.安装工具coinbrew 打开网页,找到以下网址 将网站中的内容全部复制到自己创建的coinbrew文件中,并且赋予权限 chmod u+x coinbrew 或者执行 git clone htt ...
- leetcode 28. 实现 strStr()
问题描述 实现 strStr() 函数. 给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始).如果不 ...
- 【刷题-LeetCode】275. H-Index II
H-Index II Given an array of citations sorted in ascending order (each citation is a non-negative in ...
- ROS之face recongination(cbo_peopel_detection)
一准备 Ros的cbo_people_detection网站http://wiki.ros.org/cob_people_detection 某网站来自Amir:http://edu.gaitech. ...
- 前端3D引擎-Cesium自定义动态材质
本文代码基于Vue-cli4和使用WebGL的地图引擎Cesium,主要内容为三维场景下不同对象的动态材质构建. 参考了很多文章,链接附在文末. 为不同的几何对象添加动态材质 不知道这一小节的名称概况 ...