Kafka和Stream架构的使用
Kafka的单节点运行
启动服务
Kafka 使用 ZooKeeper 如果你还没有 ZooKeeper 服务器,你需要先启动一个 ZooKeeper 服务器。 您可以通过与 kafka 打包在一起的便捷脚本来快速简单地创建一个单节点 ZooKeeper 实例。如果你有使用docker 的经验,你可以使用 docker-compose 快速搭建一个 zk 集群。
bin/zookeeper-server-start.shconfig/zookeeper.properties
现在启动 Kafka 服务器:
> bin/kafka-server-start.sh config/server.properties
创建一个topic
创建一个名为“test”的 topic,它有一个分区和一个副本:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
运行 list(列表)命令来查看这个 topic:
bin/kafka-topics.sh --list --zookeeper localhost:2181 test
查询topic内容:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topicName --from-beginning
除了手工创建 topic 外,你也可以配置你的 broker,当发布一个不存在的 topic 时自动创建 topic。
开启生产者 发送消息
Kafka 自带一个命令行客户端,它从文件或标准输入中获取输入,并将其作为 message(消息)发送到Kafka 集群。默认情况下,每行将作为单独的 message 发送。
运行 producer,然后在控制台输入一些消息以发送到服务器。
生产者不依赖zookeeper,都会发送给leader
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test

启动消费者
Kafka 还有一个命令行使用者,它会将消息转储到标准输出。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning

如果在不同的终端中运行上述命令,能够在生产者终端中键入消息并看到它们出现在消费者终端中。
所有命令行工具都有选项; 运行不带参数的命令将显示使用信息
查看Topic信息
运行命令“describe topics” 查看集群中的 topic 信息

只有一个分区一个副本,Partition在broker0里面,后面的0都是borkerID
- “leader”是负责给定分区所有读写操作的节点。每个节点都是随机选择的部分分区的领导者。
- “replicas”是复制分区日志的节点列表,不管这些节点是 leader 还是仅仅活着。
- “isr”是一组“同步”replicas,是 replicas 列表的子集,它活着并被指到 leader。
Kafka Stream
Stream例子
Kafka Streams 是一个客户端库,用于构建任务关键型实时应用程序和微服务,其中输入和/或输出数据存储在 Kafka 集群中。Kafka Streams 结合了在客户端编写和部署标准 Java 和 Scala 应用程序的简单性以及 Kafka 服务器端集群技术的优势,使这些应用程序具有高度可扩展性,弹性,容错性,分布式等等。
以下是WordCountDemo示例代码的要点(为了方便阅读,使用的是 java8 lambda 表达式)。
启动 zk 和 kafka
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
准备输入主题并启动生产者
创建名为 streams-plaintext-input 的输入主题和名为 streams-wordcount-output 的输出主题:
> bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
Created topic "streams-plaintext-input".
注意:我们创建输出主题并启用压缩,因为输出流是更改日志流
> bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
Created topic "streams-wordcount-output".
使用相同的 kafka-topics 工具描述创建的主题:
bin/kafka-topics.sh --zookeeper localhost:2181 --describe
启动 Wordcount 应用程序
bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
演示应用程序将从输入主题 stream-plaintext-input 读取,对每个读取消息执行 WordCount 算法的计算,并将其当前结果连续写入输出主题 streams-wordcount-output。
处理数据
开启一个生产者终端:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
all streams lead to kafka
开启一个消费者终端:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
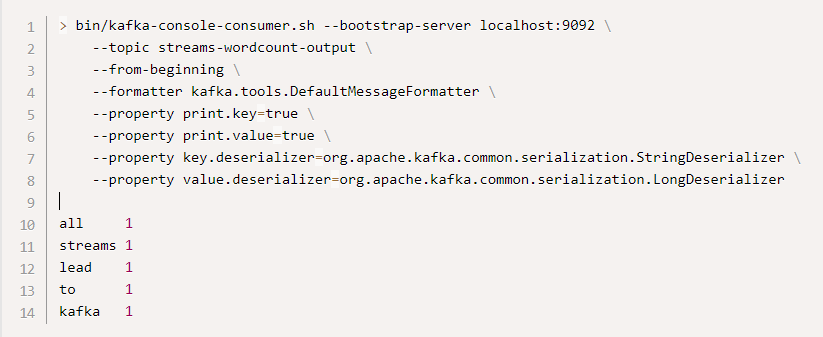
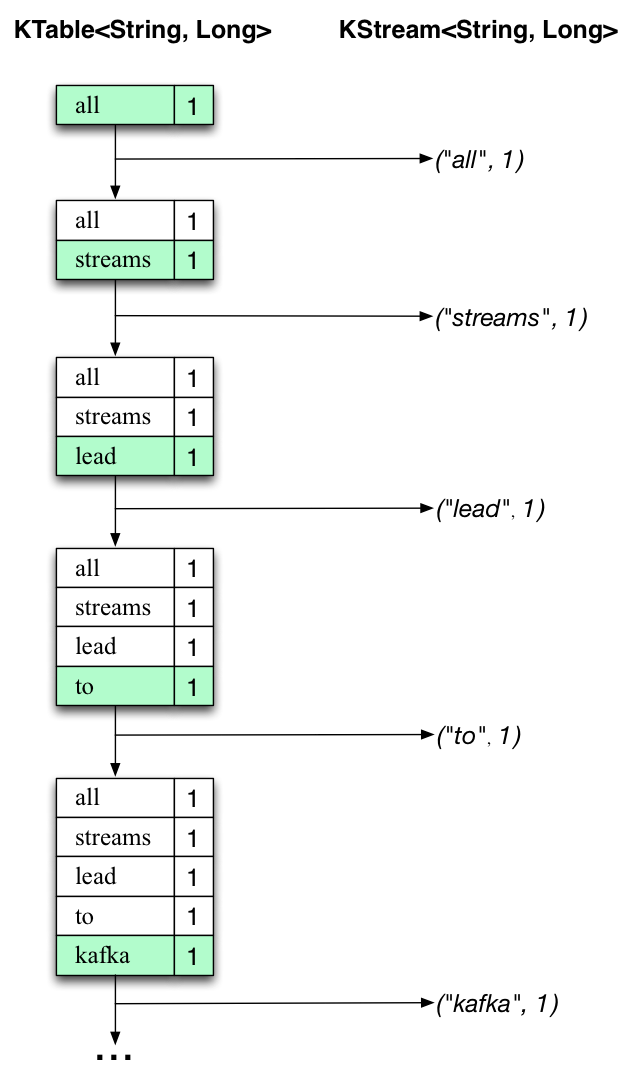
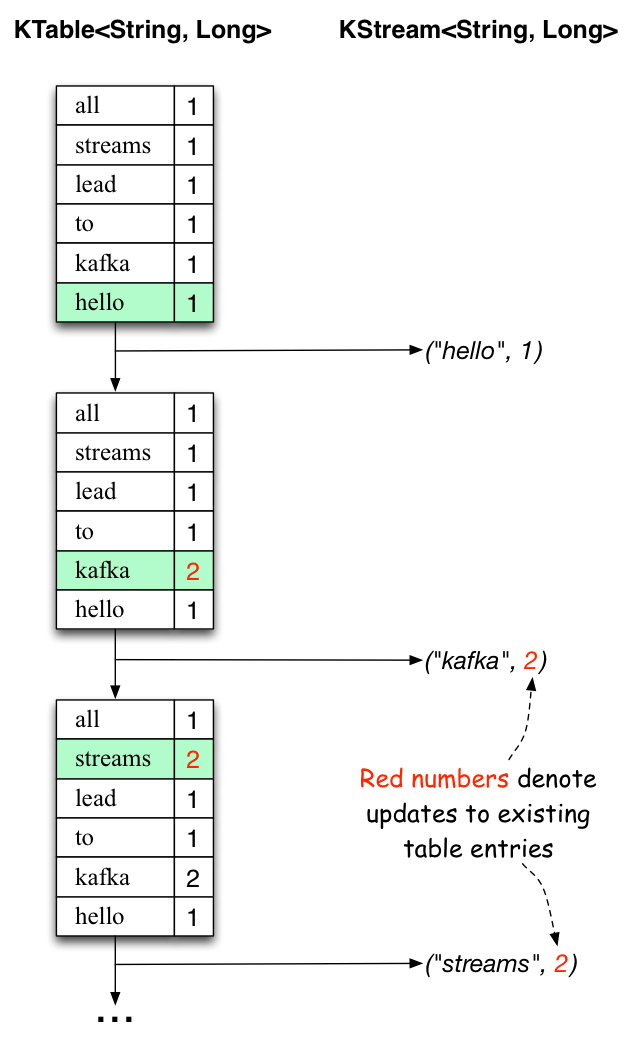
这里,第一列是 java.lang.String 格式的 Kafka 消息键,表示正在计数的单词,第二列是 java.lang.Long
格式的消息值,表示单词的最新计数。
package com.study.kafka.stream.wordcount;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Produced;
import java.util.Arrays;
import java.util.Locale;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
/**
* Demonstrates, using the high-level KStream DSL, how to implement the WordCount program
* that computes a simple word occurrence histogram from an input text.
* <p>
* In this example, the input stream reads from a topic named "streams-plaintext-input", where the values of messages
* represent lines of text; and the histogram output is written to topic "streams-wordcount-output" where each record
* is an updated count of a single word.
* <p>
* Before running this example you must create the input topic and the output topic (e.g. via
* {@code bin/kafka-topics.sh --create ...}), and write some data to the input topic (e.g. via
* {@code bin/kafka-console-producer.sh}). Otherwise you won't see any data arriving in the output topic.
*/
public final class WordCountDemo {
public static void main(final String[] args) {
final Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.100.249:9092");
props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
// setting offset reset to earliest so that we can re-run the demo code with the same pre-loaded data
// Note: To re-run the demo, you need to use the offset reset tool:
// https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Streams+Application+Reset+Tool
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
final StreamsBuilder builder = new StreamsBuilder();
final KStream<String, String> source = builder.stream("streams-plaintext-input");
final KTable<String, Long> counts = source
.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split(" ")))
.groupBy((key, value) -> value)
.count();
// need to override value serde to Long type
counts.toStream().to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
final KafkaStreams streams = new KafkaStreams(builder.build(), props);
final CountDownLatch latch = new CountDownLatch(1);
// attach shutdown handler to catch control-c
Runtime.getRuntime().addShutdownHook(new Thread("streams-wordcount-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (final Throwable e) {
System.exit(1);
}
System.exit(0);
}
}
Kafka和Stream架构的使用的更多相关文章
- Kafka设计解析(一)Kafka背景及架构介绍
转载自 技术世界,原文链接 Kafka设计解析(一)- Kafka背景及架构介绍 本文介绍了Kafka的创建背景,设计目标,使用消息系统的优势以及目前流行的消息系统对比.并介绍了Kafka的架构,Pr ...
- Kafka剖析:Kafka背景及架构介绍
<Kafka剖析:Kafka背景及架构介绍> <Kafka设计解析:Kafka High Availability(上)> <Kafka设计解析:Kafka High A ...
- 1.1 Introduction中 Kafka for Stream Processing官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Kafka for Stream Processing kafka的流处理 It i ...
- 【原创】阿里三面:搞透Kafka的存储架构,看这篇就够了
阅读本文大约需要30分钟.这篇文章干货很多,希望你可以耐心读完. 你好, 我是华仔,在这个 1024 程序员特殊的节日里,又和大家见面了. 从这篇文章开始,我将对 Kafka 专项知识进行深度剖析, ...
- Kafka设计解析(一)- Kafka背景及架构介绍
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/01/02/Kafka深度解析 背景介绍 Kafka简介 Kafka是一种分布式的,基于发布/订阅 ...
- Kafka剖析(一):Kafka背景及架构介绍
http://www.infoq.com/cn/articles/kafka-analysis-part-1/ Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平 ...
- [Big Data - Kafka] Kafka剖析(一):Kafka背景及架构介绍
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- Kafka学习笔记之Kafka背景及架构介绍
0x00 概述 本文介绍了Kafka的创建背景,设计目标,使用消息系统的优势以及目前流行的消息系统对比.并介绍了Kafka的架构,Producer消息路由,Consumer Group以及由其实现的不 ...
- kafka原理和架构
转载自: https://blog.csdn.net/lp284558195/article/details/80297208 参考: https://blog.csdn.net/qq_2059 ...
随机推荐
- NGK算力持有好处多多!SPC、VAST等免费拿!
众所周知,NGK是分布式存储的,作为Web3.0以及数字经济时代的基础设施,为数字加密市场带来了全新的商业模式和经济业态,但是,这只是一个重要的起点,真正的价值还在后面! 为了满足NGK生态建设者强烈 ...
- JULLIAN MURPHY:拥有良好的心态,运气福气便会自来
JULLIAN MURPHY是星盟全球投资公司的基金预审经理,负责星盟投资项目预审,有着资深的基金管理经验,并且在区块链应用的兴起中投资了多个应用区块链技术的公司. JULLIAN MURPHY认为往 ...
- 对Innodb中MVCC的理解
一.什么是MVCC MVCC (Multiversion Concurrency Control) 中文全程叫多版本并发控制,是现代数据库(如MySql)引擎实现中常用的处理读写冲突的手段,目的在于提 ...
- 如何在一台开发机中同时配置github、gitlab等多个账户
本文参考博文. 如果公司的代码同步环境在gitlab上,而自己有很多项目托管在github.我们需要做一些额外的配置实现两者的无缝切换. 步骤 我的开发机是macbook,如果属于不同系统,找到该系统 ...
- 力扣1438. 绝对差不超过限制的最长连续子数组-C语言实现-中等难度
题目 传送门 文本 给你一个整数数组 nums ,和一个表示限制的整数 limit,请你返回最长连续子数组的长度,该子数组中的任意两个元素之间的绝对差必须小于或者等于 limit . 如果不存在满足条 ...
- 010_HTML5
目录 初识HTML 什么是HTML HTML发展史 HTML5的优势 W3C标准 常见IDE IDEA开发HTML IDEA创建HTML文件,并用浏览器打开 配置浏览器 HTML基础 HTML基本结构 ...
- 关于各种Formatting context
Formatting context 我们把网页看作是由很多个盒子组成的,而这些盒子的展示方式,就是由display这个属性来决定的. 这里出现了一个概念,叫做Formatting context(格 ...
- canal数据同步的环境配置
canal数据同步的环境配置:(适用于mysql) 前提:在linux和windows系统的mysql数据库中创建相同结构的数据库和表,我的linux中mysql是用docker实现的(5.7版本), ...
- 微信小程序(六)-项目实例(原生框架 MINA基配搭建)==01-头搜索框tabbar
项目实例(原生框架 MINA) 1.新建小程序项目 1.用自已的小程序APPID 2.清除整理项目中初建默认无关的代码 1.app.json 中删除logs,同时删除pages下的losgs文件夹 2 ...
- Rocket broker启动失败?
安装 Rocket 时, 执行 nohup sh bin/mqbroker -n localhost:9876 & 启动 broker 失败 更改其内存试试 在下面目录下 : cd distr ...