HashMap扩容和ConcurrentHashMap
HashMap
存储结构
HashMap是数组+链表+红黑树(1.8)实现的。
(1)Node[] table,即哈希桶数组。Node是内部类,实现了Map.Entry接口,本质是键值对。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //用来定位数组索引位置
final K key;
V value;
Node<K,V> next; //链表的下一个node
Node(int hash, K key, V value, Node<K,V> next) { ... }
public final K getKey(){ ... }
public final V getValue() { ... }
public final String toString() { ... }
public final int hashCode() { ... }
public final V setValue(V newValue) { ... }
public final boolean equals(Object o) { ... }
}
下图链表中的Node节点
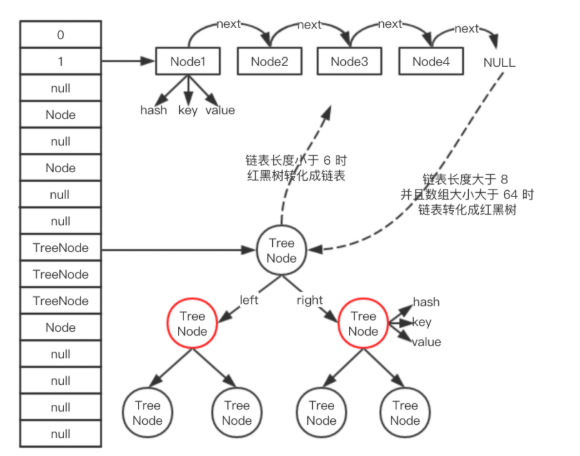
(2)Node[] table初始化长度为16,负载因子是0.75,threshold是HashMap容纳的最大Node个数,threshold = length * Load factor。
int threshold; // 所能容纳的key-value对极限
final float loadFactor; // 负载因子
int modCount;
int size;
功能实现-方法
扩容机制
1.7
1 void resize(int newCapacity) { //传入新的容量
2 Entry[] oldTable = table; //引用扩容前的Entry数组
3 int oldCapacity = oldTable.length;
4 if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
5 threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
6 return;
7 }
8
9 Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
10 transfer(newTable); //!!将数据转移到新的Entry数组里
11 table = newTable; //HashMap的table属性引用新的Entry数组
12 threshold = (int)(newCapacity * loadFactor);//修改阈值
13 }
这里就是使用一个容量更大的数组来代替已有的容量小的数组,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里。
1 void transfer(Entry[] newTable) {
2 Entry[] src = table; //src引用了旧的Entry数组
3 int newCapacity = newTable.length;
4 for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
5 Entry<K,V> e = src[j]; //取得旧Entry数组的每个元素
6 if (e != null) {
7 src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
8 do {
9 Entry<K,V> next = e.next;
10 int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
11 e.next = newTable[i]; //标记[1]
12 newTable[i] = e; //将元素放在数组上
13 e = next; //访问下一个Entry链上的元素
14 } while (e != null);
15 }
16 }
17 }
newTable[i]的引用赋给e.next,也就是头插法。
扩容过程:假设hash算法是简单的用key mod一下表的大小(数组长度)。数组长度为2,所以key=3、7、5,put顺序为5、7、3。在mod 2以后都冲突在table[1]这里了。这里假设负载因子 loadFactor=1,即当键值对的实际大小size 大于 table的实际大小时进行扩容。接下来的三个步骤是哈希桶数组 resize成4,然后所有的Node重新rehash的过程。

1.8
使用2次幂的扩展,所以,元素的位置要么是原位置,要么是在原位置再移动2次幂的位置。
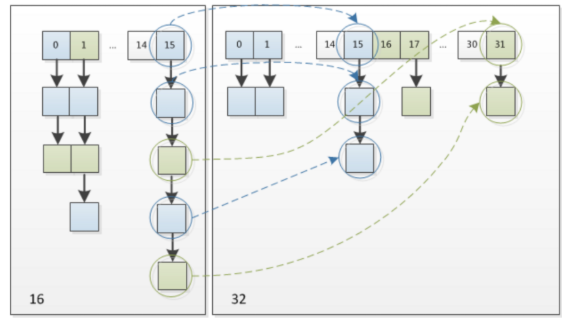
这个设计既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的
过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。
有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表
元素会倒置,但是从DK1.8不会倒置(尾插法)。
ConcurrentHashMap
1.put方法
1.1 数组初始化时的线程安全
数组初始化时,首先通过自旋保证一定可以初始化成功,然后通过CAS设置SIZECTL变量的值,保证同一时刻只能
有一个线程对数组进行初始化,CAS成功之后,会再次判断当前数组是够初始化完成。通过自旋 + CAS + 双重
check保证了数组初始化时的线程安全。
1.2 新增槽点值时的线程安全
通过自旋死循环保证一定可以新增成功。
当前槽点为空时,通过CAS新增。
当前槽点有值,锁住当前槽点。
put 时,如果当前槽点有值,就是 key 的 hash 冲突的情况,此时槽点上可能是链表或红黑树,我们通过锁住槽点,来保证同一时刻只会有一个线程能对槽点进行修改。
- 红黑树旋转时,锁住红黑树的根节点,保证同一时刻,当前红黑树只能被一个线程旋转。
以上4点保证在各种情况下,都是线程安全的,通过自旋 + CAS + 锁。
1.3 扩容时的线程安全
ConcurrentHashMap 扩容的方法交transfer,思路:
- 首先把老数组的值全部拷贝到扩容的新数组上,从数组的队尾开始拷贝;
- 拷贝数组的槽点时,先把原数组槽点锁住,保证原数组槽点不能操作,拷贝到新数组时,把原数组槽点复制为转移节点;
- 这时如果有新数据正好put到此槽点时,发现槽点为转移节点,就会一直等待,所以在扩容完成之前,槽点对应的数据不会变化;
- 从数组的尾部拷贝到头部,每拷贝成功一次,就把原数组中的节点设置为转移节点;
- 直到所有数组数据都拷贝到新数组时,直接把新数组整个复制给数组容器,拷贝完成。
资料
- 美团HashMap
- 慕课网专栏Java源码解析
HashMap扩容和ConcurrentHashMap的更多相关文章
- HashMap扩容死循环问题
原文:https://blog.csdn.net/Leon_cx/article/details/81911223 下面我们来模拟一下多线程场景下扩容会出现的问题: 假设在扩容过程中旧hash桶中有一 ...
- 面试笔记--HashMap扩容机制
转载请注明出处 http://www.cnblogs.com/yanzige/p/8392142.html 扩容必须满足两个条件: 1. 存放新值的时候当前已有元素的个数必须大于等于阈值 2. 存放新 ...
- JDK1.8 HashMap 扩容 对链表(长度小于默认的8)处理时重新定位的过程
关于HashMap的扩容过程,请参考源码或百度. 我想记录的是1.8 HashMap扩容是对链表中节点的Hash计算分析. 对术语先明确一下: hash计算指的确定节点在table[index]中的链 ...
- Redis的字典扩容与ConcurrentHashMap的扩容策略比较
本文介绍Redis的字典(是种Map)扩容与ConcurrentHashMap的扩容策略,并比较它们的优缺点. (不讨论它们的实现细节) 首先Redis的字典采用的是一种‘’单线程渐进式rehash‘ ...
- 关于JDK1.8 HashMap扩容部分源码分析
今天回顾hashmap源码的时候发现一个很有意思的地方,那就是jdk1.8在hashmap扩容上面的优化. 首先大家可能都知道,1.8比1.7多出了一个红黑树化的操作,当然在扩容的时候也要对红黑树进行 ...
- Java8中HashMap扩容算法小计
Java8的HashMap扩容过程主要就是集中在resize()方法中 final Node<K,V>[] resize() { // ...省略不重要的 } 其中,当HashMap扩容完 ...
- ArrayList && HashMap扩容策略
ArrayList扩容策略:默认10 扩容时是base + base/2, 即10 15 22 33 49...扩容时不安全:grow方法扩容时,赋值 elementData = Arrays.cop ...
- HashSet保证元素唯一原理以及HashMap扩容机制
一.HashSet保证元素唯一原理: 依赖于hashCode()和equals()方法1.唯一原理: 1.1 当HashSet集合要存储元素的时候,会调用该元素的hashCode()方法计算哈希值 1 ...
- HashMap的扩容机制, ConcurrentHashMap和Hashtable主要区别
源代码查看,有三个常量, static final int DEFAULT_INITIAL_CAPACITY = 16; static final int MAXIMUM_CAPACITY = 1 & ...
随机推荐
- Java常用类之时间类
JDK8之前日期时间API 1. java.lang.System类 2. java.util.Date类 3. java.text.SimpleDateFormat类 4. java.util.Ca ...
- Js/jquery常用
id属性不能有空格 1. js判断checkebox是否被选中 var ischecked = document.getElementById("xxx").checked // ...
- jQuery中的基本选择器(四、一):* 、 . 、element(直接标签名)、 或者用逗号隔开跟多个
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- RabitMq过期时间TTL
第一种:给消息设置过期时间 启动一个插件 @Bean public DirectExchange DirectExchange() { return new DirectExchange(" ...
- 修改Windows7系统默认软件安装目录
Windows7系统默认软件安装目录都在C盘Program Files文件夹有时候我们需要把软件安装到其他地方,如果每次安装的时候都要重新选择一次十分麻烦,下面Windows7之家教你修改软件默认安装 ...
- 实例说明C++的virtual function的作用以及内部工作机制初探
C++为何要引入virtual function? 来看一个基类的实现: 1 class CBase 2 { 3 public: 4 CBase(int id) : m_nId(id), m_pBas ...
- Java并发之AQS原理解读(三)
上一篇:Java并发之AQS原理解读(二) 前言 本文从源码角度分析AQS共享锁工作原理,并介绍下使用共享锁的子类如何工作的. 共享锁工作原理 共享锁与独占锁的不同之处在于,获取锁和释放锁成功后,都会 ...
- 安全强化机制——SELinux
1.基本 SELINUX 安全性概念 SELINUX(Security Enhanced Linux),意思是安全增强型Linux, 是可保护你系统安全性的额外机制 在某种程度上 , 它可以被看作是与 ...
- JS 之 每日一题 之 算法 ( 有多少小于当前数字的数字 )
给你一个数组 nums,对于其中每个元素 nums[i],请你统计数组中比它小的所有数字的数目. 换而言之,对于每个 nums[i] 你必须计算出有效的 j 的数量,其中 j 满足 j != i 且 ...
- Linux命令进阶篇之一
利用file命令查看那文件的类型 cd /etc 这里面的文件 命令:file 语法:file [-bLvz] 文件 解释:-b:显示结果,但是不显示文件名称 -L:直接显示符号链接所指向的文件的类型 ...