腾讯云原生混合云-第三方集群弹EKS应对突发流量的利器
作者
何鹏飞,腾讯云专家产品经理,曾作为容器私有云、TKEStack的产品经理兼架构师,参与腾讯云内部业务、外部客户容器化改造方案设计,目前负责云原生混合云产品方案设计工作。
胡晓亮,腾讯云专家工程师,专注云原生领域。目前负责开源社区TKEStack和混合云项目的设计和开发工作。
前言
混合云是一种部署形态,一方面企业可从资产利旧、成本控制、控制风险减少锁定等角度选择混合云。另一方面企业也可以通过混合业务部署获得不同云服务商的相对优势能力,以及让不同云服务商的能力差异形成互补。 而容器和混合云是天作之合,基于容器标准化封装,大大降低了应用运行环境与混合云异构基础设施的耦合性,企业更易于实现多云/混合云敏捷开发和持续交付,使应用多地域标准管理化成为可能。
TKE 容器团队提供了一系列的产品能力来满足混合云场景,本文介绍其中针对突发流量场景的产品特性——第三方集群弹 EKS。
低成本扩容
IDC 的资源是有限的,当有业务突发流量需要应对时,IDC 内的算力资源可能不足以应对。选择使用公有云资源应对临时流量是不错的选择,常见的部署架构为:在公有云新建一个集群,将部分工作负载部署到云上,通过 DNS 规则或负载均衡策略将流量路由到不同的集群:
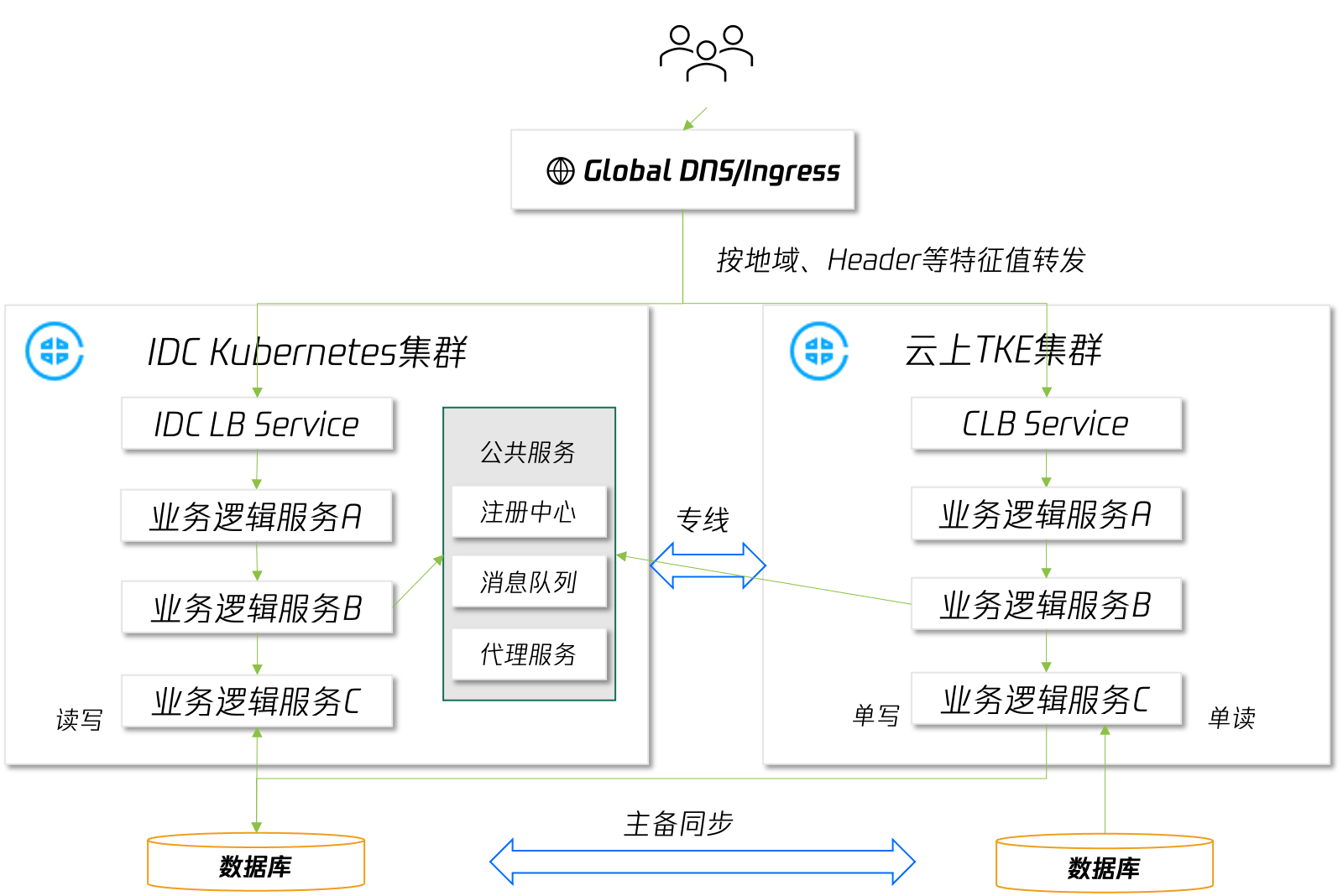
此种模式下,业务的部署架构发生了变化,因此在使用前需要充分评估:
- 哪些业务工作负载需要在云上部署,是全部还是部分;
- 云上部署的业务是否有环境依赖,例如 IDC 内网 DNS、DB、公共服务等;
- 云上、云下业务日志、监控数据如何统一展示;
- 云上、云下业务流量调度规则;
- CD 工具如何适配多集群业务部署;
这样的改造投入对于需要长期维持多地域接入的业务场景来说是值得的,但对于突发流量业务场景来说成本较高。因此我们针对这种场景推出了便捷在单集群内利用公有云资源应对突发业务流量的能力:第三方集群弹 EKS,EKS是腾讯云弹性容器服务,可以秒级创建和销毁大量 POD 资源,用户仅需提出 POD 资源需求即可,无需维护集群节点可用性,对于弹性的场景来说是非常合适的。仅需要在集群中安装相关插件包即可快速获得扩容到 EKS 的能力。
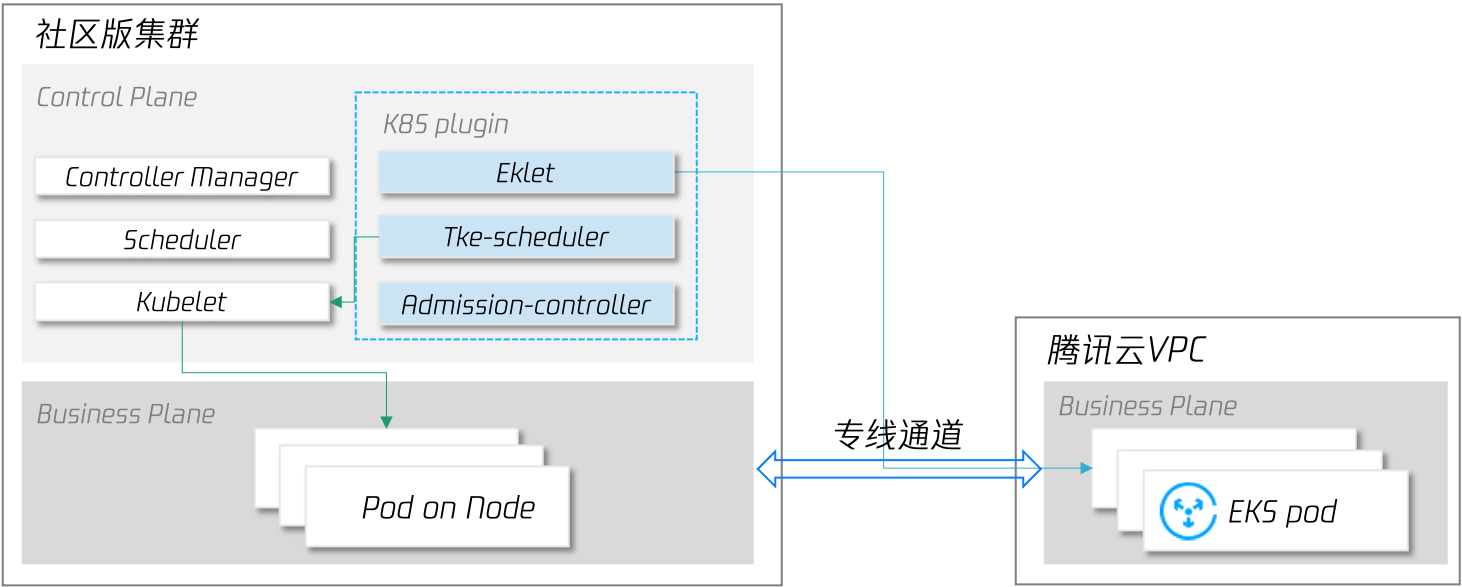
与直接使用云上虚拟机节点相比,此种方式扩缩容更快,并且我们还提供了2种调度机制来满足客户的调度优先级需求:
全局开关: 在集群层面,当集群资源不足时,任何需要新创建Pod的工作负载都可以将副本创建到腾讯云 EKS 上;
局部开关: 在工作负载层面,用户可指定单个工作负载在本集群保留N个副本后,其他副本在腾讯云 EKS 中创建;
为了确保所有工作负载在本地 IDC 均有足够的副本数,当突发流量过去,触发缩容时,支持优先缩容腾讯云上 EKS 副本(需要使用 TKE 发行版集群,关于 TKE 发行版的详细介绍,请期待后续发布的该系列文章)。
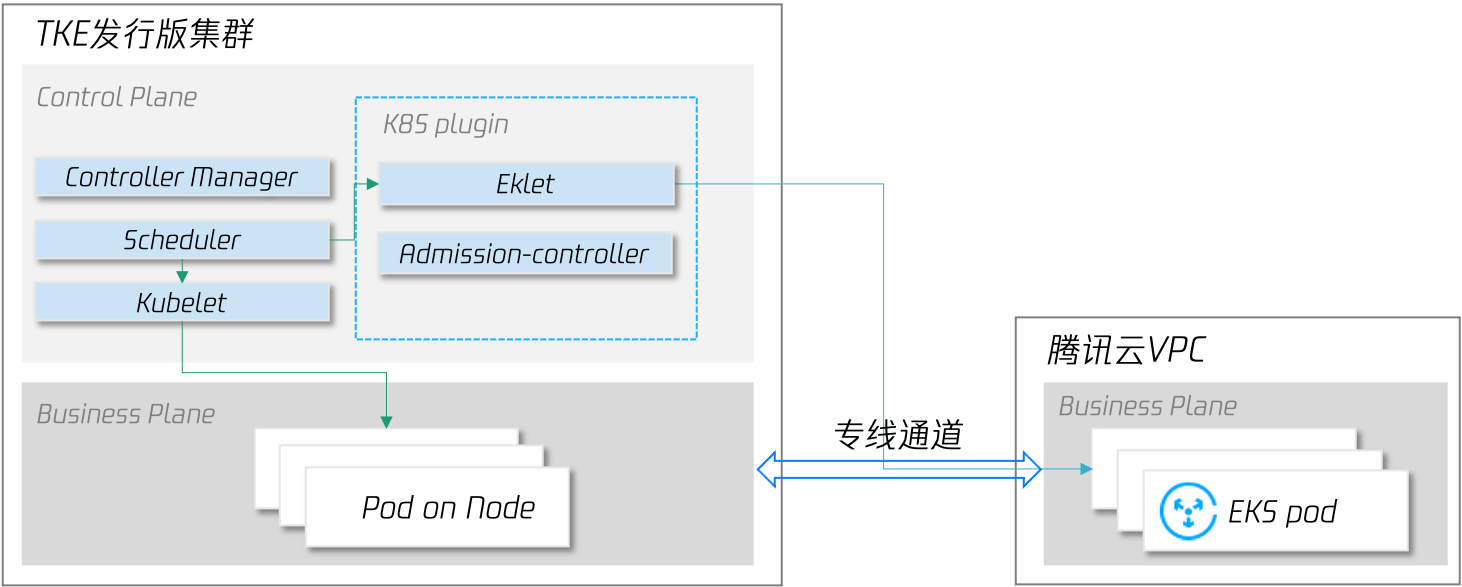
这种模式下,业务部署架构没有发生变化,在单集群中即可弹性使用云上资源,避免了引入业务架构改造、CD流水线改造、多集群管理、监控日志统等一系列衍生问题,并且云上资源的使用是按需使用,按需计费,大大降低了用户使用成本。但为了保障工作负载的安全性和稳定性,我们要求用户的 IDC 与腾讯云公有云 VPC 专线互通,并且用户也需要从存储依赖、延时容忍度等多方面评估适用性。
EKS pod 可与 underlay 网络模式的本地集群 pod、node 互通(需要在腾讯云VPC中添加本地pod cidr的路由,参考路由配置),第三方集群弹 EKS 已在 TKEStack中开源,详细使用方式和示例见 使用文档
实战演示
步骤
获取 tke-resilience helm chart
git clone https://github.com/tkestack/charts.git
配置 VPC 信息:
编辑 charts/incubator/tke-resilience/values.yaml,填写以下信息:
cloud:
appID: "{腾讯云账号APPID}"
ownerUIN: "{腾讯云用户账号ID}"
secretID: "{腾讯云账号secretID}"
secretKey: "{腾讯云账号secretKey}"
vpcID: "{EKS POD放置的VPC ID}"
regionShort: {EKS POD 放置的region简称}
regionLong: {EKS POD 放置的region全称}
subnets:
- id: "{EKS POD 放置的子网ID}"
zone: "{EKS POD 放置的可用区}"
eklet:
podUsedApiserver: {当前集群的API Server地址}
安装 tke-resilience helm chart
helm install tke-resilience --namespace kube-system ./charts/incubator/tke-resilience/
确认 chart pod 工作正常

创建 demo 应用 nginx:ngx1
效果演示:
全局调度
由于此特性默认已开启,我们先将kube-system 中 的 AUTO_SCALE_EKS 设置为 false
默认情况下,ngx1 副本数为1

将ngx1副本数调整为50
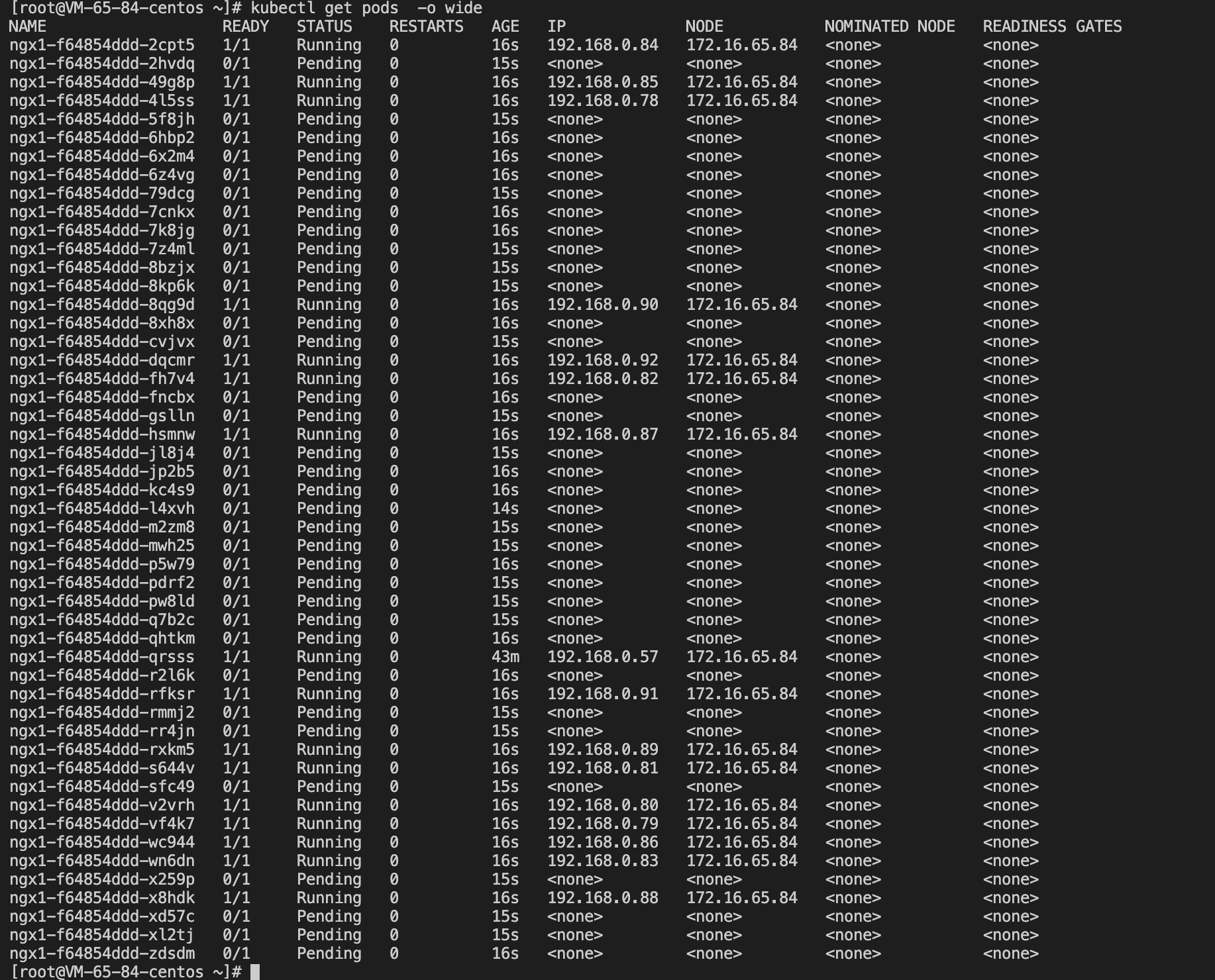
可以看到有大量 POD 因为资源不足,处于 pending 状态
将 kube-system 中 的 AUTO_SCALE_EKS 设置为 true 后,短暂等待后,观察pod状态,原本处于 pend的pod,被调度到了 EKS 虚拟节点:eklet-subnet-167kzflm 上。
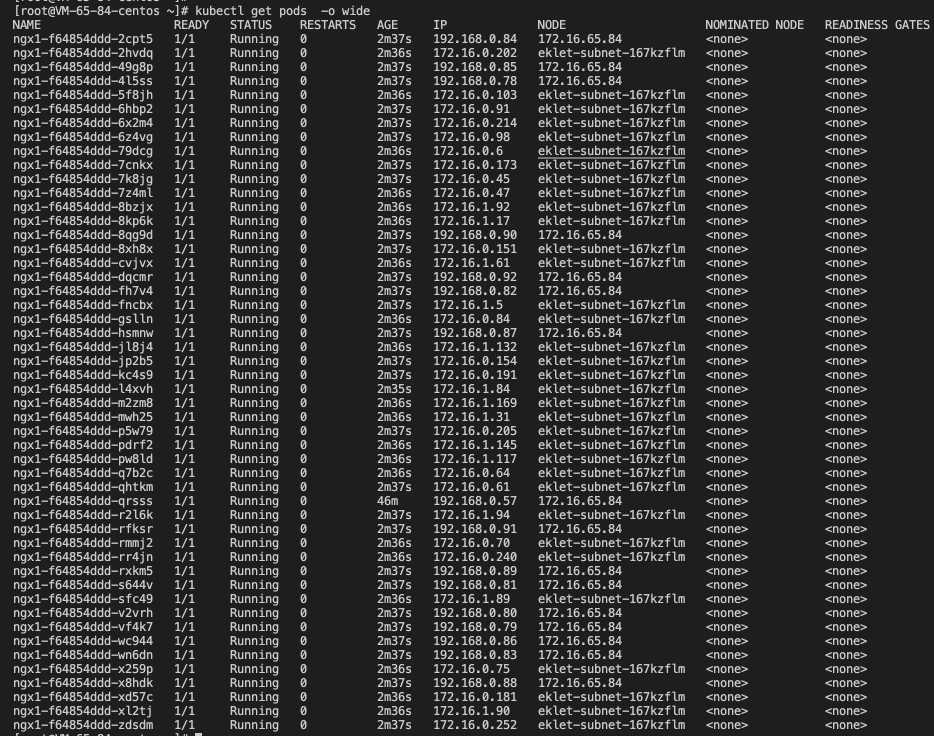
指定调度
我们再次将 ngx1 的副本数调整为1

编辑 ngx1 yaml,设置开启局部开关
spec:
template:
metadata:
annotations:
# 打开局部开关
AUTO_SCALE_EKS: "true"
# 设置需要在本地集群创建的副本个数
LOCAL_REPLICAS: "2""
spec:
# 使用tke调度器
schedulerName: tke-scheduler
将 ngx1 副本数改为3,尽管本地集群没有出现资源不足,但可以看到,超过2个本地副本后,第三个副本被调度到了EKS上

卸载 tke-resilience 插件
helm uninstall tke-resilience -n=kube-system
此外 TKEStack 已集成 tke-resilience,用户可以在 TKEStack 的应用市场中界面化安装 tke-resilience
应用场景
云爆发
电商促销、直播等需要在短时间扩容大量临时工作负载的场景,这种场景下,资源需求时间非常短,为了应对这种短周期需求而在日常储备大量资源,势必会有比较大的资源浪费,且资源需求量随每次活动变化难以准确评估。使用此功能,您无需关注于资源筹备,仅需依靠K8S的自动伸缩功能,即可快速为业务创建出大量工作负载为业务保驾护航,流量峰值过去后,云上POD会可优先销毁,确保无资源浪费的情况。
离线计算
大数据、AI业务场景下,计算任务对算力亦有高弹性要求。为保障任务快速计算完成,需要在短时间能有大量算力支撑,而计算完成后,算力同样处于低负载状态,计算资源利用率呈高波动型,形成了资源浪费。并且由于GPU资源的稀缺性,用户自己囤积大量GPU设备不仅成本非常高,还会面临资源利用率提升,新卡适配,老卡利旧,异构计算等多种资源管理问题,而云上丰富的GPU卡型可为用户提供更多样的选择,即用即还的特性也确保了资源零浪费,每一分钱都真正化在真实的业务需求上。
未来演进
- 多地域支持,支持应用部署到云上多个区域,应用与地域关联部署等特性
- 云边结合,结合 TKE-Edge,针对弱网络场景提供应用部署、调度策略,摆脱专线依赖
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!

腾讯云原生混合云-第三方集群弹EKS应对突发流量的利器的更多相关文章
- 云原生分布式 PostgreSQL+Citus 集群在 Sentry 后端的实践
优化一个分布式系统的吞吐能力,除了应用本身代码外,很大程度上是在优化它所依赖的中间件集群处理能力.如:kafka/redis/rabbitmq/postgresql/分布式存储(CephFS,Juic ...
- 前端静态站点在阿里云自建 K8S DevOps 集群上优雅的进行 CI/CD
目录 网站 域名 K8S DevOps 集群 私有 Gitlab 使用 Docker 编译站点 * Dockerfile * 构建编译 Image * 测试编译 Image * 推送镜像到 Aliyu ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 阿里云ECS服务器部署HADOOP集群(六):Flume 安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 1 环境介绍 一台阿里云ECS服务器:master 操作系统:CentOS 7.3 Hadoop ...
- 阿里云ECS服务器部署HADOOP集群(七):Sqoop 安装
本篇将在 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper) 阿 ...
- 阿里云ECS服务器部署HADOOP集群(五):Pig 安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 1 环境介绍 一台阿里云ECS服务器:master 操作系统:CentOS 7.3 Hadoop ...
- 阿里云ECS服务器部署HADOOP集群(四):Hive本地模式的安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 本地模式需要采用MySQL数据库存储数据. 1 环境介绍 一台阿里云ECS服务器:master ...
随机推荐
- 操作系统实验(一)-Shell编程
操作系统实验:Shell编程 emmmmm,实验前老师发了一份实验说明,里面有教怎么配置虚拟机Ubuntu.这里就不做过多叙述,需要说明的是,kali和ubuntu都可以以shell运行这个C语言程序 ...
- 攻防世界 reverse 新手练习区
1.re1 DUTCTF IDA shift+F12 查看字符串 DUTCTF{We1c0met0DUTCTF} 2.game ZSCTF zsctf{T9is_tOpic_1s_v5ry_int7r ...
- Java应用性能瓶颈分析思路
1 问题描述 因产品架构的复杂性,可能会导致性能问题的因素有很多.根据部署架构,大致的可以分为应用端瓶颈.数据库端瓶颈.环境瓶颈三大类.可以根据瓶颈的不同部位,选择相应的跟踪工具进行跟踪分析. 应用层 ...
- java进阶(41)--反射机制
文档目录: 一.反射机制的作用 二.反射机制相关类 三.获取class的三种方式 四.通过反射实例化对象 五.通过读属性文件实例化对象 六.通过反射机制访问对象属性 七.通过反射机制调用方法 ---- ...
- 【linux】驱动-8-一文解决设备树
目录 前言 8. Linux设备树 8.1 设备树简介 8.2 设备树框架 8.2.1 设备树格式 8.2.1.1 DTS 文件布局 8.2.1.2 node 格式 8.2.1.3 propertie ...
- [GDKOI2021] 普及组 Day3 总结 && 题解
[ G D K O I 2021 ] 普 及 组 D a y 3 总 结 时间安排和昨天的GDKOI2021 Day2一样. 早上四个小时的快乐码题时间,然鹅我打了半小时的表 然后就是下午的题目讲解和 ...
- OLAP引擎:基于Presto组件进行跨数据源分析
一.Presto概述 1.Presto简介 Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节,Presto虽然具备解析SQL的能力,但它并不属于标准的数据库 ...
- (十七)VMware Harbor 垃圾清理
1. 在线垃圾清理 注意:从Harbor中删除镜像时不释放空间,垃圾收集是通过从清单中不再引用文件系统中删除blob来释放空间的任务. 注意:在执行垃圾收集时,Harbor将进入只读模式,并且禁止对d ...
- Salesforce学习之路(九)Org的命名空间
1. 命名空间的适用场景 每个组件都是命名空间的一部分,如果Org中设置了命名空间前缀,那么需使用该命名空间访问组件.否则,使用默认命名空间访问组件,系统默认的命名空间为"c". ...
- 《MySQL必知必会》学习笔记整理
简介 此笔记只包含<MySQL必知必会>中部分章节的整理笔记.这部分章节主要是一些在<SQL必知必会>中并未讲解的独属于 MySQL 数据库的一些特性,如正则表达式.全文本搜索 ...