【转】浅谈自动特征构造工具Featuretools
转自https://www.cnblogs.com/dogecheng/p/12659605.html
简介
特征工程在机器学习中具有重要意义,但是通过手动创造特征是一个缓慢且艰巨的过程。Python的特征工程库featuretools可以帮助我们简化这一过程。Featuretools是执行自动化特征工程的框架,有两类特征构造的操作:聚合(aggregation)和 转换(transform)。
示例
版本说明
python 3.7.6
featuretools==0.13.4
scikit-learn==0.22.2.post1
首先,我们得先了解一下featuretools的3个基本组成
- 实体集(EntitySet):把一个二维表看作一个实体,实体集是一个或多个二维表的集合
- 特征基元(Feature Primitives):分为聚合和转换两类,相当于构造新特征的方法
- 深度特征合成(DFS, Deep Feature Synthesis):根据实体集里的实体和特征基元创造新特征
单个数据表
max_depth=1
加载数据

from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
import featuretools as ft dataset = load_iris()
X = dataset.data
y = dataset.target
iris_feature_names = dataset.feature_names df = pd.DataFrame(X, columns=iris_feature_names)
用实体集表示数据集
import featuretools as ft
es = ft.EntitySet(id='single_dataframe') # 用id标识实体集
# 增加一个数据框,命名为iris
es.entity_from_dataframe(entity_id='iris',
dataframe=df,
index='index',
make_index=True)
选择特征基元并自动进行特征工程,我们这里采用加减乘除4个基元,max_depth控制“套娃”的深度,如果是1的话只在原特征上进行,大于1的话不仅会在原来的特征上,还会在其他基元生成的新特征上创造特征,数值越大,允许越深的“套娃”。
trans_primitives=['add_numeric', 'subtract_numeric', 'multiply_numeric', 'divide_numeric'] # 2列相加减乘除来生成新特征
# ft.list_primitives() # 查看可使用的特征集元
feature_matrix, feature_names = ft.dfs(entityset=es,
target_entity='iris',
max_depth=1, # max_depth=1,只在原特征上进行运算产生新特征
verbose=1,
trans_primitives=trans_primitives
)
我们知道加法和乘法满足交换律,而减法和除法不满足,以特征A和B为例,A+B的结果一定等于B+A,但是A-B不一定等于B-A。
按理说,不同基元操作后的总特征数:
加和乘的新特征数+原始特征数,feature_num*(feature_num-1)/2+feature_num,所以这里是4*3/2+4=10
减和除的新特征数+原始特征数,feature_num*(feature_num-1)+feature_num,所以这里是4*3+4=16
10*2+16*2-4*3=40,4*3减去重复的3原始特征3次
在0.13.4版本的featuretools中,默认减法满足交换律,因此实际生成的特征会少一些,只有34个特征。

下面是0.13.4版本的featuretools中的代码,subtract_numeric默认开启了交换律,我想因为 A-B = -(B-A) ,可以认为是一个特征,只不过一个是正相关一个是负相关。但是如果max_depth很深,差别会越来越大,如 A+B×(A-B) 和 A+B×(B-A) 。
class SubtractNumeric(TransformPrimitive):
name = "subtract_numeric"
input_types = [Numeric, Numeric]
return_type = Numeric def __init__(self, commutative=True):
self.commutative = commutative
...
如果想要全部特征,可以创建一个subtract_numeric的实例,让commutative参数为False,这时就会有40个特征了,这是预期的结果。
trans_primitives=['add_numeric', ft.primitives.SubtractNumeric(commutative=False), 'multiply_numeric', 'divide_numeric']
feature_matrix, feature_names = ft.dfs(entityset=es,
target_entity='iris',
max_depth=1,
verbose=1,
trans_primitives=trans_primitives
)
自动特征工程后,可能会出现 np.inf 和 np.nan 这样的异常值,我们需要处理这些异常数据。其中 np.inf 可能是由 n/0 导致的,np.nan 可能是由 0/0 导致的。
feature_matrix.replace([np.inf, -np.inf], np.nan) # np.inf都用np.nan代替
feature_matrix.isnull().sum()
max_depth不为1
如果我们的max_depth不为1,要知道特征基元的顺序是会带来影响的。另外就是如果max_depth数值大,特征基元多的话特征工程后的维度会迅速膨胀。下面的两个例子中,原来的特征只有4个,让max_depth为2且只用2个特征基元后特征就有100+了。
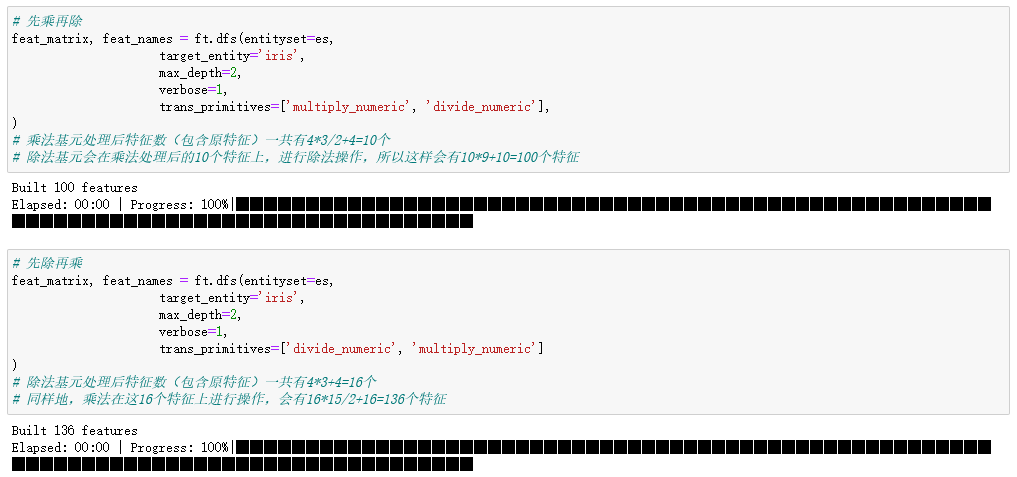
先乘再除
feat_matrix, feat_names = ft.dfs(entityset=es,
target_entity='iris',
max_depth=2,
verbose=1,
trans_primitives=['multiply_numeric', 'divide_numeric'],
)
# 乘法基元处理后特征数(包含原特征)一共有4*3/2+4=10个
# 除法基元会在乘法处理后的10个特征上,进行除法操作,所以这样会有10*9+10=100个特征
先除再乘
feat_matrix, feat_names = ft.dfs(entityset=es,
target_entity='iris',
max_depth=2,
verbose=1,
trans_primitives=['divide_numeric', 'multiply_numeric']
)
# 除法基元处理后特征数(包含原特征)一共有4*3+4=16个
# 同样地,乘法在这16个特征上进行操作,会有16*15/2+16=136个特征
多个数据表
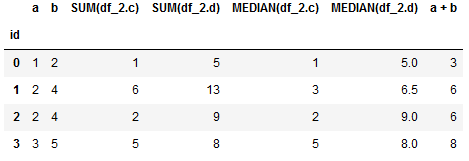
我们这里自定义2个数据表来表示。其中df_2中id就是df_1中的id
df_1 = pd.DataFrame({'id':[0,1,2,3], 'a':[1,2,2,3], 'b':[2,4,4,5]})
df_2 = pd.DataFrame({'id':[0,1,1,2,3], 'c':[1,3,3,2,5], 'd':[5,6,7,9,8]})
es = ft.EntitySet(id='double_dataframe')
es.entity_from_dataframe(entity_id='df_1', # 增加一个数据框
dataframe=df_1,
index='id')
es.entity_from_dataframe(entity_id='df_2', # 增加一个数据框
dataframe=df_2,
index='index',
make_index=True)
# 通过 id 关联 df_1 和 df_2 实体
relation = ft.Relationship(es['df_1']['id'], es['df_2']['id'])
es = es.add_relationship(relation)
聚合基元 sum 和 median 会将df_2中相同“id”的数据进行相加和取中位数的操作
trans_primitives=['add_numeric']
agg_primitives=['sum', 'median']
feature_matrix, feature_names = ft.dfs(entityset=es,
target_entity='df_1',
max_depth=1,
verbose=1,
agg_primitives=agg_primitives,
trans_primitives=trans_primitives)
【转】浅谈自动特征构造工具Featuretools的更多相关文章
- 浅谈自动特征构造工具Featuretools
简介 特征工程在机器学习中具有重要意义,但是通过手动创造特征是一个缓慢且艰巨的过程.Python的特征工程库featuretools可以帮助我们简化这一过程.Featuretools是执行自动化特征工 ...
- 浅谈独立特征(independent features)、潜在特征(underlying features)提取、以及它们在网络安全中的应用
1. 关于特征提取 0x1:什么是特征提取 特征提取研究的主要问题是,如何在数据集未明确表示结果的前提下,从中提取出重要的潜在特征来.和无监督聚类一样,特征提取算法的目的不是为了预测,而是要尝试对数据 ...
- 浅谈maven自动化构建工具
转载https://blog.csdn.net/zxm1306192988/article/details/76209062 Maven是什么[what] 1.Maven 是 Apache 软件基金会 ...
- 浅谈Webpack模块打包工具三
Source Map 生产代码与开发代码完全不同,如果需要调试应用的话会非常的麻烦,错误信息无法定位,Soutce Map就会逆向得到源代码, 须在打包之后的代码文件的末尾位置例如添加//# sour ...
- 浅谈如何使用swfupload工具与struts2无缝相接
笔者在网上查找流行的上传组件,swfupload引入眼帘,受到JavaEye的一篇文章启发,历时三天,加以研究,现将心得奉上,献礼JavaEye. 由于笔者才疏学浅,经验匮乏,介绍不深入,仅供菜鸟参考 ...
- 浅谈ABB机器人(工具坐标,工件坐标,有效载荷)
工具坐标(tool): 使tcl坐标偏移到工具上,例如焊接工作,使机器人工作点切入焊枪点上 mass:工具的重量 xyz:偏移距离的大小 验证:通过手动模式,切换至自定义工具,重定向 工件坐标(wob ...
- 浅谈Webpack模块打包工具一
为什么要使用模块打包工具 1.模块化开发ES Modules存在兼容性问题 打包之后成产阶段编译为ES5 解决兼容性问题 2.模块文件过多 网络请求频繁 开发阶段把散的模块打包成一个模块 解决网络请 ...
- 浅谈Webpack模块打包工具四
Webpack 生产环境优化 生产环境和开发环境有很大的差异,生产环境只注重运行效率,开发环境主要开发效率,webpack4.0开始提出了(mode)模式的概念 针对不同的环境进行不同的配置,为不同的 ...
- 开发工具--浅谈Git
工具|浅谈Git Git这个工具,是我一直想写文章,终于我实现了我的想法.在我开始写之前,发表一下自己的看法,git只是一个工具,既然已经认定是一个工具,那么一定具备工具这类的共同特征,请用面向对象的 ...
随机推荐
- JS逆向-抠代码的第一天【手把手学会抠代码】
首先声明,本人经过无数次摸爬滚打及翻阅各类资料,理论知识极其丰富,但是抠代码怎么都抠不会. 无奈之下,只能承认:这个活,需要熟练度. 本文仅对部分参数进行解析,有需要调用,请自行根据现实情况调整. 第 ...
- Python基础【基本数据类型】
基本数据类型分类 数字 int 字符串 str 列表 list 字典 dict 元祖 tuple ...
- P1162_填涂颜色(JAVA语言)(速看!全洛谷最暴力解法!QAQ)
思路:看了看数据n<=30,于是我们可以暴力求解(主要是BFS学的不咋地~2333).枚举每个0的位置,看上下左右四个方向上是否都有1.都有1的话说明被1包围,即在闭合圈的内部,开个数组标记一下 ...
- PTA 将数组中的数逆序存放
7-1 将数组中的数逆序存放 (20 分) 本题要求编写程序,将给定的n个整数存入数组中,将数组中的这n个数逆序存放,再按顺序输出数组中的元素. 输入格式: 输入在第一行中给出一个正整数n(1). ...
- 攻防世界 csaw2013reversing2 CSAW CTF 2014
运行程序 flag显示乱码 IDA打开查看程序逻辑 1 int __cdecl __noreturn main(int argc, const char **argv, const char **en ...
- 【java框架】SpringBoot(4)--SpringBoot实现异步、邮件、定时任务
1.SpringBoot整合任务机制 1.1.SpringBoot实现异步方法 日常开发中涉及很多界面与后端的交互响应,都不是同步的,基于SpringBoot为我们提供了注解方式实现异步方法.使得前端 ...
- 使用Jenkins + git submodule 实现自动化编译,解决代码安全性问题
道哥的第 030 篇原创 目录 一.一个真实的代码泄漏故事 二.Jenkins 的基本使用 1. Jenkins 是什么? 2. 安装 JDK8 3. 安装 Jenkins 4. 在浏览器中配置 Je ...
- elasticsearch 7.7 配置文件:elasticsearch.yml
# ======================== Elasticsearch Configuration ========================= # # NOTE: Elasticse ...
- day-03-基础数据类型
基础数类型总览 10203 123 3340 int +- * / 等等 '今天吃了没?' str 存储少量的数据,+ *int 切片, 其他操作方法 True False bool 判断真假 [12 ...
- Java代码格式化规范实践总结
目标说明 统一良好的代码格式规范可以有效提升开发团队之间的「协作效率」,如果不同的开发团队或者开发人员采用不同的代码格式规范,那么每次Format代码都会导致大量的变化,在Code Review及Me ...