利用python爬取城市公交站点
利用python爬取城市公交站点
页面分析
https://guiyang.8684.cn/line1


爬虫
我们利用requests请求,利用BeautifulSoup来解析,获取我们的站点数据。得到我们的公交站点以后,我们利用高德api来获取站点的经纬度坐标,利用pandas解析json文件。接下来开干,我推荐使用面向对象的方法来写代码。
import requests
import json
from bs4 import BeautifulSoup
import pandas as pd
class bus_stop:
## 定义一个类,用来获取每趟公交的站点名称和经纬度
def __init__(self):
self.url = 'https://guiyang.8684.cn/line{}'
self.starnum = []
for start_num in range(1, 17):
self.starnum.append(start_num)
self.payload = {}
self.headers = {
'Cookie': 'JSESSIONID=48304F9E8D55A9F2F8ACC14B7EC5A02D'}
## 调用高德api获取公交线路的经纬度
### 这个key大家可以自己去申请
def get_location(self, line):
url_api = 'https://restapi.amap.com/v3/bus/linename?s=rsv3&extensions=all&key=559bdffe35eec8c8f4dae959451d705c&output=json&city=贵阳&offset=2&keywords={}&platform=JS'.format(
line)
res = requests.get(url_api).text
# print(res) 可以用于检验传回的信息里面是否有自己需要的数据
rt = json.loads(res)
dicts = rt['buslines'][0]
# 返回df对象
df = pd.DataFrame.from_dict([dicts])
return df
## 获取每趟公交的站点名称
def get_line(self):
for start in self.starnum:
start = str(start)
# 构造url
url = self.url.format(start)
res = requests.request(
"GET", url, headers=self.headers, data=self.payload)
soup = BeautifulSoup(res.text, "lxml")
div = soup.find('div', class_='list clearfix')
lists = div.find_all('a')
for item in lists:
line = item.text # 获取a标签下的公交线路
lines.append(line)
return lines
if __name__ == '__main__':
bus_stop = bus_stop()
stop_df = pd.DataFrame([])
lines = []
bus_stop.get_line()
# 输出路线
print('一共有{}条公交路线'.format(len(lines)))
print(lines)
# 异常处理
error_lines = []
for line in lines:
try:
df = bus_stop.get_location(line)
stop_df = pd.concat([stop_df, df], axis=0)
except:
error_lines.append(line)
# 输出异常的路线
print('异常路线有{}条公交路线'.format(len(error_lines)))
print(error_lines)
# 输出文件大小
print(stop_df.shape)
stop_df.to_csv('bus_stop.csv', encoding='gbk', index=False)

数据清洗
我们先来看效果,我需要对busstops列进行清洗。我们的总体思路,分列->逆透视->分列。我会接受两种方法,一是Excel PQ,二是python。
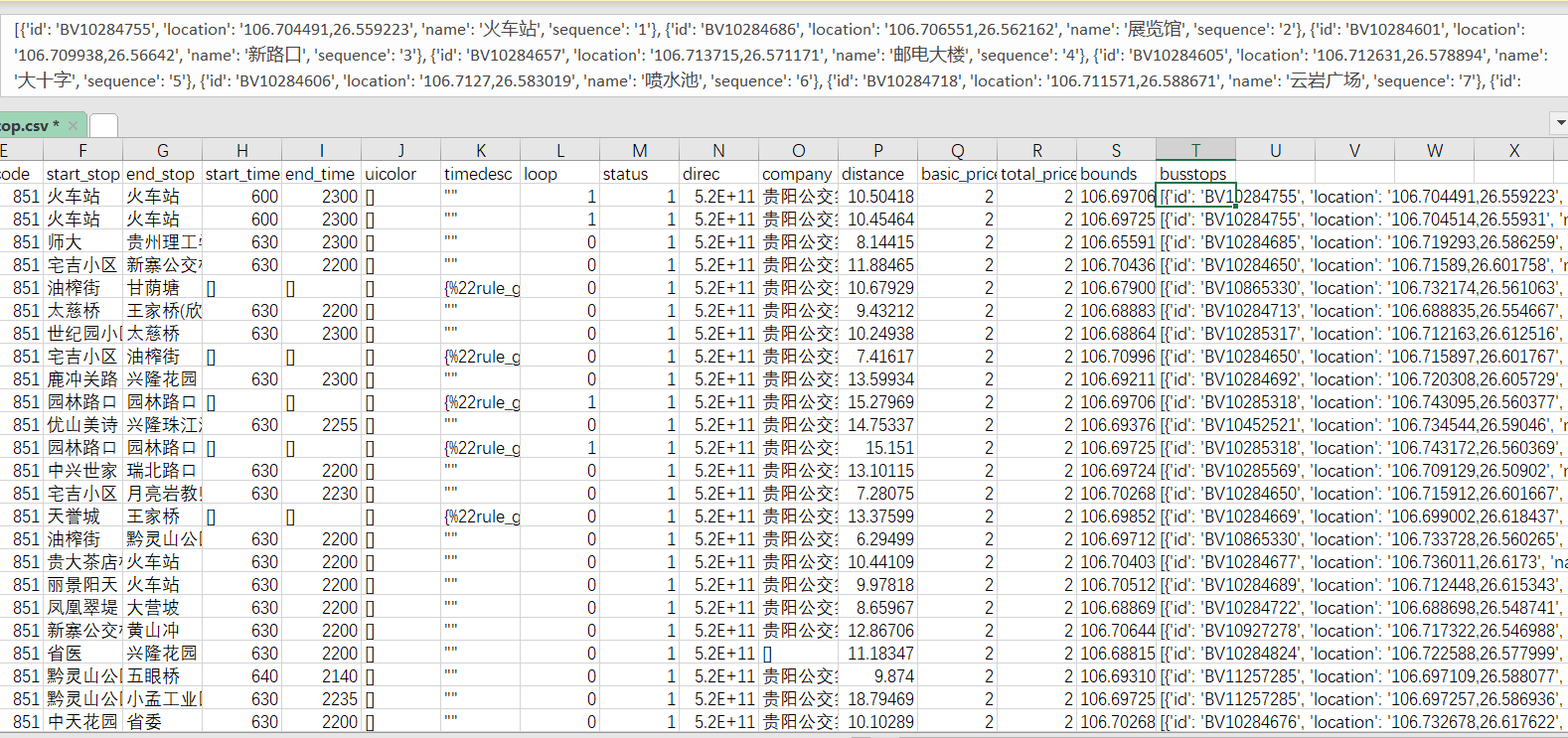
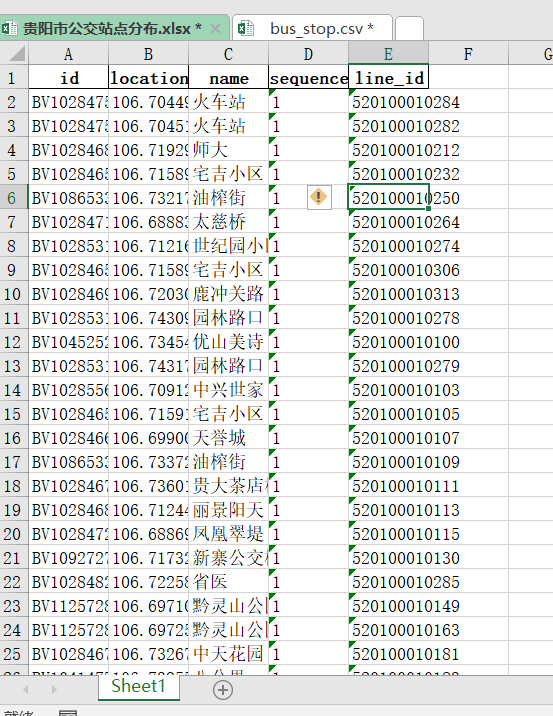
Excel PQ 数据清洗
这一方法完全利用PQ,纯界面操作,问题不大,所以我们看看流程就可以了,核心步骤就是和上面一样的。
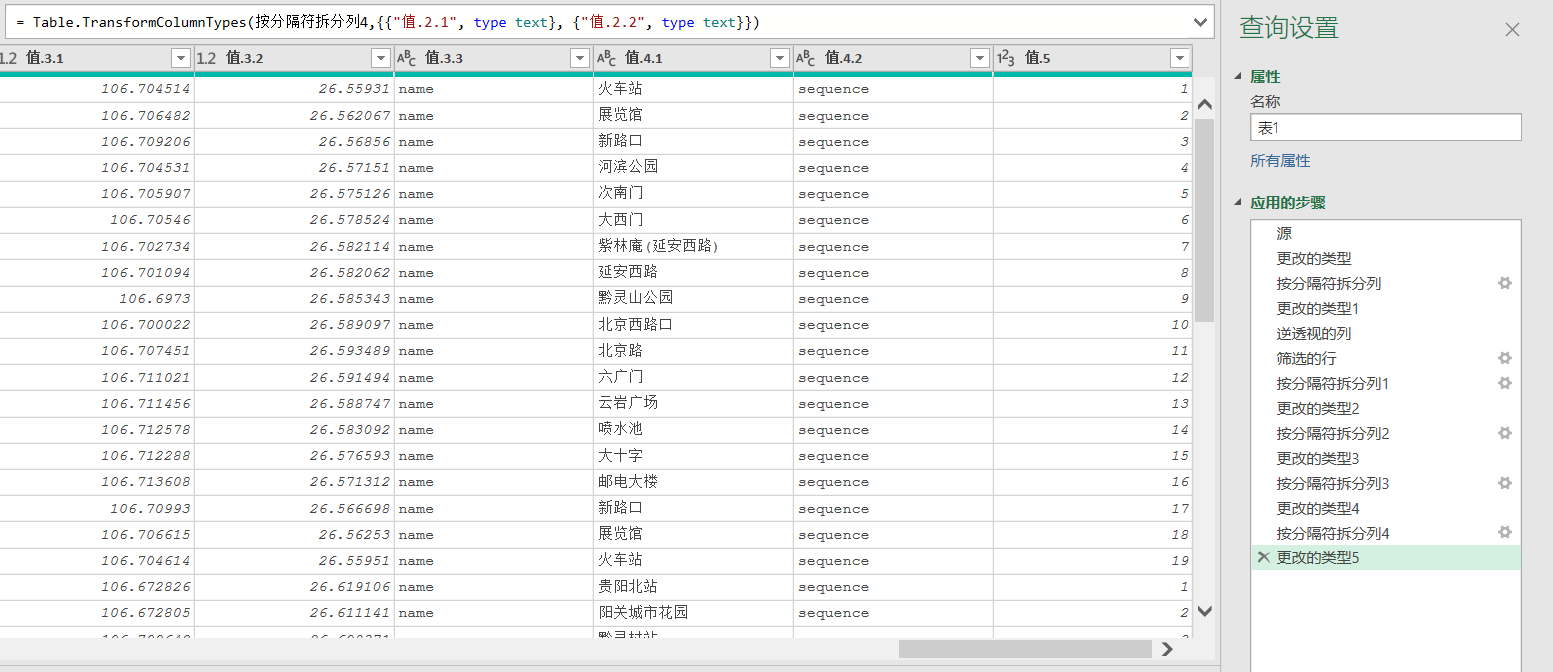
python数据清洗
## 我们需要处理的busstops列和ID列
data = stop_df[['id','busstops']]
data.head()
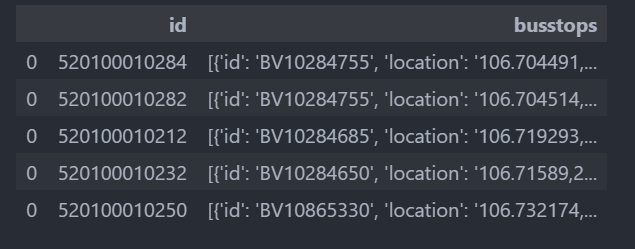
## 字典或者列表分列
df_pol = data.copy()
### 设置索引列
df_pol.set_index('id',inplace=True)
df_pol.head()
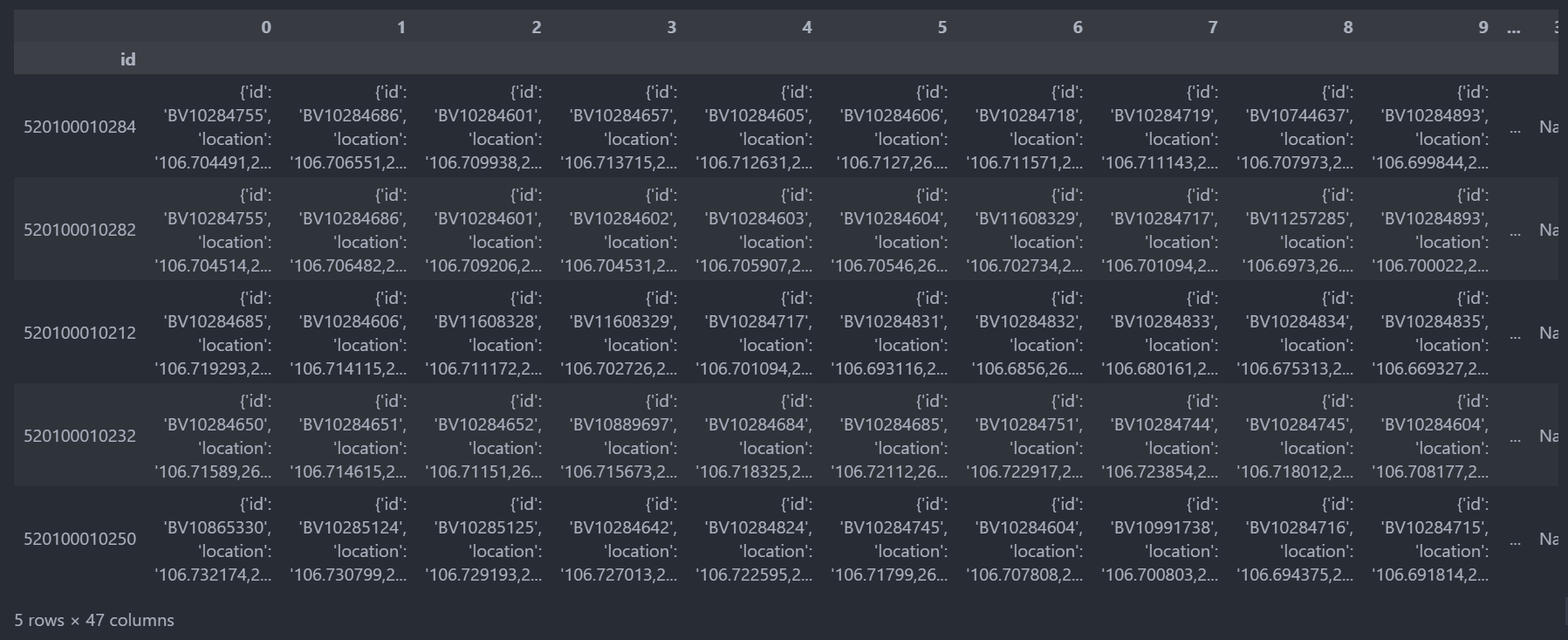
## 逆透视
### 释放索引
df_pol.reset_index(inplace=True)
### 逆透视操作
df_pol_ps = df_pol.melt(id_vars=['id'], value_name='busstops')
df_pol_ps.head()
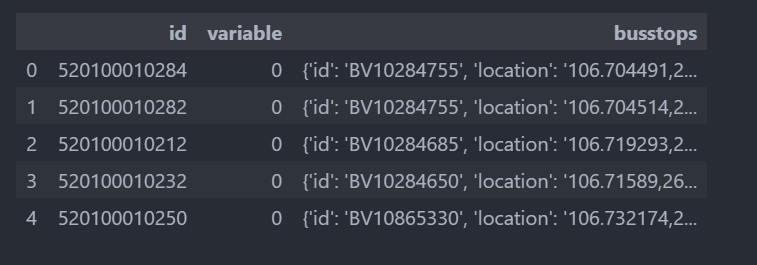
## 删除空行
df_pol_ps.dropna(inplace=True,axis=0)
df_pol_ps.shape
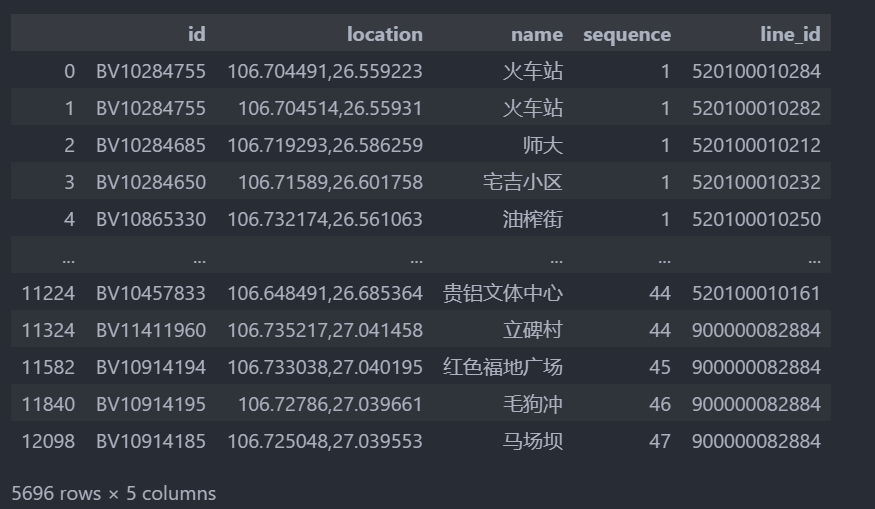
## 分列
### 设置line_id
df_parse['line_id'] = df_pol_ps['id']
df_parse = df_pol_ps['busstops'].apply(pd.Series)
df_parse
我这里补充一下,我们一般还要对location列进行分列,把Long,lat分列出来,但是我们这里就不做了,都是重复劳动,而且我用的pq清洗,快很多。
## 写入文件
df_parse.to_excel('贵阳市公交站点分布.xlsx', index=False)</pre>
QGIS坐标纠偏
QGIS基础操作,我就不说了,顺便说一下QGIS对csv格式支持较好,我推荐我们导入QGIS的文件为csv格式的文件。
导入csv文件
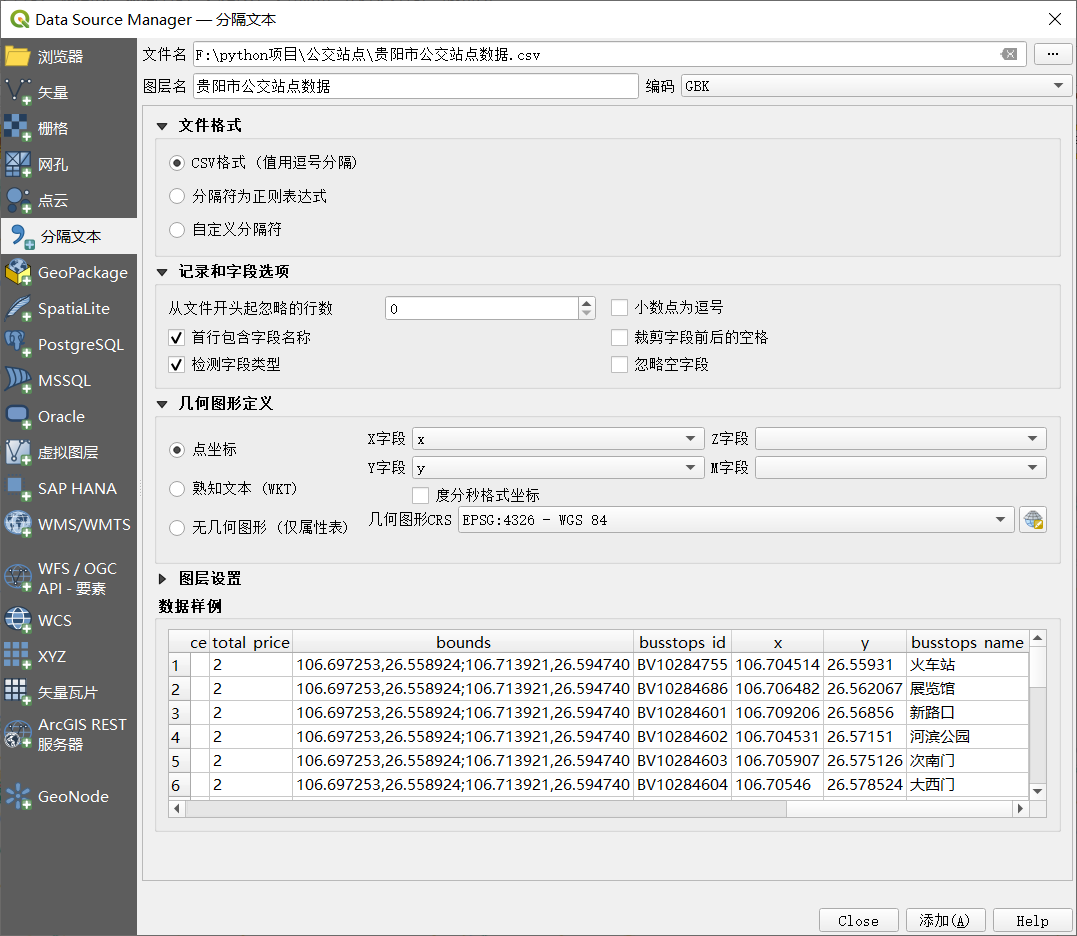
坐标纠偏
以前说了很多,我们高德地图上的坐标是GCJ02坐标,我们需要转成WGS 1984坐标,我们在QGIS里面需要借助GeoHey插件。
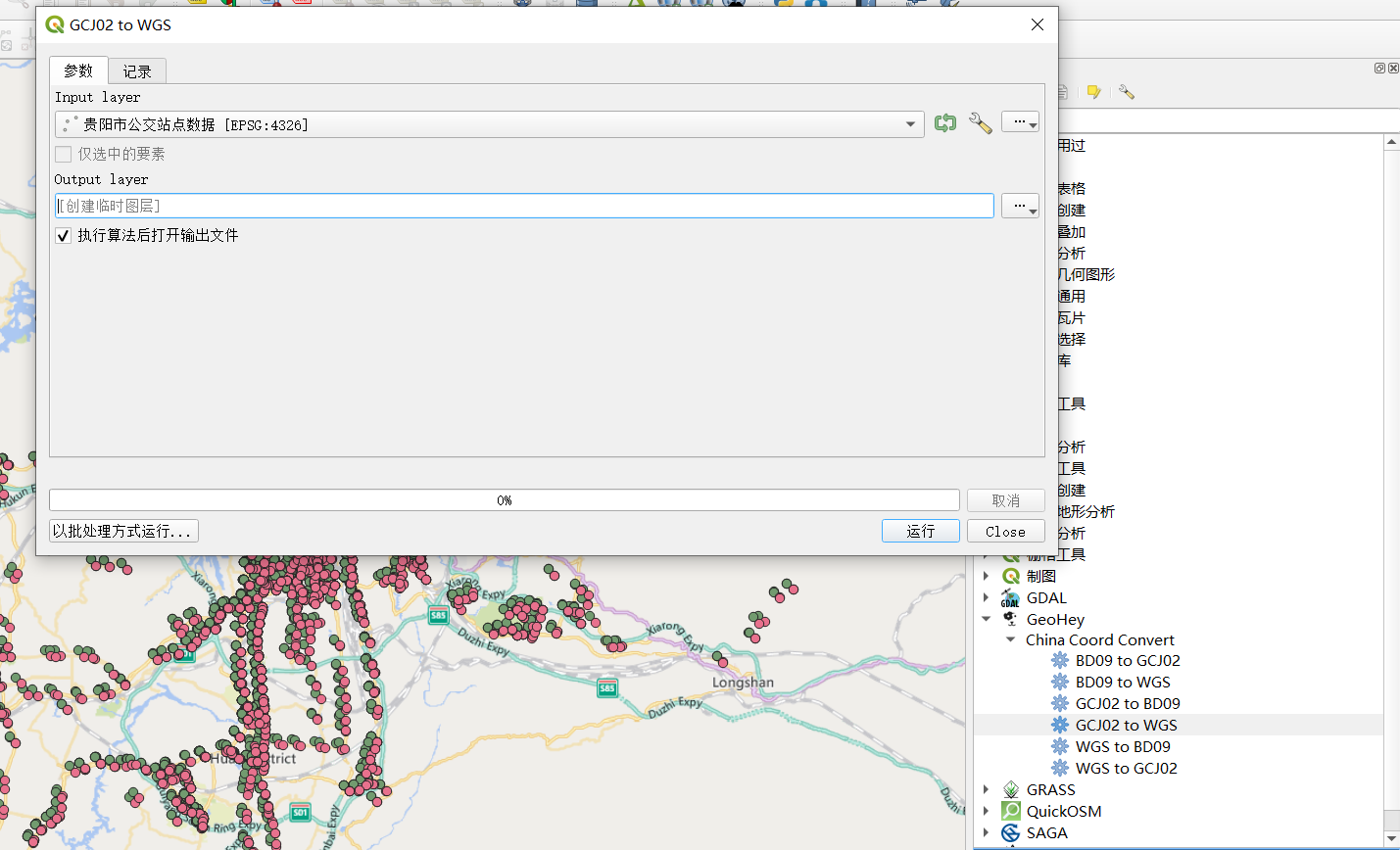
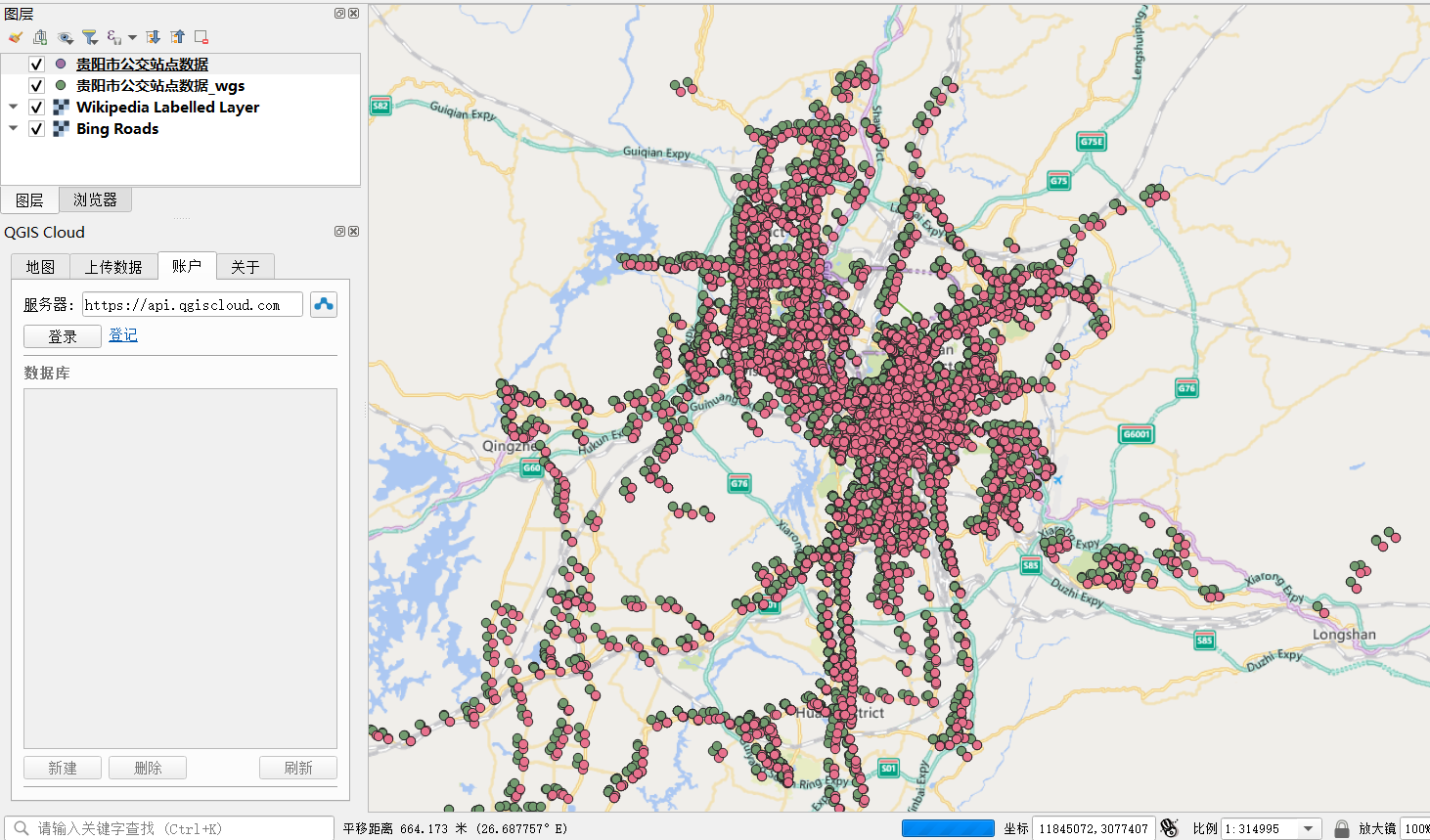
看一下这个坐标纠偏,区别还是很大。
总结
总的来说,我们还是推荐使用使用面向对象的方法来写代码,还有就是异常处理必不可少。我这次面对的问题是某些公交路线,高德API里面没有,这样就会异常,所以这次的异常处理不可缺少。从数据处理的角度来看,这次从速度和方便来说,pq完胜python,我推荐大家数据清洗就用pq,有些时候,我都会给出多种处理方法,pq看起来复杂,但是其实pq是最简单的,总之,我高度推荐pq进行数据清洗。还有一点,python里面的索引比较麻烦,这次我要保证和bus_stop_id和line_id,这样公交站点表和公交路线表才可以连接,其实这就是SQL里面的外键连接,所以我在python数据清洗的时候,涉及到大量的索引操作,在pq里面没有这么复杂。说到这个索引,感谢我的SQL老师,当年她讲解SQL里面的索引,约束,仿佛就在昨天。高德的这个key大家可以自己去申请,这个key可能有数量的限制。我接下来会把代码上传到Gitee,这个代码的管理还是很重要的,自己也学习一下代码的管理。接下来,感谢小学妹给的这个小项目,也感谢崔工对我的鼓励,其实,我最近很忙,不太想写文章的。最后,感谢认识的一个小学妹,她真的蛮优秀的,最后希望大家2021年最后这一个月万事如意,开开心心,也希望我们都有一个光明的未来。还有一个坑,我建议大家在简书上写文章,真的本地的话,图片上传有问题。
利用python爬取城市公交站点的更多相关文章
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- 没有内涵段子可以刷了,利用Python爬取段友之家贴吧图片和小视频(含源码)
由于最新的视频整顿风波,内涵段子APP被迫关闭,广大段友无家可归,但是最近发现了一个"段友"的app,版本更新也挺快,正在号召广大段友回家,如下图,有兴趣的可以下载看看(ps:我不 ...
- 利用Python爬取朋友圈数据,爬到你开始怀疑人生
人生最难的事是自我认知,用Python爬取朋友圈数据,让我们重新审视自己,审视我们周围的圈子. 文:朱元禄(@数据分析-jacky) 哲学的两大问题:1.我是谁?2.我们从哪里来? 本文 jacky试 ...
- 利用python爬取海量疾病名称百度搜索词条目数的爬虫实现
实验原因: 目前有一个医疗百科检索项目,该项目中对关键词进行检索后,返回的结果很多,可惜结果的排序很不好,影响用户体验.简单来说,搜索出来的所有符合疾病中,有可能是最不常见的疾病是排在第一个的,而最有 ...
- 如何利用python爬取网易新闻
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: LSGOGroup PS:如有需要Python学习资料的小伙伴可以 ...
- 利用python爬取贝壳网租房信息
最近准备换房子,在网站上寻找各种房源信息,看得眼花缭乱,于是想着能否将基本信息汇总起来便于查找,便用python将基本信息爬下来放到excel,这样一来就容易搜索了. 1. 利用lxml中的xpath ...
- 利用Python爬取可用的代理IP
前言 就以最近发现的一个免费代理IP网站为例:http://www.xicidaili.com/nn/.在使用的时候发现很多IP都用不了. 所以用Python写了个脚本,该脚本可以把能用的代理IP检测 ...
- 利用Python爬取网页图片
最近几天,研究了一下一直很好奇的爬虫算法.这里写一下最近几天的点点心得.下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 我们这里以sogou作为爬取的对象. 首先我们进入搜狗图片 ...
随机推荐
- Hdu P1394 Minimum Inversion Number | 权值线段树
题目链接 题目翻译: 约定数字序列a1,a2,...,an的反转数是满足i<j和ai>aj的数对(ai,aj)的数量. 对于给定的数字序列a1,a2,...,an,如果我们将第1到m个数字 ...
- c#复制数组的多种方法
方法一:使用for循环 int []pins = {9,3,7,2} int []copy = new int[pins.length]; for(int i =0;i!=copy.length;i+ ...
- DeWeb部署
DeWeb部署 部署时需要runtime中的大部分文件 需要的目录有: apps,仅包括需要部署的dll即可 dist,必须.请勿改动 media,非必须,一般媒体文件存在于此目录 upload,必须 ...
- Centos7上安装Ubuntu容器
1.再次之前我们要先装好docker,在上一篇我已经给出了教程,没有安装好的快去看看吧! 2.这里我们使用的是linux系统,所有在线安装是最简便的方法了.我们可以从国内拉取dockerhub镜像,这 ...
- Fiddler抓包工具简介:(三)手机端代理配置
1.接入网络:需要在移动终端(手机或pad)上指定代理服务器为Fiddler所在主机的IP,端口默认为8888,要保证手机和安装有fiddler的电脑处在同一局域网内,手机能ping通电脑. [方法] ...
- xmind 文件 打开后会在当前目录生成 configuration,p2和workspace目录,artifacts.xml文件 解决
在xmind安装目录下的xmind.ini修改如下配置,为绝对路径
- Linux环境下安装、配置Redis
linux下安装redis 官网下载链接:https://redis.io/download 安装 下载redis压缩包 1.选择Stable(5.0)下的Download 5.0.0 链接进行下载 ...
- 关于JDBC中查询方法的抽取
萌新的JAVA学习笔记[1] 先来张伊蕾娜镇场~~ 简单描述 起初我们的查询方法时分为单个查询和全部查询,过于局限与繁琐,如此一来我们能不能想一个办法将所有类型的查询抽取出来并整合成为一个单独的工具方 ...
- PHP create_function代码注入
今天做ctf遇到一道题,记录一下知识点 <?php class Noteasy{ protected $param1; protected $param2; function __destruc ...
- Python基础(序列化)
#pickling import pickle,json # d = dict(name='傻狗1',age=300,score=100) # d1 = pickle.dumps(d)#pickle. ...