大数据学习day35----flume01-------1 agent(关于agent的一些问题),2 event,3 有关agent和event的一些问题,4 transaction(事务控制机制),5 flume安装 6.Flume入门案例
具体见文档,以下只是简单笔记(内容不全)
1.agent
Flume中最核心的角色是agent,flume采集系统就是由一个个agent连接起来所形成的一个或简单或复杂的数据传输通道。对于每一个Agent来说,它就是一个独立的守护进程(JVM),它负责从数据源接收数据,并发往下一个目的地,如下图所示:
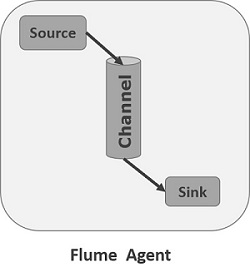
每一个agent相当于一个数据(被封装成Event对象)传递员,内部有三个组件:
- Source:数据源组件,用于跟数据源对接,以获取数据;它有各种各样的内置实现(若是source从kafka中读取数据,本质上就是封装了kafka的客户端);
- Sink:下沉组件(输出),用于往下一级agent传递数据或者向最终存储系统传递数据
- Channel:缓存通道组件,用于从source将数据传递到sink

2. Event
数据在Agent内部中各模块间的传输,以Event(JaveBean)的形式存在。因此,Source组件在获取到原始数据后,需要封装成Event放入channel。Sink组件从channel中取出Event后,需要根据配置要求,转成其他形式的数据输出
Event封装对象主要有两部分组成: Headers 和 Body
headers: 是一个集合Map[String,String],用于携带一些KV形式的元数据(标志、描述等)
boby: 就是一个字节数组;装载具体的数据内容

event相当于一个javabean,如下
public class Event{
// 用于装载一些元数据(描述信息),可选
private HashMap[String, String] headers;
private byte[] body;
}
注意:event是一条数据一条数据的封装,所以source将数据传到channel也是一条一条传入的
3 有关agent和event的一些问题
问题一:agent设计时为什么会有channel,为何不直接将source与sink直接对接(即sink直接从source获取数据)?
source读取数据的速度与sink读取数据的速度不一致,当source从外部读取数据比较快时,原始数据在还没有被sink处理掉时,新的数据又来了,这样原始数据就会被新数据覆盖,造成数据丢失。但是有channel则可以解决这个情况,source中的数据写入channel(内存,往channel写入数据的速度很快),sink再从channel中读取数据。这里可能会有另外一个问题,如下:
问题二:source往channel写入数据的速度大于sink从channel获取数据的速度,从而造成channel装满了(内存溢出),这该怎么解决?
这个时候就是加大channel内存的大小,同时可以增减sink的个数。一般channel是不会溢出的(不需要加大),若是溢出说明设计组件有问题。特殊情况,比如双十一时,数据量短时间剧增,这个时候就需要将channel增大。若Channel满了时,source就不会将数据传入channel,会等待channel有空位置而慢慢传输局进入channel
问题三:agent中的数据为什么全封装成event?
source获取的数据类型并不确定,这样缓存中(channel)就不知道该接收什么类型的数据,所以定义了一个event。不论外部数据的类型是什么,其经过处理都得到event类型的数据,最终根据自己需要的存储系统是我们而确定sink的类型(如将数据写入hdfs就需要用与hdfs对应的sink)
4 transaction(事务控制机制)
Flume的事务机制(类似数据库的事务机制):
Flume使用两个独立的事务分别负责从Soucrce到Channel,以及从Channel到Sink的event传递。比如spooling directory source 为文件的每一个event batch创建一个事务,一旦事务中所有event全部传递到Channel且提交成功,那么Soucrce就将该文件标记为完成。
同理,事务以类似的方式处理从Channel到Sink的传递过程,如果因为某种原因使得事务无法记录,那么事务将会回滚。且所有的事件都会保持到Channel中,等待重新传递。
事务机制涉及到如下重要参数:
a1.sources.s1.batchSize =100(source向channel推送数据的批次大小)
a1.sinks.k1.batchSize = 200 (sink从channel拉取数据的批次大小) a1.channels.c1.transactionCapacity = 300 (事务容量,应该大于source或者sink的批次大小)
跟channel的数据缓存空间容量区别开来:
a1.channels.c1.capacity = 10000
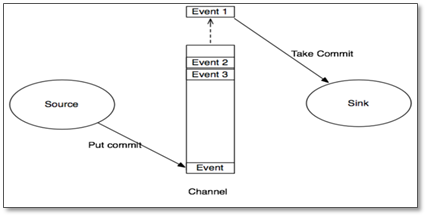
那么事务是如何保证数据的完整性的呢?看下面有两个agent的情况:
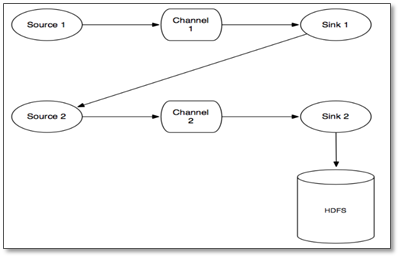
数据流程:
(1)source 1产生Event,通过“put”、“commit”操作将Event放到Channel 1中
(2)sink 1通过“take”操作从Channel 1中取出Event,并把它发送到Source 2中
(3)source 2通过“put”、“commit”操作将Event放到Channel 2中
(4)source 2向sink 1发送成功信号,sink 1“commit”步骤2中的“take”操作(其实就是删除Channel 1中的Event)
说明:
- 在任何时刻,Event至少在一个Channel中是完整有效的
- 不是任何一种source实现、channel实现、sink实现都能很好地实现事务管理
问题:flume的事务,可以保证数据的可靠性(不会丢失),但无法避免数据重复,这是为什么?
source记录偏移量有两种方式,第一种是数据成功放入channel后再记录偏移量,另一种是source获取到数据就记录偏移量,然后在将该数据放入channel。
数据被放入channel后,source再记录偏移量,但当这个时候source意外挂掉之后,则偏移量就没有更新,数据会重复读取到channel中。若是source从数据源读取一条数据后就记录偏移量的话,这样也会有一个问题,偏移量记录成功但数据没有成功写入channel,这样会造成数据丢失。所以事务总是难做到两全,flume使用的是前一种(宁可数据重复,也不让其丢失)
5 flume安装
思考:flume该安装在哪里?
主要看数据源在哪里,以及目标存储在哪里。比如: 数据源在日志服务器上,要采的数据是日志服务器上的日志文件flume就应该装在日志服务器上!再比如:数据源是一个kafka集群,要采的是这个kafka中的某个topic的数据,flume可以装在任意地方!再比如:数据源是一个网络消息发送者,要采的就是这个网络消息发送者所发送的数据flume可以在任何地方,只要将源发送者的发送目标指向flume所在机器和所监听的端口即可!
(1)前提:存在hadoop环境
(2)上传安装包到数据源所在的节点上,然后解压
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /usr/apps
(3)进入flume的目录,修改conf下的flume-env.sh(将flume-env.sh.template后缀去掉),在里面配置JAVA_HOME
(4)根据数据采集的需求配置采集方案,描述在配置文件中(文件名可任意自定义)
(5)指定采集方案配置文件,在相应的节点上启动flume agent
(6)启动命令(见文档)
6.Flume入门案例
6.1 数据采集需求
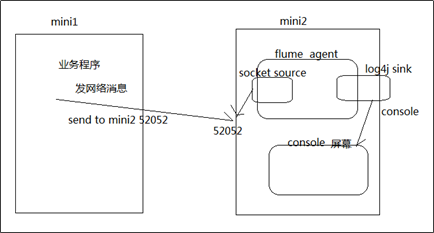
6.2 组件选择
source-----> NetCat Source
channel-----> Memory Channel
Sink---------> logger Sink
各组件参数的硬性要求

6.3 配置的实现
在flume的安装目录下,新建一个文件夹:myconf(可任意命名),进入这个文件夹,
vi netcat-logger.conf
内容如下:
# 定义这个agent中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # 描述和配置source组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 9999
# source 和 channel关联
a1.sources.r1.channels = c1 # 描述和配置sink组件:k1
a1.sinks.k1.type = logger
# sink也要关联channel
a1.sinks.k1.channel = c1 # 描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
注意:注释不能卸载配置的后面,只能单独一行写
6.4 启动采集
(1)启动一个采集器,并指定相应的参数()

/usr/apps/apache-flume-1.9.0-bin/bin/flume-ng agent -n a1 -c conf \
> -f myconf/avro-logger.conf \
> -Dflume.root.logger=INFO,console // 将运行日志输出到终端界面
说明:-d 传参数不是传给main方法的,而是传给程序运行的jvm环境中,但是可以在代码中获取到这个环境变量
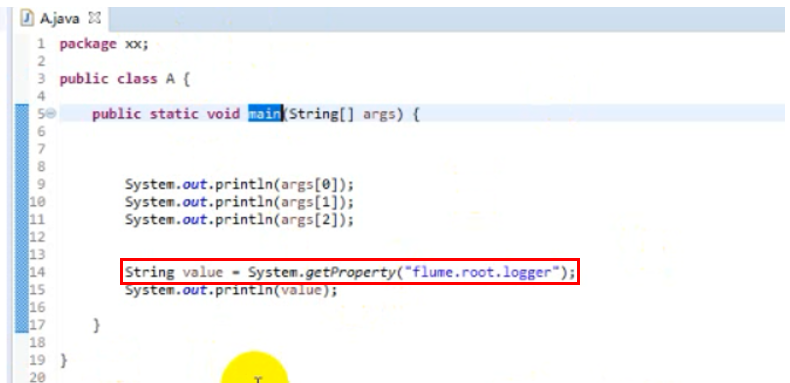
运行结果如下:
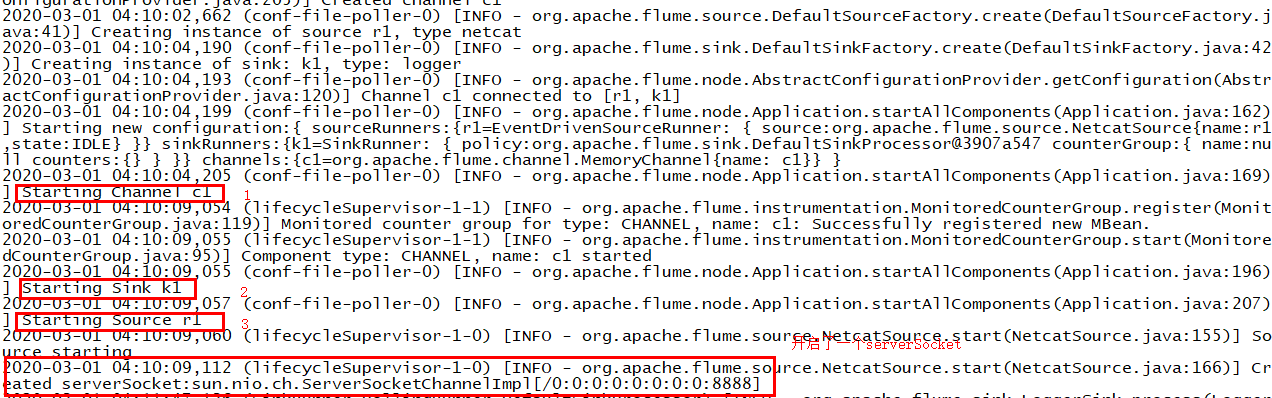
(2)往agent的source所监听的端口上发送数据,让agent有数据可采
前提:安装了telnet(如果没有直接yum -y install telnet)
通过telnet命令向端口发送消息

(3)查看日志

6.5 web监控
和其他大数据组件一样,flume也有一个web监控服务,只是比较简单,并且启动flume时要配置相应的参数
完整命令如下:
bin/flume-ng agent -n a1 \
-c ./conf/ \
-f myconf/netcat-logger.conf \
-Dflume.monitoring.type=http \
-Dflume.monitoring.port=34345 \
-Dflume.root.logger=INFO,console
然后就可以使用web浏览器进行监控页面的访问:

exec source,spooldir source,taildir source这些source组件的具体使用见文档
- exec source
采集一个用户指定的linux shell命令的输出,作为收集到的数据,转为event写入channel;
注意:通过人为破坏测试,发现这个exec source,不会记录宕机前所采集数据的偏移量,重启后会造成数据丢失
- spooldir
监视一个指定的文件夹,如果文件夹下有没采集过的新文件,则将这些新文件中的数据采集,并转成event写入channel;
注意:spooling目录中的文件必须是不可变的,而且是不能重名的!否则,source会loudly fail! spooldir source与execsource不同,spooldir source本身是可靠的,其会记录崩溃之前采集的偏移量
- taildir source
监视指定目录下的一批文件,只要某个文件中有新追加的行,则会被tail到。它会记录每一个文件所tail到的位置,记录到一个指定的positionfile保存目录中,格式为json(如果需要的时候,可以人为修改,就可以让source从任意指定的位置开始读取数据),它对采集完成的文件,不会做任何修改(比如重命名,删除…..)
此source不会丢失数据,但在极端情况下会产生重复数据
补充:tail命令
跟踪文件(从尾部)
tail -f a.txt //-f跟踪的是文件(即文件的唯一标识)
tail -F a.txt // 跟踪的是文件名,当文件名重命名后,其能立刻跟踪重命名的文件,所以一般使用-F

大数据学习day35----flume01-------1 agent(关于agent的一些问题),2 event,3 有关agent和event的一些问题,4 transaction(事务控制机制),5 flume安装 6.Flume入门案例的更多相关文章
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习之Linux进阶02
大数据学习之Linux进阶 1-> 配置IP 1)修改配置文件 vi /sysconfig/network-scripts/ifcfg-eno16777736 2)注释掉dhcp #BOOTPR ...
- 大数据学习之Linux基础01
大数据学习之Linux基础 01:Linux简介 linux是一种自由和开放源代码的类UNIX操作系统.该操作系统的内核由林纳斯·托瓦兹 在1991年10月5日首次发布.,在加上用户空间的应用程序之后 ...
- 大数据学习:storm流式计算
Storm是一个分布式的.高容错的实时计算系统.Storm适用的场景: 1.Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中. 2.由于Storm的处理组件都是分布式的, ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
随机推荐
- arm开发板上找不到/dev/i2c-*设备
最近在调试arm与外设iic通讯是,想来个投机取巧,先不写单独的驱动,直接通过iic bus设备是否可以连接到外设,然后发现在板子上找不到"/dev/i2c-n"的设备,标准的系统 ...
- pycharm基本使用python的注释语法
pychram基本使用 1.主题选择 file settings Editor color Scheme 2.pycharm切换解释器 file settings Project Python Int ...
- Python正则表达式使用小记
最近做Python课实验发现正则表达式和它在py中的的标准库re有很多能多琢磨一下的点,遂决定写成一篇小记,以后想复习能再来看看. 名词 因为不同文献书籍对正则表达式的描述有差别,我在这里列出一下我已 ...
- 五(一)、spring 声明式事务注解配置
一.事务概述: 事务就是一系列的动作, 它们被当做一个单独的工作单元. 这些动作要么全部完成, 要么全部不起作用:比如 用户购买图书:购买动作之前需要确认 ①图书的数量是否足够:②用户账号余额是否足够 ...
- C++ 内存四区 理解总结
内存模型图(4G) 整体简单说明 32位CPU可寻址4G线性空间,每个进程都有各自独立的4G逻辑地址,其中 03G是用户空间**,**34G是内核空间即3G用户空间和1G内核空间,不同进程相同的逻辑地 ...
- cgdb | 一起边看源码边调试gdb吧
简介 cgdb是一款轻量级的基于gdb的命令行可视化工具,关系大致如下: 尽管gdb本身可以通过layout src的命令显示源码布局,但是其功能还是过于简陋. 使用cgdb并不需要你重新去学习过多额 ...
- Django 小实例S1 简易学生选课管理系统 6 实现登录逻辑
Django 小实例S1 简易学生选课管理系统 第6节--实现登录逻辑 点击查看教程总目录 作者自我介绍:b站小UP主,时常直播编程+红警三,python1对1辅导老师. 1 业务逻辑 本教程第四节里 ...
- 【故障公告】突然猛增的巨量请求冲垮一共92核CPU的k8s集群
非常抱歉,今天下午2点左右开始,博客站点突然猛增的巨量请求让k8s集群的节点服务器不堪重负,造成网站无法正常访问,由此给您带来麻烦,请您谅解. 当时k8s集群一共6台node服务器,2台32核64G, ...
- scrapy获取当当网多页的获取
结合上节,网多页的获取只需要修改 dang.py import scrapy from scrapy_dangdang.items import ScrapyDangdang095Item class ...
- DECODE 与CASE WHEN 的比较
1.DECODE 只有Oracle 才有,其它数据库不支持; 2.CASE WHEN的用法, Oracle.SQL Server. MySQL 都支持; 3.DECODE 只能用做相等判断,但是可以配 ...