NNLM原理及Pytorch实现
NNLM
NNLM:Neural Network Language Model,神经网络语言模型。源自Bengio等人于2001年发表在NIPS上的《A Neural Probabilistic Language Model一文。
理论
模型结构
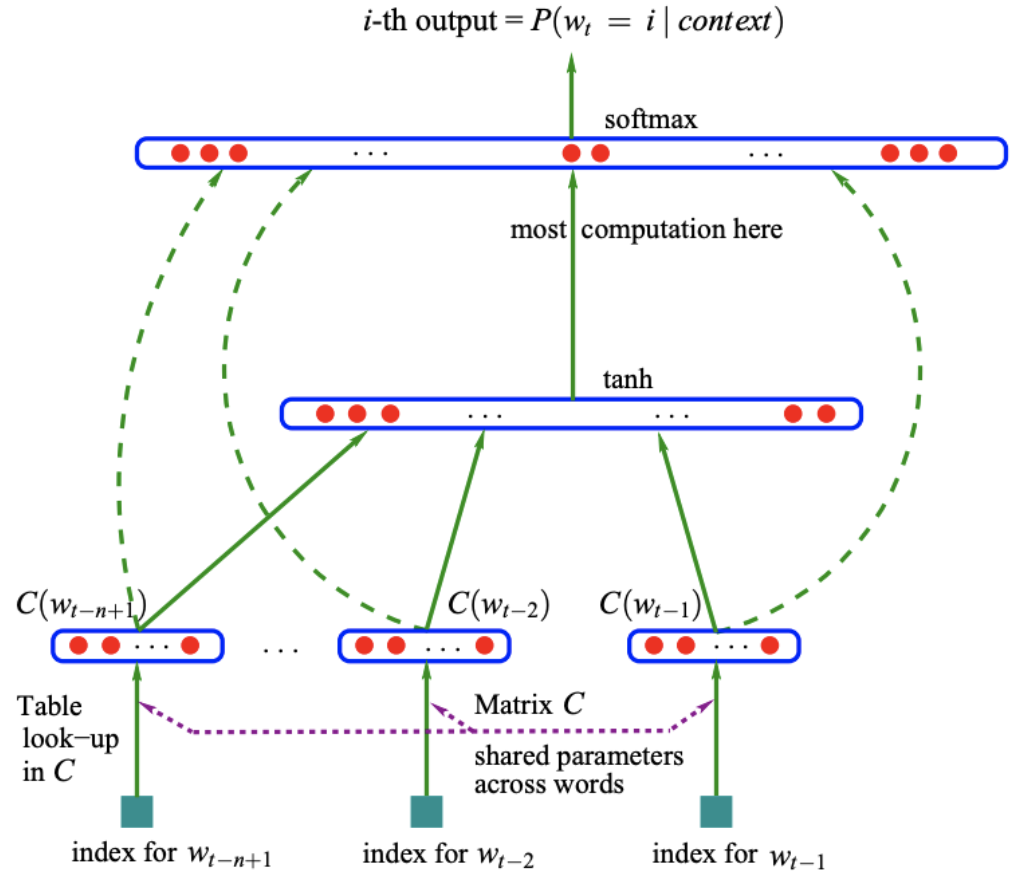
任务
根据\(w_{t-n+1}...w_{t-1}\)来预测\(w_t\)是什么单词,即用\(n-1\)个单词来预测第\(n\)个单词
符号
- \(V\):词汇的总数,即词汇表的大小
- \(m\):词向量的长度
- \(C\):\(V\)行,m列的矩阵表示词向量词表
- \(C(w)\):单词w的词向量
- \(d\):隐藏层的偏置
- \(H\):隐藏层的权重
- \(U\):隐藏层到输出层的权重
- \(b\):输出层的偏置
- \(W\):输入层到输出层的权重
- \(h\):隐藏层的神经元个数
Data Flow
- 获取\(n-1\)个词的词向量,每个词向量的长度是\(m\)
- 进行这\(n-1\)个词向量的拼接,形成一个\((n-1)*m\)长度的向量,记做\(X\)
- 将\(X\)送入隐藏层,计算\(hidden_{out}=tanh(X*H+d)\)的到隐藏层的输出
- 将隐藏层的输出和输入的词向量同时送入输出层,计算\(y=X*W+hidden_{out}*U+b\),得到输出层\(|V|\)个节点的输出,第\(i\)个节点的输出代表下一个单词是第\(i\)个单词的概率。概率最大的单词为预测到的单词。
代码
Import依赖模块
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
from torch.autograd import Variable
dtype = torch.FloatTensor
声明变量
sentences = ["i like dog", "i love coffee", "i hate milk"] # 句子数据集
n_steps = 2 # 用前几个单词来预测下一个单词,e.g. 2个
n_hidden = 2 # 隐藏层的节点个数,e.g. 2个
m = 2 # 词向量的长度
生成词表
word_list = " ".join(sentences).split(" ") # 获取所有的单词
print("未去重词表:", word_list)
word_list = list(set(word_list)) # 去重
print("去重词表:", word_list)
word_dict = {w: i for i, w in enumerate(word_list)} # 单词->索引
print("单词索引:", word_dict)
number_dict = {i: w for i, w in enumerate(word_list)} # 索引->单词
print("索引单词:", number_dict)
num_words = len(word_dict) # 单词总数
print("单词总数:", num_words)
输出
未去重词表: ['i', 'like', 'dog', 'i', 'love', 'coffee', 'i', 'hate', 'milk']
去重词表: ['coffee', 'love', 'dog', 'like', 'milk', 'hate', 'i']
单词索引: {'coffee': 0, 'love': 1, 'dog': 2, 'like': 3, 'milk': 4, 'hate': 5, 'i': 6}
索引单词: {0: 'coffee', 1: 'love', 2: 'dog', 3: 'like', 4: 'milk', 5: 'hate', 6: 'i'}
单词总数: 7
模型结构
class NNLM(nn.Module):
# NNLM model architecture
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(num_embeddings = num_words, embedding_dim = m) # 词表
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype)) # 隐藏层的偏置
self.H = nn.Parameter(torch.randn(n_steps * m, n_hidden).type(dtype)) # 输入层到隐藏层的权重
self.U = nn.Parameter(torch.randn(n_hidden, num_words).type(dtype)) # 隐藏层到输出层的权重
self.b = nn.Parameter(torch.randn(num_words).type(dtype)) # 输出层的偏置
self.W = nn.Parameter(torch.randn(n_steps * m, num_words).type(dtype)) # 输入层到输出层的权重
def forward(self, input):
'''
input: [batchsize, n_steps]
x: [batchsize, n_steps*m]
hidden_layer: [batchsize, n_hidden]
output: [batchsize, num_words]
'''
x = self.C(input) # 获得一个batch的词向量的词表
x = x.view(-1, n_steps * m)
hidden_out = torch.tanh(torch.mm(x, self.H) + self.d) # 获取隐藏层输出
output = torch.mm(x, self.W) + torch.mm(hidden_out, self.U) + self.b # 获得输出层输出
return output
格式化输入
def make_batch(sentences):
'''
input_batch:一组batch中前n_steps个单词的索引
target_batch:一组batch中每句话待预测单词的索引
'''
input_batch = []
target_batch = []
for sentence in sentences:
word = sentence.split()
input = [word_dict[w] for w in word[:-1]]
target = word_dict[word[-1]]
input_batch.append(input)
target_batch.append(target)
return input_batch, target_batch
input_batch, target_batch = make_batch(sentences)
input_batch = torch.LongTensor(input_batch)
target_batch = torch.LongTensor(target_batch)
print("input_batch:", input_batch)
print("target_batch:", target_batch)
输出
input_batch: tensor([[6, 3],
[6, 1],
[6, 5]])
target_batch: tensor([2, 0, 4])
训练
model = NNLM()
criterion = nn.CrossEntropyLoss() # 使用cross entropy作为loss function
optimizer = optim.Adam(model.parameters(), lr = 0.001) # 使用Adam作为optimizer
for epoch in range(2000):
# 梯度清零
optimizer.zero_grad()
# 计算predication
output = model(input_batch)
# 计算loss
loss = criterion(output, target_batch)
if (epoch + 1) % 100 == 0:
print("Epoch:{}".format(epoch+1), "Loss:{:.3f}".format(loss))
# 反向传播
loss.backward()
# 更新权重参数
optimizer.step()
输出
Epoch:100 Loss:1.945
Epoch:200 Loss:1.367
Epoch:300 Loss:0.937
Epoch:400 Loss:0.675
Epoch:500 Loss:0.537
Epoch:600 Loss:0.435
Epoch:700 Loss:0.335
Epoch:800 Loss:0.234
Epoch:900 Loss:0.147
Epoch:1000 Loss:0.094
Epoch:1100 Loss:0.065
Epoch:1200 Loss:0.047
Epoch:1300 Loss:0.036
Epoch:1400 Loss:0.029
Epoch:1500 Loss:0.023
Epoch:1600 Loss:0.019
Epoch:1700 Loss:0.016
Epoch:1800 Loss:0.014
Epoch:1900 Loss:0.012
Epoch:2000 Loss:0.011
推理
pred = model(input_batch).data.max(1, keepdim=True)[1] # 找出概率最大的下标
print("Predict:", pred)
print([sentence.split()[:2] for sentence in sentences], "---->", [number_dict[n.item()] for n in pred.squeeze()])
输出
Predict: tensor([[2],
[0],
[4]])
[['i', 'like'], ['i', 'love'], ['i', 'hate']] ----> ['dog', 'coffee', 'milk']
可以和我们的数据集做对比预测准确的。
Reference
NNLM原理及Pytorch实现的更多相关文章
- 3D点云重建原理及Pytorch实现
3D点云重建原理及Pytorch实现 Pytorch: Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruc ...
- 【优化技巧】指数移动平均EMA的原理
前言 在深度学习中,经常会使用EMA(exponential moving average)方法对模型的参数做平滑或者平均,以求提高测试指标,增加模型鲁棒性. 参考 1. [优化技巧]指数移动平均(E ...
- [源码解析]PyTorch如何实现前向传播(1) --- 基础类(上)
[源码解析]PyTorch如何实现前向传播(1) --- 基础类(上) 目录 [源码解析]PyTorch如何实现前向传播(1) --- 基础类(上) 0x00 摘要 0x01 总体逻辑 0x02 废弃 ...
- [源码解析]PyTorch如何实现前向传播(2) --- 基础类(下)
[源码解析]PyTorch如何实现前向传播(2) --- 基础类(下) 目录 [源码解析]PyTorch如何实现前向传播(2) --- 基础类(下) 0x00 摘要 0x01 前文回顾 0x02 Te ...
- [源码解析] PyTorch如何实现前向传播(3) --- 具体实现
[源码解析] PyTorch如何实现前向传播(3) --- 具体实现 目录 [源码解析] PyTorch如何实现前向传播(3) --- 具体实现 0x00 摘要 0x01 计算图 1.1 图的相关类 ...
- 线性回归-Fork
线性回归 主要内容包括: 线性回归的基本要素 线性回归模型从零开始的实现 线性回归模型使用pytorch的简洁实现 线性回归的基本要素 模型 为了简单起见,这里我们假设价格只取决于房屋状况的两个因 ...
- L1线性回归
线性回归 主要内容包括: 线性回归的基本要素 线性回归模型从零开始的实现 线性回归模型使用pytorch的简洁实现 代码下载地址 https://download.csdn.net/download/ ...
- 空间金字塔池化(Spatial Pyramid Pooling, SPP)原理和代码实现(Pytorch)
想直接看公式的可跳至第三节 3.公式修正 一.为什么需要SPP 首先需要知道为什么会需要SPP. 我们都知道卷积神经网络(CNN)由卷积层和全连接层组成,其中卷积层对于输入数据的大小并没有要求,唯一对 ...
- PyTorch-Adam优化算法原理,公式,应用
概念:Adam 是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重.Adam 最开始是由 OpenAI 的 Diederik Kingma 和多伦多大学的 Jim ...
随机推荐
- 02.从0实现一个JVM语言之词法分析器-Lexer-03月02日更新
从0实现JVM语言之词法分析器-Lexer 本次有较大幅度更新, 老读者如果对前面的一些bug, 错误有疑问可以复盘或者留言. 源码github仓库, 如果这个系列文章对你有帮助, 希望获得你的一个s ...
- 10万级etl调度软件Taskctl-web版免费授权及产品功能特性
转: 10万级etl调度软件Taskctl-web版免费授权及产品功能特性 初识Taskctl-Web版 Taskctl Free应用版原型是在原有商用版Taskctl 6.0衍生扩展开发出的专门为批 ...
- Shell脚本控制docker容器启动顺序
1.遇到的问题 在分布式项目部署的过程中,经常要求服务器重启之后,应用(包括数据库)能够自动恢复使用.虽然使用docker update --restart=always containerid能够让 ...
- 面试必备——Java多线程与并发(二)
1.synchroized相关(锁的是对象,不是代码) (1)线程安全问题的主要原因 存在共享数据(也称临界资源) 存在多线程共同操作这些共享数据 解决:同一时刻有且只有一个线程在操作共享数据,其他线 ...
- solr 远程代码执行(CVE-2019-12409)
Apache Solr 远程代码执行漏洞(CVE-2019-12409) 简介 Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口.是apache的顶级开源项 ...
- 从零学脚手架(三)---webpack属性详解
如果此篇对您有所帮助,在此求一个star.项目地址: OrcasTeam/my-cli 在上一篇中,介绍了webpack的entry.output.plugins属性. 在这一篇,接着介绍其它配置属性 ...
- PHP配置 4. 虚拟主机配置open_basedir
将/usr/local/php/etc/php.ini中open_basedir注释掉,编辑虚拟主机配置open_basedir #vim /usr/local/apache2 .4/conf/ext ...
- addEventListener的第三个参数详解
示例代码 element.addEventListener("mousedown", func, { passive: true }); element.addEventList ...
- [HDU5592] ZYB's Premutation
[HDU5592] ZYB's Premutation 题目大意:一个由\([1,n]\)组成的数列,但不知道具体排列,但给出每个前缀的逆序对数目,让你还原排列 Solution 创造一颗\([1,n ...
- 「CTSC 2013」组合子逻辑
Tag 堆,贪心 Description 给出一个数列 \(n\) 个数,一开始有一个括号包含 \([1,n]\),你需要加一些括号,使得每个括号(包括一开始的)所包含的元素个数 \(\leq\) 这 ...